MoreHopQA: More Than Multi-hop Reasoning

0

Sign in to get full access
Overview
• The provided paper, titled "MoreHopQA: More Than Multi-hop Reasoning," introduces a new multi-hop question answering (QA) dataset and associated challenge.
• Multi-hop QA requires models to combine information from multiple passages to answer a given question, going beyond single-hop reasoning.
• The authors argue that existing multi-hop QA datasets have limitations, and they introduce MoreHopQA to address these shortcomings.
Plain English Explanation
• MoreHopQA: More Than Multi-hop Reasoning is a research paper that describes a new dataset for testing question-answering systems that need to combine information from multiple sources.
• Answering many real-world questions requires piecing together facts from different places, not just finding a single piece of information. This is known as "multi-hop reasoning."
• The authors felt that existing multi-hop QA datasets had some issues, so they created a new dataset called MoreHopQA to better evaluate these types of reasoning abilities.
• MoreHopQA contains questions that require combining information in more complex ways than previous datasets, making it a more challenging benchmark for multi-hop QA models.
Technical Explanation
• The paper introduces the MoreHopQA dataset, which contains over 30,000 multi-hop QA examples across a variety of domains.
• MoreHopQA questions require models to reason over multiple passages of text, combining information in ways that go beyond the capabilities of existing multi-hop QA datasets like HotpotQA and WikiHop.
• The dataset includes examples that require identifying relevant entities and relations, aggregating evidence across multiple documents, and [reasoning about complex multi-modal inputs.
• The authors benchmark several state-of-the-art multi-hop QA models on the MoreHopQA dataset and find that even the best-performing models struggle to achieve high accuracy, demonstrating the increased complexity and challenge of this new benchmark.
Critical Analysis
• While MoreHopQA represents an important step forward in multi-hop QA research, the authors acknowledge that the dataset is still limited in scope and scale compared to real-world question-answering needs.
• The dataset focuses on specific reasoning patterns and may not fully capture the breadth of skills required for open-ended multi-hop reasoning in practice.
• Additionally, the current best-performing models on MoreHopQA still have significant room for improvement, suggesting the need for further advancements in multi-hop reasoning capabilities.
• Future work could explore ways to make MoreHopQA even more challenging, such as incorporating more diverse data sources or requiring models to reason about temporal and causal relationships.
Conclusion
• The MoreHopQA dataset represents an important contribution to the field of multi-hop question answering, pushing the boundaries of what current models can achieve.
• By introducing more complex reasoning patterns, MoreHopQA serves as a valuable benchmark for evaluating and advancing the state-of-the-art in multi-hop QA systems.
• As the research community continues to work towards more robust and capable multi-hop reasoning models, datasets like MoreHopQA will play a crucial role in driving progress and ensuring that AI systems can handle the nuanced, multi-faceted nature of real-world information processing and decision-making tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MoreHopQA: More Than Multi-hop Reasoning
Julian Schnitzler, Xanh Ho, Jiahao Huang, Florian Boudin, Saku Sugawara, Akiko Aizawa
Most existing multi-hop datasets are extractive answer datasets, where the answers to the questions can be extracted directly from the provided context. This often leads models to use heuristics or shortcuts instead of performing true multi-hop reasoning. In this paper, we propose a new multi-hop dataset, MoreHopQA, which shifts from extractive to generative answers. Our dataset is created by utilizing three existing multi-hop datasets: HotpotQA, 2WikiMultihopQA, and MuSiQue. Instead of relying solely on factual reasoning, we enhance the existing multi-hop questions by adding another layer of questioning that involves one, two, or all three of the following types of reasoning: commonsense, arithmetic, and symbolic. Our dataset is created through a semi-automated process, resulting in a dataset with 1,118 samples that have undergone human verification. We then use our dataset to evaluate five different large language models: Mistral 7B, Gemma 7B, Llama 3 (8B and 70B), and GPT-4. We also design various cases to analyze the reasoning steps in the question-answering process. Our results show that models perform well on initial multi-hop questions but struggle with our extended questions, indicating that our dataset is more challenging than previous ones. Our analysis of question decomposition reveals that although models can correctly answer questions, only a portion - 38.7% for GPT-4 and 33.4% for Llama3-70B - achieve perfect reasoning, where all corresponding sub-questions are answered correctly. Evaluation code and data are available at https://github.com/Alab-NII/morehopqa
Read more6/21/2024
🛠️
0
Multi-hop Question Answering
Vaibhav Mavi (New York University, United States of America), Anubhav Jangra (Indian Institute of Technology, Patna, India), Adam Jatowt (University of Innsbruck, Austria)
The task of Question Answering (QA) has attracted significant research interest for long. Its relevance to language understanding and knowledge retrieval tasks, along with the simple setting makes the task of QA crucial for strong AI systems. Recent success on simple QA tasks has shifted the focus to more complex settings. Among these, Multi-Hop QA (MHQA) is one of the most researched tasks over the recent years. In broad terms, MHQA is the task of answering natural language questions that involve extracting and combining multiple pieces of information and doing multiple steps of reasoning. An example of a multi-hop question would be The Argentine PGA Championship record holder has won how many tournaments worldwide?. Answering the question would need two pieces of information: Who is the record holder for Argentine PGA Championship tournaments? and How many tournaments did [Answer of Sub Q1] win?. The ability to answer multi-hop questions and perform multi step reasoning can significantly improve the utility of NLP systems. Consequently, the field has seen a surge with high quality datasets, models and evaluation strategies. The notion of 'multiple hops' is somewhat abstract which results in a large variety of tasks that require multi-hop reasoning. This leads to different datasets and models that differ significantly from each other and makes the field challenging to generalize and survey. We aim to provide a general and formal definition of the MHQA task, and organize and summarize existing MHQA frameworks. We also outline some best practices for building MHQA datasets. This book provides a systematic and thorough introduction as well as the structuring of the existing attempts to this highly interesting, yet quite challenging task.
Read more6/3/2024
💬
0
Towards Robust Temporal Reasoning of Large Language Models via a Multi-Hop QA Dataset and Pseudo-Instruction Tuning
Qingyu Tan, Hwee Tou Ng, Lidong Bing
Knowledge in the real world is being updated constantly. However, it is costly to frequently update large language models (LLMs). Therefore, it is crucial for LLMs to understand the concept of temporal knowledge. However, prior works on temporal question answering (TQA) did not emphasize multi-answer and multi-hop types of temporal reasoning. In this paper, we propose a complex temporal question-answering dataset Complex-TR that focuses on multi-answer and multi-hop temporal reasoning. Besides, we also propose a novel data augmentation strategy to improve the complex temporal reasoning capability and robustness of LLMs. We conducted experiments on multiple temporal QA datasets. Experimental results show that our method is able to improve LLMs' performance on temporal QA benchmarks by significant margins. Our code and data are released at: https://github.com/nusnlp/complex-tr.
Read more7/15/2024
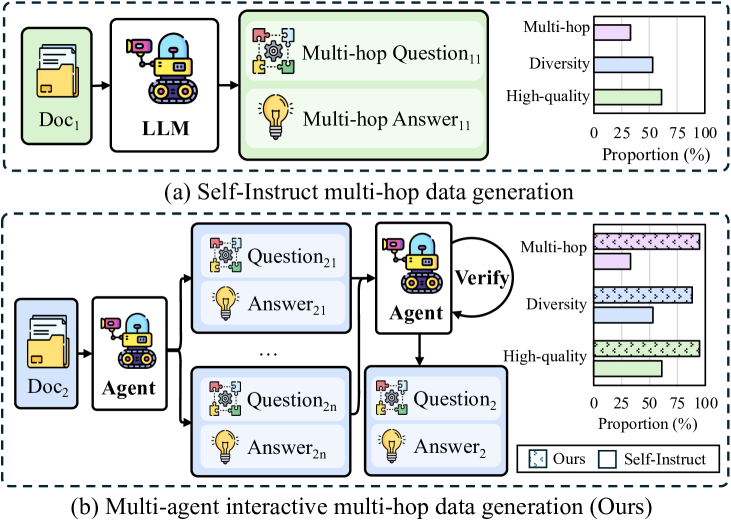
0
What are the Essential Factors in Crafting Effective Long Context Multi-Hop Instruction Datasets? Insights and Best Practices
Zhi Chen, Qiguang Chen, Libo Qin, Qipeng Guo, Haijun Lv, Yicheng Zou, Wanxiang Che, Hang Yan, Kai Chen, Dahua Lin
Recent advancements in large language models (LLMs) with extended context windows have significantly improved tasks such as information extraction, question answering, and complex planning scenarios. In order to achieve success in long context tasks, a large amount of work has been done to enhance the long context capabilities of the model through synthetic data. Existing methods typically utilize the Self-Instruct framework to generate instruction tuning data for better long context capability improvement. However, our preliminary experiments indicate that less than 35% of generated samples are multi-hop, and more than 40% exhibit poor quality, limiting comprehensive understanding and further research. To improve the quality of synthetic data, we propose the Multi-agent Interactive Multi-hop Generation (MIMG) framework, incorporating a Quality Verification Agent, a Single-hop Question Generation Agent, a Multiple Question Sampling Strategy, and a Multi-hop Question Merger Agent. This framework improves the data quality, with the proportion of high-quality, multi-hop, and diverse data exceeding 85%. Furthermore, we systematically investigate strategies for document selection, question merging, and validation techniques through extensive experiments across various models. Our findings show that our synthetic high-quality long-context instruction data significantly enhances model performance, even surpassing models trained on larger amounts of human-annotated data. Our code is available at: https://github.com/WowCZ/LongMIT.
Read more9/4/2024