What if...?: Thinking Counterfactual Keywords Helps to Mitigate Hallucination in Large Multi-modal Models

0

Sign in to get full access
Overview
- This paper explores the use of counterfactual thinking to mitigate hallucination effects in large multimodal models, which are AI systems that can process and generate text, images, and other media.
- Hallucination refers to the tendency of these models to generate plausible-sounding but factually incorrect information, which can be problematic in high-stakes applications.
- The authors propose a novel "Counterfactual Inception" approach that encourages the model to consider alternative scenarios and outcomes, helping it avoid hallucination.
Plain English Explanation
Counterfactual thinking is the process of imagining "what if" scenarios - how things could have turned out differently. The authors of this paper suggest that encouraging large AI models to engage in counterfactual thinking can help reduce the problem of hallucination, where the models generate plausible-sounding but factually incorrect information.
Imagine you're trying to get a weather forecast from an AI assistant. If the assistant simply regurgitates information it has been trained on, it might confidently tell you it's going to rain, even if that's not actually the case. This kind of hallucination can be problematic, especially in high-stakes domains like healthcare or finance.
The researchers propose a technique called "Counterfactual Inception" that pushes the AI model to consider alternative scenarios and outcomes. For example, instead of just predicting the weather, the model might also think about what would happen if certain conditions were different. This counterfactual reasoning can help the model become more grounded in reality and less prone to hallucination.
By encouraging the model to engage in this type of "what if" thinking, the researchers hope to develop AI systems that are more reliable, trustworthy, and aligned with human values. This is an important step towards making these powerful technologies safer and more beneficial for society.
Technical Explanation
The paper introduces a novel "Counterfactual Inception" (CFI) approach to mitigate hallucination effects in large multimodal models. Hallucination refers to the tendency of these models to generate plausible-sounding but factually incorrect information, which can be problematic in high-stakes applications.
The CFI approach encourages the model to consider counterfactual scenarios and outcomes during training. This is achieved by introducing a series of "what if" prompts that ask the model to imagine alternative situations and their consequences. For example, the model might be asked, "What if the weather forecast was different?" or "What if the image showed a different object?"
By engaging in this counterfactual thinking, the model is forced to explore a wider range of possibilities and consider the implications of its outputs. This, in turn, helps the model become more grounded in reality and less prone to hallucination.
The authors evaluate their approach on several benchmarks, including MedThink, a medical visual-language task, and TVQA, a video question-answering dataset. The results demonstrate that the CFI approach significantly improves the model's performance compared to standard training methods, particularly in terms of reducing hallucination.
Critical Analysis
The authors provide a compelling case for the importance of mitigating hallucination effects in large multimodal models. Hallucination can have serious consequences in high-stakes applications, and the proposed Counterfactual Inception approach represents an innovative step towards addressing this issue.
One potential limitation of the study is the scope of the evaluation, which focuses primarily on specific benchmarks. It would be valuable to see how the CFI approach performs on a wider range of tasks and datasets, including real-world applications, to better understand its broader applicability and generalizability.
Additionally, the paper does not delve deeply into the underlying mechanisms by which counterfactual thinking helps reduce hallucination. Further research could explore the cognitive and neurological processes involved, potentially leading to even more effective mitigation strategies.
Another area for further exploration is the interplay between counterfactual thinking and other techniques for improving model reliability, such as interactive analysis or preset stance elimination. Combining multiple approaches may yield even more robust and trustworthy AI systems.
Conclusion
This paper presents a promising approach to mitigating hallucination effects in large multimodal models by encouraging counterfactual thinking. By prompting the model to consider "what if" scenarios and their implications, the Counterfactual Inception technique helps the model become more grounded in reality and less prone to generating factually incorrect information.
The authors' work highlights the importance of developing AI systems that are not only capable, but also reliable and trustworthy. As these technologies become increasingly ubiquitous, it is crucial that we address issues like hallucination to ensure they are aligned with human values and can be safely deployed in high-stakes applications.
This research represents an important step towards building a future where AI is a robust and beneficial tool, empowering us to make more informed decisions and tackle complex challenges with confidence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
What if...?: Thinking Counterfactual Keywords Helps to Mitigate Hallucination in Large Multi-modal Models
Junho Kim, Yeon Ju Kim, Yong Man Ro
This paper presents a way of enhancing the reliability of Large Multi-modal Models (LMMs) in addressing hallucination, where the models generate cross-modal inconsistent responses. Without additional training, we propose Counterfactual Inception, a novel method that implants counterfactual thinking into LMMs using self-generated counterfactual keywords. Our method is grounded in the concept of counterfactual thinking, a cognitive process where human considers alternative realities, enabling more extensive context exploration. Bridging the human cognition mechanism into LMMs, we aim for the models to engage with and generate responses that span a wider contextual scene understanding, mitigating hallucinatory outputs. We further introduce Plausibility Verification Process (PVP), a simple yet robust keyword constraint that effectively filters out sub-optimal keywords to enable the consistent triggering of counterfactual thinking in the model responses. Comprehensive analyses across various LMMs, including both open-source and proprietary models, corroborate that counterfactual thinking significantly reduces hallucination and helps to broaden contextual understanding based on true visual clues.
Read more6/24/2024
0
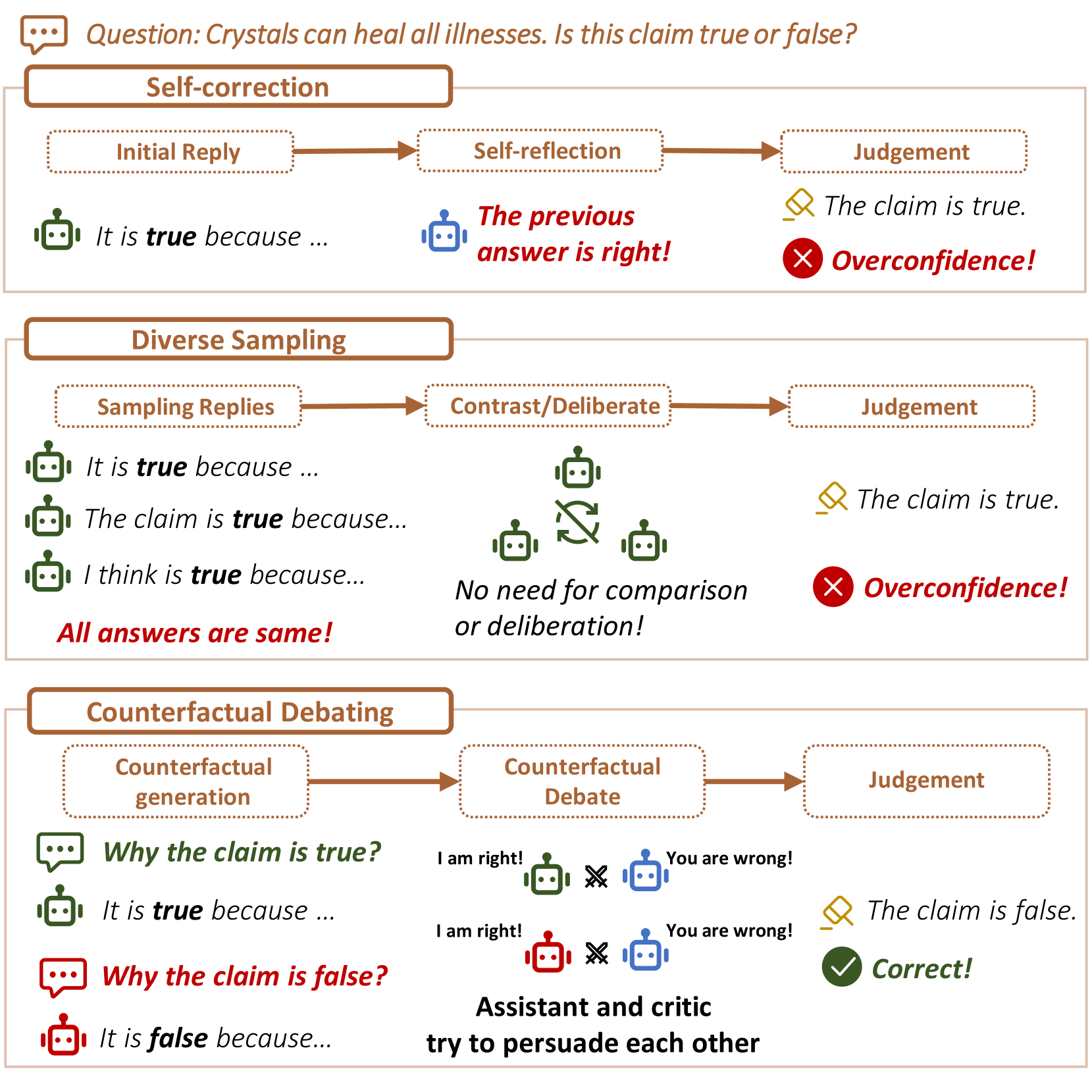
Counterfactual Debating with Preset Stances for Hallucination Elimination of LLMs
Yi Fang, Moxin Li, Wenjie Wang, Hui Lin, Fuli Feng
Large Language Models (LLMs) excel in various natural language processing tasks but struggle with hallucination issues. Existing solutions have considered utilizing LLMs' inherent reasoning abilities to alleviate hallucination, such as self-correction and diverse sampling methods. However, these methods often overtrust LLMs' initial answers due to inherent biases. The key to alleviating this issue lies in overriding LLMs' inherent biases for answer inspection. To this end, we propose a CounterFactual Multi-Agent Debate (CFMAD) framework. CFMAD presets the stances of LLMs to override their inherent biases by compelling LLMs to generate justifications for a predetermined answer's correctness. The LLMs with different predetermined stances are engaged with a skeptical critic for counterfactual debate on the rationality of generated justifications. Finally, the debate process is evaluated by a third-party judge to determine the final answer. Extensive experiments on four datasets of three tasks demonstrate the superiority of CFMAD over existing methods.
Read more6/18/2024
0
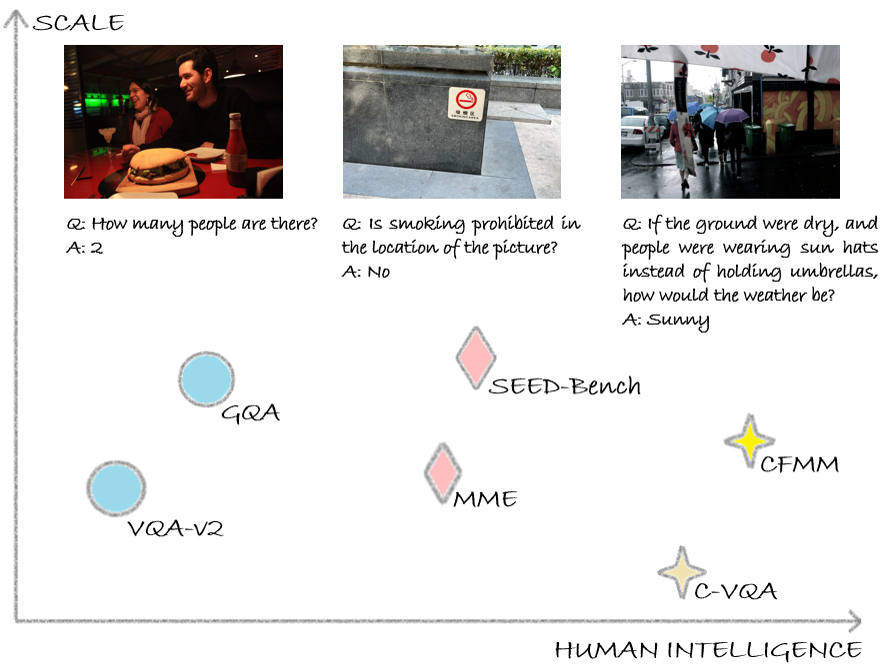
Eyes Can Deceive: Benchmarking Counterfactual Reasoning Abilities of Multi-modal Large Language Models
Yian Li, Wentao Tian, Yang Jiao, Jingjing Chen
Counterfactual reasoning, as a crucial manifestation of human intelligence, refers to making presuppositions based on established facts and extrapolating potential outcomes. Existing multimodal large language models (MLLMs) have exhibited impressive cognitive and reasoning capabilities, which have been examined across a wide range of Visual Question Answering (VQA) benchmarks. Nevertheless, how will existing MLLMs perform when faced with counterfactual questions? To answer this question, we first curate a novel textbf{C}ountertextbf{F}actual textbf{M}ultitextbf{M}odal reasoning benchmark, abbreviated as textbf{CFMM}, to systematically assess the counterfactual reasoning capabilities of MLLMs. Our CFMM comprises six challenging tasks, each including hundreds of carefully human-labeled and GPT-generated counterfactual questions, to evaluate MLLM's counterfactual reasoning capabilities across diverse aspects. Through experiments, interestingly, we find that existing MLLMs prefer to believe what they see, but ignore the counterfactual presuppositions presented in the question, thereby leading to inaccurate responses. Furthermore, we evaluate a wide range of prevalent MLLMs on our proposed CFMM. The significant gap between their performance on our CFMM and that on several VQA benchmarks indicates that there is still considerable room for improvement in existing MLLMs toward approaching human-level intelligence. On the other hand, through boosting MLLMs performances on our CFMM in the future, potential avenues toward developing MLLMs with advanced intelligence can be explored.
Read more9/2/2024
💬
0
What If the TV Was Off? Examining Counterfactual Reasoning Abilities of Multi-modal Language Models
Letian Zhang, Xiaotong Zhai, Zhongkai Zhao, Yongshuo Zong, Xin Wen, Bingchen Zhao
Counterfactual reasoning, a fundamental aspect of human cognition, involves contemplating alternatives to established facts or past events, significantly enhancing our abilities in planning and decision-making. In light of the advancements in current multi-modal large language models, we explore their effectiveness in counterfactual reasoning. To facilitate this investigation, we introduce a novel dataset, C-VQA, specifically designed to test the counterfactual reasoning capabilities of modern multi-modal large language models. This dataset is constructed by infusing original questions with counterfactual presuppositions, spanning various types such as numerical and boolean queries. It encompasses a mix of real and synthetic data, representing a wide range of difficulty levels. Our thorough evaluations of contemporary vision-language models using this dataset have revealed substantial performance drops, with some models showing up to a 40% decrease, highlighting a significant gap between current models and human-like vision reasoning capabilities. We hope our dataset will serve as a vital benchmark for evaluating the counterfactual reasoning capabilities of models. Code and dataset are publicly available at https://bzhao.me/C-VQA/.
Read more4/17/2024