What You Say = What You Want? Teaching Humans to Articulate Requirements for LLMs

0

Sign in to get full access
Overview
- Provides a plain English summary of a research paper on teaching humans to articulate requirements for large language models (LLMs).
- Covers the key ideas, technical details, and critical analysis of the paper in a clear and accessible way.
- Includes internal links for SEO purposes where appropriate.
Plain English Explanation
This paper explores how to help people better communicate their needs and goals when working with large language models (LLMs) like ChatGPT. LLMs are powerful AI systems that can understand and generate human-like text, but they rely on the prompts (instructions) provided by users to know what to do.
The researchers found that many people struggle to effectively communicate their requirements to LLMs, leading to outputs that don't match their intended goals. To address this, the paper proposes teaching "requirement engineering" - techniques for clearly defining and articulating the desired capabilities, constraints, and outcomes when working with LLMs.
The goal is to empower end-users to take control of LLM interactions and get the results they want, rather than relying on trial-and-error. This could make LLMs more accessible and useful for a wider range of people and applications.
Technical Explanation
The paper first reviews related work on prompt engineering and requirement gathering for AI systems. It then proposes a novel "requirement articulation" framework that guides users through a structured process to define their goals, constraints, and success criteria for an LLM task.
This framework was evaluated through a series of experiments where participants used the requirement articulation approach to interact with an LLM, and their outputs were compared to a control group. The results showed that the requirement-based approach led to significantly better outcomes that more closely matched the users' original intents.
The paper also discusses limitations of the current work, such as the need for more diverse testing scenarios and the challenge of scaling requirement articulation to complex, open-ended prompts.
Critical Analysis
The research presented in this paper takes an important step towards empowering end-users to effectively leverage the capabilities of large language models. By teaching "requirement engineering" principles, the approach aims to help people clearly communicate their needs and goals, rather than relying on trial-and-error prompting.
However, some potential issues are worth noting. The experiments were conducted in somewhat constrained scenarios, so further research is needed to understand how the requirement articulation framework scales to more open-ended, real-world use cases. There's also the question of how to balance the structure of the requirement process with the flexibility and creativity that many users value when interacting with LLMs.
Additionally, the paper does not deeply explore potential biases or ethical considerations that may arise when users are guided to articulate their requirements in a particular way. These are important factors to consider as this type of technology becomes more widely adopted.
Overall, this research represents a valuable contribution to the field of prompt engineering and user experience for large language models. By empowering users to better communicate their needs, it has the potential to make these powerful AI systems more accessible and useful for a wide range of applications.
Conclusion
This paper presents a novel approach to helping end-users effectively articulate their requirements when working with large language models. By teaching "requirement engineering" techniques, the researchers aim to enable users to clearly communicate their goals, constraints, and success criteria, leading to LLM outputs that better match their intended needs.
The experimental results are promising, showing that the requirement-based approach can significantly improve the alignment between user intent and model output. While the current work has some limitations, it represents an important step towards making LLMs more accessible and controllable for a wider range of users and applications.
As large language models continue to advance and become more ubiquitous, approaches like the one described in this paper will be crucial for ensuring that these powerful AI systems can be effectively leveraged to solve real-world problems. By empowering end-users to take an active role in defining their requirements, the research has the potential to unlock new possibilities for human-AI collaboration.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
What You Say = What You Want? Teaching Humans to Articulate Requirements for LLMs
Qianou Ma, Weirui Peng, Hua Shen, Kenneth Koedinger, Tongshuang Wu
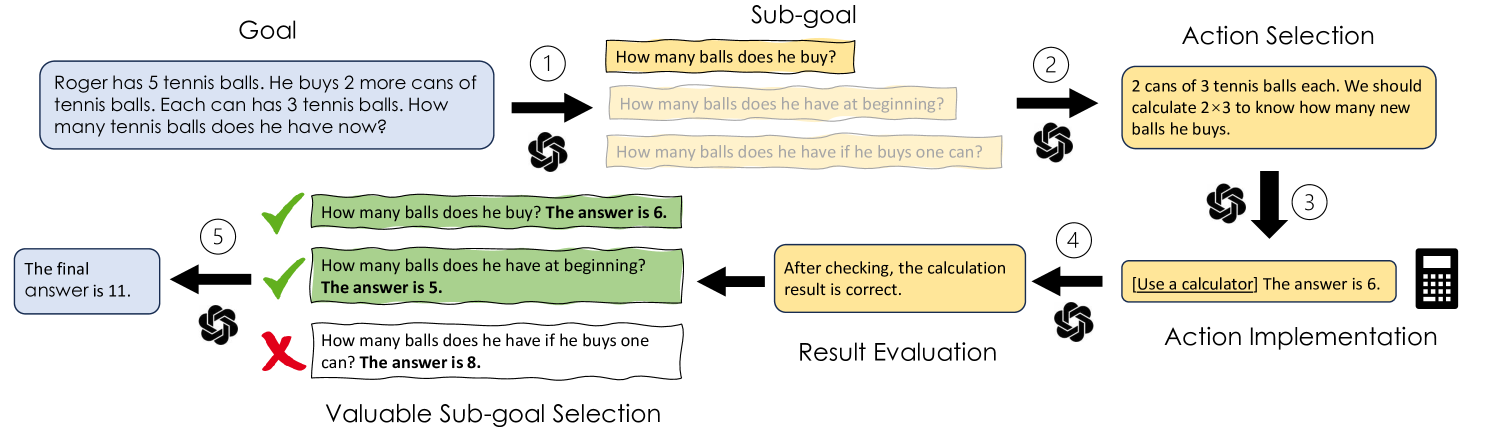
Prompting ChatGPT to achieve complex goals (e.g., creating a customer support chatbot) often demands meticulous prompt engineering, including aspects like fluent writing and chain-of-thought techniques. While emerging prompt optimizers can automatically refine many of these aspects, we argue that clearly conveying customized requirements (e.g., how to handle diverse inputs) remains a human-centric challenge. In this work, we introduce Requirement-Oriented Prompt Engineering (ROPE), a paradigm that focuses human attention on generating clear, complete requirements during prompting. We implement ROPE through an assessment and training suite that provides deliberate practice with LLM-generated feedback. In a study with 30 novices, we show that requirement-focused training doubles novices' prompting performance, significantly outperforming conventional prompt engineering training and prompt optimization. We also demonstrate that high-quality LLM outputs are directly tied to the quality of input requirements. Our work paves the way for more effective task delegation in human-LLM collaborative prompting.
Read more9/16/2024
0
Towards Goal-oriented Prompt Engineering for Large Language Models: A Survey
Haochen Li, Jonathan Leung, Zhiqi Shen
Large Language Models (LLMs) have shown prominent performance in various downstream tasks and prompt engineering plays a pivotal role in optimizing LLMs' performance. This paper, not only as an overview of current prompt engineering methods, but also aims to highlight the limitation of designing prompts based on an anthropomorphic assumption that expects LLMs to think like humans. From our review of 50 representative studies, we demonstrate that a goal-oriented prompt formulation, which guides LLMs to follow established human logical thinking, significantly improves the performance of LLMs. Furthermore, We introduce a novel taxonomy that categorizes goal-oriented prompting methods into five interconnected stages and we demonstrate the broad applicability of our framework. With four future directions proposed, we hope to further emphasize the power and potential of goal-oriented prompt engineering in all fields.
Read more9/18/2024
🏅
0
PRewrite: Prompt Rewriting with Reinforcement Learning
Weize Kong, Spurthi Amba Hombaiah, Mingyang Zhang, Qiaozhu Mei, Michael Bendersky
Prompt engineering is critical for the development of LLM-based applications. However, it is usually done manually in a trial and error fashion that can be time consuming, ineffective, and sub-optimal. Even for the prompts which seemingly work well, there is always a lingering question: can the prompts be made better with further modifications? To address these problems, we investigate automated prompt engineering in this paper. Specifically, we propose PRewrite, an automated method to rewrite an under-optimized prompt to a more effective prompt. We instantiate the prompt rewriter using a LLM. The rewriter LLM is trained using reinforcement learning to optimize the performance on a given downstream task. We conduct experiments on diverse benchmark datasets, which demonstrates the effectiveness of PRewrite.
Read more6/11/2024

0
Improving Ontology Requirements Engineering with OntoChat and Participatory Prompting
Yihang Zhao, Bohui Zhang, Xi Hu, Shuyin Ouyang, Jongmo Kim, Nitisha Jain, Jacopo de Berardinis, Albert Mero~no-Pe~nuela, Elena Simperl
Past ontology requirements engineering (ORE) has primarily relied on manual methods, such as interviews and collaborative forums, to gather user requirements from domain experts, especially in large projects. Current OntoChat offers a framework for ORE that utilises large language models (LLMs) to streamline the process through four key functions: user story creation, competency question (CQ) extraction, CQ filtration and analysis, and ontology testing support. In OntoChat, users are expected to prompt the chatbot to generate user stories. However, preliminary evaluations revealed that they struggle to do this effectively. To address this issue, we experimented with a research method called participatory prompting, which involves researcher-mediated interactions to help users without deep knowledge of LLMs use the chatbot more effectively. This participatory prompting user study produces pre-defined prompt templates based on user queries, focusing on creating and refining personas, goals, scenarios, sample data, and data resources for user stories. These refined user stories will subsequently be converted into CQs.
Read more9/19/2024