When Benchmarks are Targets: Revealing the Sensitivity of Large Language Model Leaderboards

1

Sign in to get full access
Overview
- This paper examines the sensitivity of large language model (LLM) leaderboards to targeted attempts at optimizing for benchmark performance.
- The researchers use multiple-choice questions (MCQs) to evaluate LLM performance and find that models can be fine-tuned to exploit biases in the MCQ datasets, leading to inflated leaderboard scores.
- The paper highlights the risks of relying on leaderboard performance as the primary metric for LLM evaluation and suggests the need for more robust and diverse benchmarking approaches.
Plain English Explanation
Large language models (LLMs) have become increasingly important in natural language processing, with their performance on benchmark tasks often used to measure their capabilities. However, this paper suggests that these benchmarks may be too easy to "game," leading to inflated scores that don't accurately reflect the true capabilities of the models.
The researchers used multiple-choice questions (MCQs) to evaluate LLM performance, as these types of questions are commonly used in benchmark tasks. They found that models could be fine-tuned to exploit biases in the MCQ datasets, allowing them to achieve high scores without necessarily demonstrating a deep understanding of the material.
This finding raises concerns about the reliability of leaderboard rankings, which are often used to compare the performance of different LLMs. If models can be optimized for specific benchmarks, the leaderboard scores may not provide an accurate representation of their general language understanding abilities.
The paper suggests that the research community needs to develop more robust and diverse benchmarking approaches to better evaluate the true capabilities of LLMs. This could involve using a wider range of tasks and datasets, as well as incorporating more challenging and nuanced evaluation methods.
By addressing these issues, the researchers hope to improve the way we assess and compare the performance of large language models, ultimately leading to the development of more capable and reliable systems.
Technical Explanation
The paper investigates the sensitivity of large language model (LLM) leaderboards to targeted optimization for benchmark performance. The researchers use multiple-choice questions (MCQs) as the evaluation task, as MCQs are commonly used in benchmark tasks for LLMs.
The key findings of the paper are:
-
Leaderboard Sensitivity: The researchers demonstrate that LLMs can be fine-tuned to exploit biases in MCQ datasets, leading to inflated leaderboard scores that do not necessarily reflect the models' true language understanding capabilities.
-
Benchmark Exploitation: By fine-tuning LLMs on specific MCQ datasets, the researchers were able to achieve substantial performance improvements on those benchmarks, without corresponding improvements on other, more diverse evaluation tasks.
-
Limitations of Leaderboards: The paper highlights the risks of relying solely on leaderboard performance as the primary metric for LLM evaluation, as it can incentivize model developers to focus on optimizing for specific benchmarks rather than developing more robust and generalizable language understanding capabilities.
To conduct their experiments, the researchers used a diverse set of MCQ datasets, including RACE, QASC, and ARTS. They fine-tuned several prominent LLMs, such as GPT-3, T5, and PALM, on these datasets and evaluated their performance on both the fine-tuned benchmarks and a broader set of language understanding tasks.
The results demonstrate that fine-tuning can lead to significant leaderboard score improvements, but these gains do not necessarily translate to better performance on more diverse and challenging language understanding tasks. This highlights the need for a more comprehensive and nuanced approach to LLM evaluation, one that goes beyond simple leaderboard rankings.
Critical Analysis
The paper provides a valuable contribution to the ongoing discussion around the reliability and robustness of LLM evaluation methodologies. The researchers' findings regarding the sensitivity of benchmark leaderboards to targeted optimization are concerning and raise important questions about the validity of using leaderboard performance as the primary metric for assessing model capabilities.
One potential limitation of the study is the use of MCQ datasets as the sole evaluation task. While MCQs are commonly used in benchmark tasks, they may not capture the full range of language understanding skills required for real-world applications. It would be interesting to see the researchers extend their analysis to a broader set of evaluation tasks, such as open-ended language generation, question answering, and commonsense reasoning.
Additionally, the paper does not provide a detailed analysis of the specific biases and weaknesses in the MCQ datasets that the models were able to exploit. A deeper examination of these dataset characteristics could help the research community develop more robust and diverse benchmarking approaches that are less susceptible to targeted optimization.
Despite these potential limitations, the paper makes a strong case for the need to rethink the way we evaluate and compare the performance of large language models. The researchers' findings suggest that the research community should strive to develop more nuanced and comprehensive evaluation methodologies that better capture the true capabilities of these powerful systems.
Conclusion
This paper highlights a significant challenge in the evaluation of large language models: the sensitivity of benchmark leaderboards to targeted optimization. The researchers demonstrate that LLMs can be fine-tuned to exploit biases in multiple-choice question (MCQ) datasets, leading to inflated leaderboard scores that do not necessarily reflect the models' true language understanding capabilities.
The paper's findings underscore the need for the research community to develop more robust and diverse benchmarking approaches that go beyond simple leaderboard rankings. By incorporating a wider range of evaluation tasks and focusing on more nuanced and challenging measures of language understanding, the community can work towards building LLMs that are genuinely capable of tackling real-world language processing challenges.
As the field of natural language processing continues to advance, the issues raised in this paper will become increasingly important to address. By acknowledging the limitations of current evaluation methods and striving for more comprehensive and reliable benchmarking, the research community can ensure that the progress in large language models translates to tangible and trustworthy improvements in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
1
When Benchmarks are Targets: Revealing the Sensitivity of Large Language Model Leaderboards
Norah Alzahrani, Hisham Abdullah Alyahya, Yazeed Alnumay, Sultan Alrashed, Shaykhah Alsubaie, Yusef Almushaykeh, Faisal Mirza, Nouf Alotaibi, Nora Altwairesh, Areeb Alowisheq, M Saiful Bari, Haidar Khan
Large Language Model (LLM) leaderboards based on benchmark rankings are regularly used to guide practitioners in model selection. Often, the published leaderboard rankings are taken at face value - we show this is a (potentially costly) mistake. Under existing leaderboards, the relative performance of LLMs is highly sensitive to (often minute) details. We show that for popular multiple-choice question benchmarks (e.g., MMLU), minor perturbations to the benchmark, such as changing the order of choices or the method of answer selection, result in changes in rankings up to 8 positions. We explain this phenomenon by conducting systematic experiments over three broad categories of benchmark perturbations and identifying the sources of this behavior. Our analysis results in several best-practice recommendations, including the advantage of a hybrid scoring method for answer selection. Our study highlights the dangers of relying on simple benchmark evaluations and charts the path for more robust evaluation schemes on the existing benchmarks. The code for this paper is available at https://github.com/National-Center-for-AI-Saudi-Arabia/lm-evaluation-harness.
Read more7/4/2024
0
tinyBenchmarks: evaluating LLMs with fewer examples
Felipe Maia Polo, Lucas Weber, Leshem Choshen, Yuekai Sun, Gongjun Xu, Mikhail Yurochkin
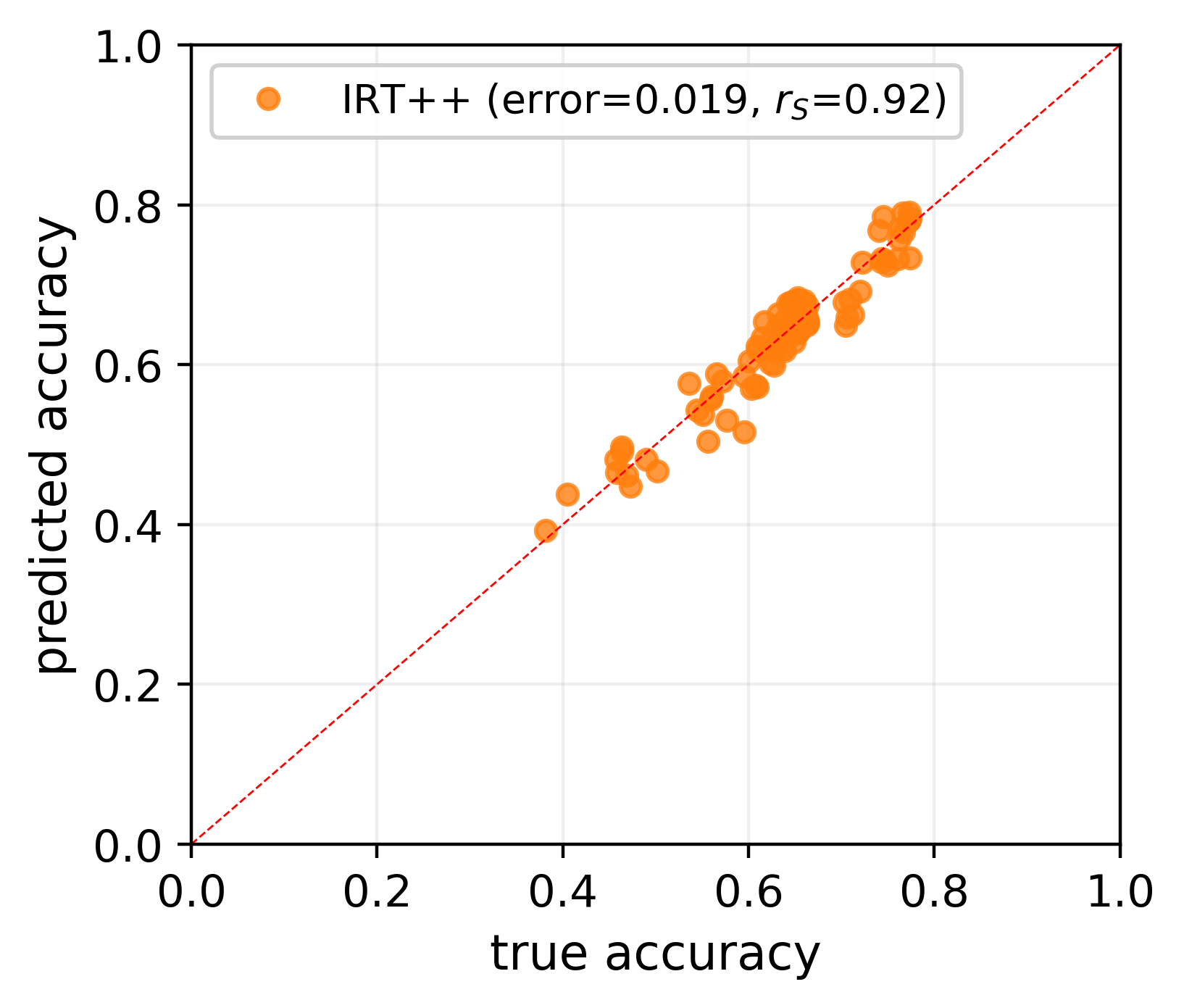
The versatility of large language models (LLMs) led to the creation of diverse benchmarks that thoroughly test a variety of language models' abilities. These benchmarks consist of tens of thousands of examples making evaluation of LLMs very expensive. In this paper, we investigate strategies to reduce the number of evaluations needed to assess the performance of an LLM on several key benchmarks. For example, we show that to accurately estimate the performance of an LLM on MMLU, a popular multiple-choice QA benchmark consisting of 14K examples, it is sufficient to evaluate this LLM on 100 curated examples. We release evaluation tools and tiny versions of popular benchmarks: Open LLM Leaderboard, MMLU, HELM, and AlpacaEval 2.0. Our empirical analysis demonstrates that these tools and tiny benchmarks are sufficient to reliably and efficiently reproduce the original evaluation results.
Read more5/28/2024
💬
1
Benchmarking Benchmark Leakage in Large Language Models
Ruijie Xu, Zengzhi Wang, Run-Ze Fan, Pengfei Liu
Amid the expanding use of pre-training data, the phenomenon of benchmark dataset leakage has become increasingly prominent, exacerbated by opaque training processes and the often undisclosed inclusion of supervised data in contemporary Large Language Models (LLMs). This issue skews benchmark effectiveness and fosters potentially unfair comparisons, impeding the field's healthy development. To address this, we introduce a detection pipeline utilizing Perplexity and N-gram accuracy, two simple and scalable metrics that gauge a model's prediction precision on benchmark, to identify potential data leakages. By analyzing 31 LLMs under the context of mathematical reasoning, we reveal substantial instances of training even test set misuse, resulting in potentially unfair comparisons. These findings prompt us to offer several recommendations regarding model documentation, benchmark setup, and future evaluations. Notably, we propose the Benchmark Transparency Card to encourage clear documentation of benchmark utilization, promoting transparency and healthy developments of LLMs. we have made our leaderboard, pipeline implementation, and model predictions publicly available, fostering future research.
Read more4/30/2024
0
Language Model Council: Benchmarking Foundation Models on Highly Subjective Tasks by Consensus
Justin Zhao, Flor Miriam Plaza-del-Arco, Amanda Cercas Curry
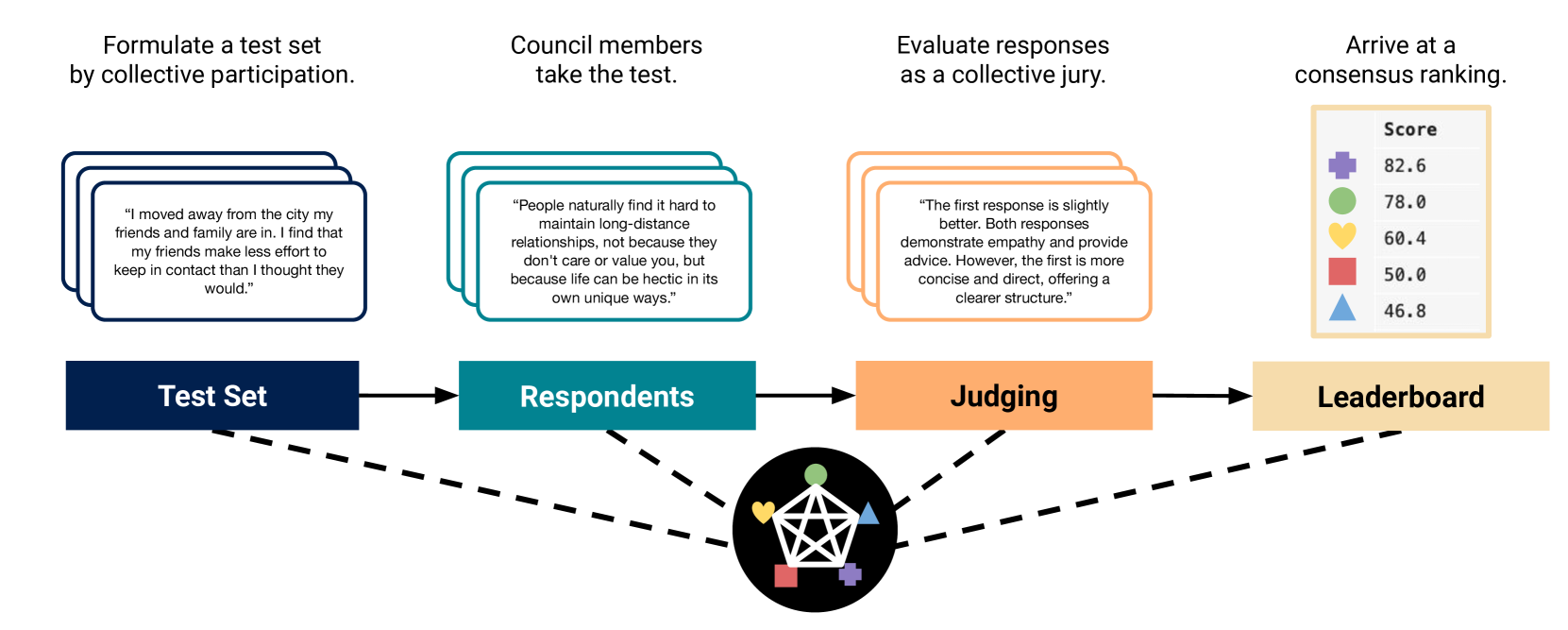
The rapid advancement of Large Language Models (LLMs) necessitates robust and challenging benchmarks. Leaderboards like Chatbot Arena rank LLMs based on how well their responses align with human preferences. However, many tasks such as those related to emotional intelligence, creative writing, or persuasiveness, are highly subjective and often lack majoritarian human agreement. Judges may have irreconcilable disagreements about what constitutes a better response. To address the challenge of ranking LLMs on highly subjective tasks, we propose a novel benchmarking framework, the Language Model Council (LMC). The LMC operates through a democratic process to: 1) formulate a test set through equal participation, 2) administer the test among council members, and 3) evaluate responses as a collective jury. We deploy a council of 20 newest LLMs on an open-ended emotional intelligence task: responding to interpersonal dilemmas. Our results show that the LMC produces rankings that are more separable, robust, and less biased than those from any individual LLM judge, and is more consistent with a human-established leaderboard compared to other benchmarks.
Read more6/14/2024