Language Model Council: Benchmarking Foundation Models on Highly Subjective Tasks by Consensus
2406.08598
0
0
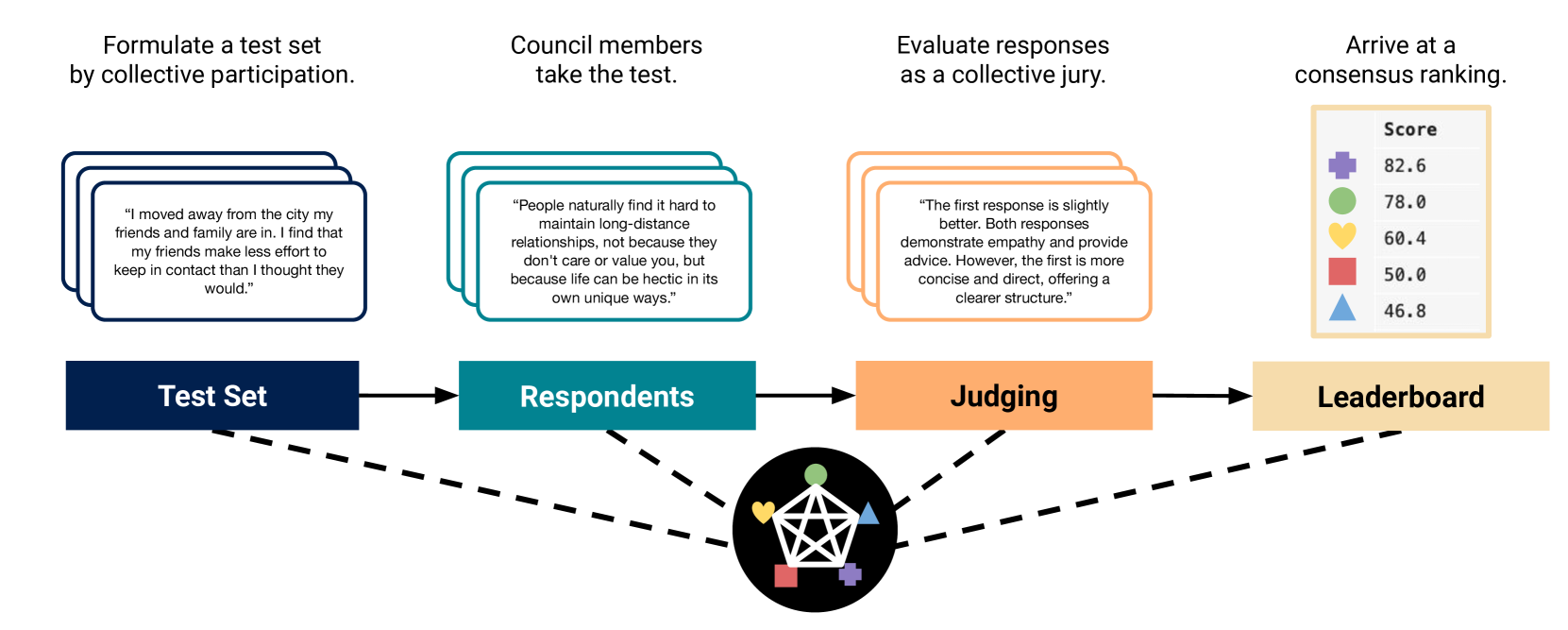
Abstract
The rapid advancement of Large Language Models (LLMs) necessitates robust and challenging benchmarks. Leaderboards like Chatbot Arena rank LLMs based on how well their responses align with human preferences. However, many tasks such as those related to emotional intelligence, creative writing, or persuasiveness, are highly subjective and often lack majoritarian human agreement. Judges may have irreconcilable disagreements about what constitutes a better response. To address the challenge of ranking LLMs on highly subjective tasks, we propose a novel benchmarking framework, the Language Model Council (LMC). The LMC operates through a democratic process to: 1) formulate a test set through equal participation, 2) administer the test among council members, and 3) evaluate responses as a collective jury. We deploy a council of 20 newest LLMs on an open-ended emotional intelligence task: responding to interpersonal dilemmas. Our results show that the LMC produces rankings that are more separable, robust, and less biased than those from any individual LLM judge, and is more consistent with a human-established leaderboard compared to other benchmarks.
Create account to get full access
Overview
- Introduces a novel approach to benchmarking large language models on highly subjective tasks using a "Language Model Council" to reach consensus
- Highlights the challenges of evaluating language models on tasks that involve nuanced human judgment, such as sentiment analysis and creative writing
- Proposes using a diverse panel of human raters to collectively assess model performance, aiming to capture the breadth of subjective perspectives
Plain English Explanation
The paper proposes a new way to evaluate large language models on tasks that require human-like judgment and interpretation, such as assessing the sentiment or creativity of text. Traditional benchmarks often struggle to capture the nuances of these highly subjective tasks, leading to inconsistent or biased results.
To address this, the researchers suggest using a "Language Model Council" - a diverse group of human raters who collectively evaluate the language models. By having multiple people assess the models' outputs, the goal is to reach a more well-rounded and representative consensus on the models' performance. This approach aims to better reflect the range of human perspectives and assessments that these language models would encounter in real-world applications.
The paper highlights the importance of developing more human-centric and inclusive ways to evaluate the capabilities of large language models, especially as they are increasingly deployed in applications that require subjective judgment. By incorporating diverse human perspectives, the researchers hope to create benchmarks that are more representative of real-world use cases and establish a foundation for more comprehensive model evaluation.
Technical Explanation
The paper introduces a novel approach to benchmarking large language models on highly subjective tasks, such as sentiment analysis and creative writing. Recognizing the limitations of traditional benchmarks in capturing the nuances of these tasks, the researchers propose using a "Language Model Council" - a diverse panel of human raters who collectively evaluate the models' performance.
The core idea is to have multiple raters, representing a range of perspectives and backgrounds, independently assess the language models' outputs on subjective tasks. The raters then discuss and debate their assessments, working to reach a consensus on the models' performance. This collaborative approach aims to produce more well-rounded and representative evaluations, as opposed to relying on a single individual's assessment or aggregating multiple individual ratings.
The researchers argue that this method can help address the inconsistencies and biases often observed in language model evaluations, particularly on tasks that involve subjective human judgment. By incorporating a diversity of perspectives, the Language Model Council approach seeks to capture the breadth of possible interpretations and assessments that these models would encounter in real-world applications.
The paper also discusses the potential benefits of this approach for developing more comprehensive and dynamic benchmarks that can better reflect the subjective and social aspects of language use.
Critical Analysis
The paper presents a promising approach to addressing the challenges of evaluating large language models on highly subjective tasks. The use of a diverse Language Model Council to reach a consensus evaluation is an innovative solution that aims to capture a more holistic and representative assessment of model performance.
However, the paper does not fully address the potential practical challenges of implementing this approach, such as the logistics of organizing and managing a council of human raters, ensuring their diversity and consistency, and scaling the process to a large number of language models and tasks.
Additionally, the paper does not discuss the potential biases that could still arise within the council, such as group dynamics, power dynamics, or the influence of individual raters' personal beliefs and experiences. Further research may be needed to explore ways to mitigate these potential sources of bias and ensure the council's assessments are as unbiased and representative as possible.
Finally, the paper could have delved deeper into the specific criteria and methodologies the council would use to evaluate the language models, as well as how the consensus-building process would be structured and facilitated. This level of detail would help readers better understand the practical implementation and potential limitations of the proposed approach.
Conclusion
The paper presents a novel and promising approach to benchmarking large language models on highly subjective tasks, using a "Language Model Council" to reach a consensus-based evaluation. This method aims to address the limitations of traditional benchmarks in capturing the nuances of tasks that involve human judgment and interpretation, such as sentiment analysis and creative writing.
By incorporating a diverse panel of human raters, the researchers hope to produce more well-rounded and representative assessments of language model performance. This approach has the potential to lead to the development of more comprehensive and dynamic benchmarks that better reflect the subjective and social aspects of language use.
However, the paper could have provided more details on the practical implementation of this approach and addressed potential sources of bias within the council. Further research and experimentation will be needed to fully assess the feasibility and effectiveness of this method in benchmarking large language models on highly subjective tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Evaluating Large Language Models with Human Feedback: Establishing a Swedish Benchmark
Birger Moell
0
0
In the rapidly evolving field of artificial intelligence, large language models (LLMs) have demonstrated significant capabilities across numerous applications. However, the performance of these models in languages with fewer resources, such as Swedish, remains under-explored. This study introduces a comprehensive human benchmark to assess the efficacy of prominent LLMs in understanding and generating Swedish language texts using forced choice ranking. We employ a modified version of the ChatbotArena benchmark, incorporating human feedback to evaluate eleven different models, including GPT-4, GPT-3.5, various Claude and Llama models, and bespoke models like Dolphin-2.9-llama3b-8b-flashback and BeagleCatMunin. These models were chosen based on their performance on LMSYS chatbot arena and the Scandeval benchmarks. We release the chatbotarena.se benchmark as a tool to improve our understanding of language model performance in Swedish with the hopes that it will be widely used. We aim to create a leaderboard once sufficient data has been collected and analysed.
5/24/2024

A User-Centric Benchmark for Evaluating Large Language Models
Jiayin Wang, Fengran Mo, Weizhi Ma, Peijie Sun, Min Zhang, Jian-Yun Nie
0
0
Large Language Models (LLMs) are essential tools to collaborate with users on different tasks. Evaluating their performance to serve users' needs in real-world scenarios is important. While many benchmarks have been created, they mainly focus on specific predefined model abilities. Few have covered the intended utilization of LLMs by real users. To address this oversight, we propose benchmarking LLMs from a user perspective in both dataset construction and evaluation designs. We first collect 1846 real-world use cases with 15 LLMs from a user study with 712 participants from 23 countries. These self-reported cases form the User Reported Scenarios(URS) dataset with a categorization of 7 user intents. Secondly, on this authentic multi-cultural dataset, we benchmark 10 LLM services on their efficacy in satisfying user needs. Thirdly, we show that our benchmark scores align well with user-reported experience in LLM interactions across diverse intents, both of which emphasize the overlook of subjective scenarios. In conclusion, our study proposes to benchmark LLMs from a user-centric perspective, aiming to facilitate evaluations that better reflect real user needs. The benchmark dataset and code are available at https://github.com/Alice1998/URS.
4/24/2024

Evaluating the Performance of Large Language Models via Debates
Behrad Moniri, Hamed Hassani, Edgar Dobriban
0
0
Large Language Models (LLMs) are rapidly evolving and impacting various fields, necessitating the development of effective methods to evaluate and compare their performance. Most current approaches for performance evaluation are either based on fixed, domain-specific questions that lack the flexibility required in many real-world applications where tasks are not always from a single domain, or rely on human input, making them unscalable. We propose an automated benchmarking framework based on debates between LLMs, judged by another LLM. This method assesses not only domain knowledge, but also skills such as problem definition and inconsistency recognition. We evaluate the performance of various state-of-the-art LLMs using the debate framework and achieve rankings that align closely with popular rankings based on human input, eliminating the need for costly human crowdsourcing.
6/18/2024

clembench-2024: A Challenging, Dynamic, Complementary, Multilingual Benchmark and Underlying Flexible Framework for LLMs as Multi-Action Agents
Anne Beyer, Kranti Chalamalasetti, Sherzod Hakimov, Brielen Madureira, Philipp Sadler, David Schlangen
0
0
It has been established in recent work that Large Language Models (LLMs) can be prompted to self-play conversational games that probe certain capabilities (general instruction following, strategic goal orientation, language understanding abilities), where the resulting interactive game play can be automatically scored. In this paper, we take one of the proposed frameworks for setting up such game-play environments, and further test its usefulness as an evaluation instrument, along a number of dimensions: We show that it can easily keep up with new developments while avoiding data contamination, we show that the tests implemented within it are not yet saturated (human performance is substantially higher than that of even the best models), and we show that it lends itself to investigating additional questions, such as the impact of the prompting language on performance. We believe that the approach forms a good basis for making decisions on model choice for building applied interactive systems, and perhaps ultimately setting up a closed-loop development environment of system and simulated evaluator.
6/3/2024