When a language model is optimized for reasoning, does it still show embers of autoregression? An analysis of OpenAI o1

0

Sign in to get full access
Overview
- The research paper examines whether OpenAI's o1 language model, which is optimized for reasoning, still exhibits remnants of autoregression.
- It provides a detailed analysis of the o1 model's capabilities and limitations.
- The research has implications for understanding the inner workings of advanced language models and their potential applications.
Plain English Explanation
The paper explores whether the o1 language model developed by OpenAI, which is designed to excel at reasoning tasks, still retains some of the characteristics of more traditional autoregressive language models. Autoregressive models generate text one word at a time, relying on the previous words to predict the next one. In contrast, the o1 model was trained to approach language understanding and generation more holistically, focusing on reasoning and logical inference rather than just predicting the next token.
The researchers investigate whether the o1 model has truly abandoned the autoregressive approach or if there are still "embers" of that underlying structure present in its behavior. By analyzing the model's outputs and decision-making processes, they aim to shed light on the extent to which the o1 model has transcended the limitations of standard language models and achieved a more sophisticated, reasoning-oriented approach to language tasks.
Understanding the inner workings of advanced language models like o1 is crucial for unlocking their full potential and guiding the development of future AI systems that can engage in more meaningful, contextual communication and problem-solving.
Technical Explanation
The paper presents a detailed analysis of the o1 language model developed by OpenAI. The researchers investigate whether, despite being optimized for reasoning tasks, the o1 model still exhibits remnants of the autoregressive approach common in traditional language models.
The researchers conduct a series of experiments to assess the o1 model's behavior and decision-making processes. They analyze the model's outputs, investigate its sensitivity to input perturbations, and examine its ability to capture long-range dependencies in the text. These experiments are designed to reveal the extent to which the o1 model has truly transcended the limitations of autoregressive language models and adopted a more holistic, reasoning-oriented approach to language understanding and generation.
The findings of the study provide insights into the inner workings of the o1 model and its capabilities. The researchers identify both the strengths and limitations of the model's reasoning abilities, shedding light on the challenges and opportunities in developing advanced language models that can engage in more meaningful, context-aware communication and problem-solving.
Critical Analysis
The paper offers a thoughtful and nuanced analysis of the o1 language model, highlighting both its achievements and the lingering challenges it faces. While the researchers demonstrate that the o1 model has made significant strides in moving beyond the autoregressive approach, they also identify areas where remnants of that underlying structure can still be detected.
One potential limitation of the study is the scope of the experiments conducted. The researchers focus on a relatively narrow set of tasks and inputs, which may not fully capture the full range of the o1 model's capabilities and limitations. As language models continue to evolve and become more sophisticated, it will be important to explore their performance across a broader spectrum of real-world applications and scenarios.
Additionally, the paper does not delve deeply into the potential societal implications of advanced language models like o1. As these systems become more capable and influential, it will be crucial to consider the ethical and responsible development of such technologies, ensuring they are deployed in a manner that promotes the greater good and mitigates potential harms.
Conclusion
The research paper provides a valuable contribution to the understanding of advanced language models, such as the o1 model, and their underlying architecture and decision-making processes. By examining the extent to which the o1 model has transcended the limitations of autoregressive language models, the researchers shed light on the progress being made in the field of reasoning-oriented AI systems.
The findings of this study have important implications for the development of future language models that can engage in more meaningful, context-aware communication and problem-solving. As the field of AI continues to evolve, understanding the nuances and limitations of these systems will be crucial for unlocking their full potential and ensuring their responsible deployment for the benefit of society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!When a language model is optimized for reasoning, does it still show embers of autoregression? An analysis of OpenAI o1
R. Thomas McCoy, Shunyu Yao, Dan Friedman, Mathew D. Hardy, Thomas L. Griffiths
In Embers of Autoregression (McCoy et al., 2023), we showed that several large language models (LLMs) have some important limitations that are attributable to their origins in next-word prediction. Here we investigate whether these issues persist with o1, a new system from OpenAI that differs from previous LLMs in that it is optimized for reasoning. We find that o1 substantially outperforms previous LLMs in many cases, with particularly large improvements on rare variants of common tasks (e.g., forming acronyms from the second letter of each word in a list, rather than the first letter). Despite these quantitative improvements, however, o1 still displays the same qualitative trends that we observed in previous systems. Specifically, o1 - like previous LLMs - is sensitive to the probability of examples and tasks, performing better and requiring fewer thinking tokens in high-probability settings than in low-probability ones. These results show that optimizing a language model for reasoning can mitigate but might not fully overcome the language model's probability sensitivity.
Read more10/3/2024
0
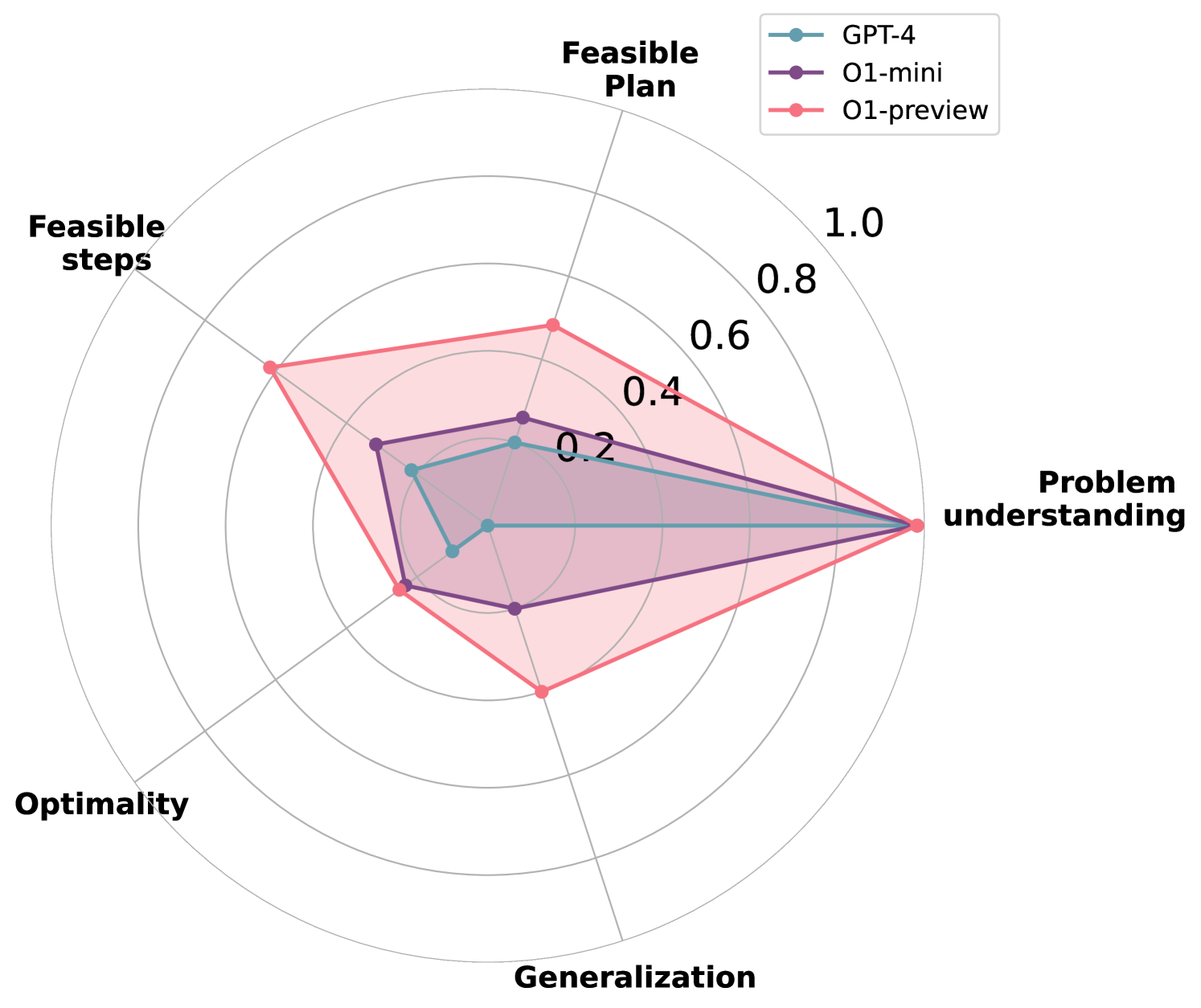
New!On The Planning Abilities of OpenAI's o1 Models: Feasibility, Optimality, and Generalizability
Kevin Wang, Junbo Li, Neel P. Bhatt, Yihan Xi, Qiang Liu, Ufuk Topcu, Zhangyang Wang
Recent advancements in Large Language Models (LLMs) have showcased their ability to perform complex reasoning tasks, but their effectiveness in planning remains underexplored. In this study, we evaluate the planning capabilities of OpenAI's o1 models across a variety of benchmark tasks, focusing on three key aspects: feasibility, optimality, and generalizability. Through empirical evaluations on constraint-heavy tasks (e.g., $textit{Barman}$, $textit{Tyreworld}$) and spatially complex environments (e.g., $textit{Termes}$, $textit{Floortile}$), we highlight o1-preview's strengths in self-evaluation and constraint-following, while also identifying bottlenecks in decision-making and memory management, particularly in tasks requiring robust spatial reasoning. Our results reveal that o1-preview outperforms GPT-4 in adhering to task constraints and managing state transitions in structured environments. However, the model often generates suboptimal solutions with redundant actions and struggles to generalize effectively in spatially complex tasks. This pilot study provides foundational insights into the planning limitations of LLMs, offering key directions for future research on improving memory management, decision-making, and generalization in LLM-based planning.
Read more10/2/2024
1
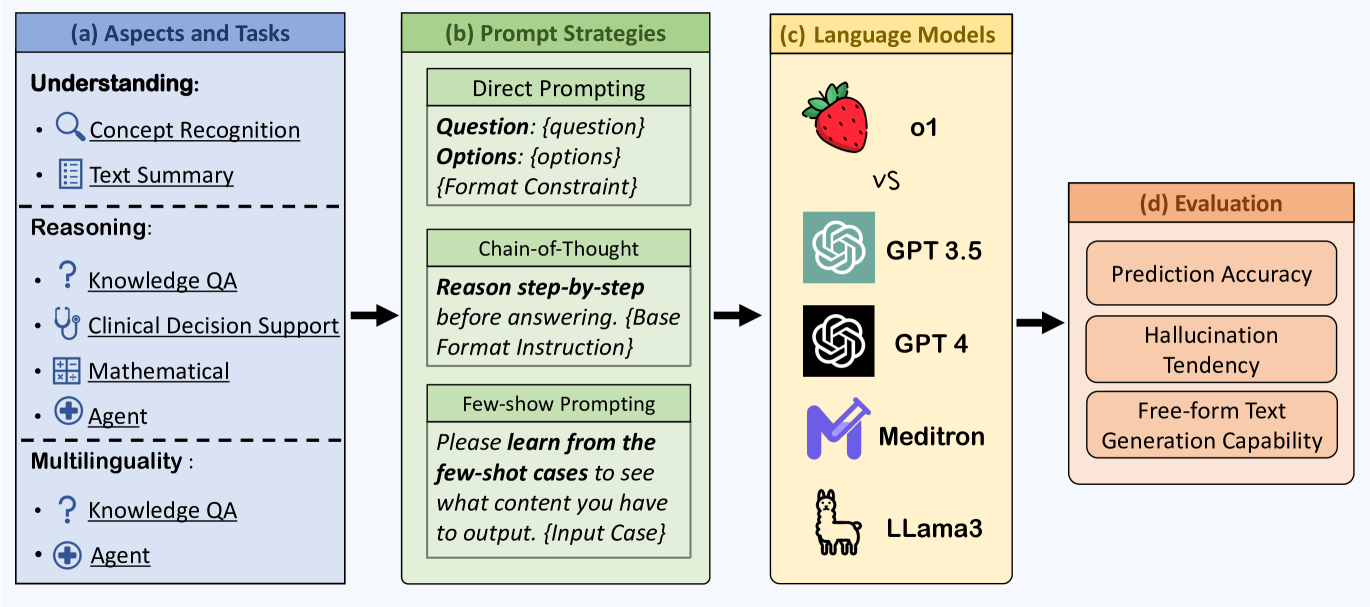
A Preliminary Study of o1 in Medicine: Are We Closer to an AI Doctor?
Yunfei Xie, Juncheng Wu, Haoqin Tu, Siwei Yang, Bingchen Zhao, Yongshuo Zong, Qiao Jin, Cihang Xie, Yuyin Zhou
Large language models (LLMs) have exhibited remarkable capabilities across various domains and tasks, pushing the boundaries of our knowledge in learning and cognition. The latest model, OpenAI's o1, stands out as the first LLM with an internalized chain-of-thought technique using reinforcement learning strategies. While it has demonstrated surprisingly strong capabilities on various general language tasks, its performance in specialized fields such as medicine remains unknown. To this end, this report provides a comprehensive exploration of o1 on different medical scenarios, examining 3 key aspects: understanding, reasoning, and multilinguality. Specifically, our evaluation encompasses 6 tasks using data from 37 medical datasets, including two newly constructed and more challenging question-answering (QA) tasks based on professional medical quizzes from the New England Journal of Medicine (NEJM) and The Lancet. These datasets offer greater clinical relevance compared to standard medical QA benchmarks such as MedQA, translating more effectively into real-world clinical utility. Our analysis of o1 suggests that the enhanced reasoning ability of LLMs may (significantly) benefit their capability to understand various medical instructions and reason through complex clinical scenarios. Notably, o1 surpasses the previous GPT-4 in accuracy by an average of 6.2% and 6.6% across 19 datasets and two newly created complex QA scenarios. But meanwhile, we identify several weaknesses in both the model capability and the existing evaluation protocols, including hallucination, inconsistent multilingual ability, and discrepant metrics for evaluation. We release our raw data and model outputs at https://ucsc-vlaa.github.io/o1_medicine/ for future research.
Read more9/24/2024

1
LLMs Still Can't Plan; Can LRMs? A Preliminary Evaluation of OpenAI's o1 on PlanBench
Karthik Valmeekam, Kaya Stechly, Subbarao Kambhampati
The ability to plan a course of action that achieves a desired state of affairs has long been considered a core competence of intelligent agents and has been an integral part of AI research since its inception. With the advent of large language models (LLMs), there has been considerable interest in the question of whether or not they possess such planning abilities. PlanBench, an extensible benchmark we developed in 2022, soon after the release of GPT3, has remained an important tool for evaluating the planning abilities of LLMs. Despite the slew of new private and open source LLMs since GPT3, progress on this benchmark has been surprisingly slow. OpenAI claims that their recent o1 (Strawberry) model has been specifically constructed and trained to escape the normal limitations of autoregressive LLMs--making it a new kind of model: a Large Reasoning Model (LRM). Using this development as a catalyst, this paper takes a comprehensive look at how well current LLMs and new LRMs do on PlanBench. As we shall see, while o1's performance is a quantum improvement on the benchmark, outpacing the competition, it is still far from saturating it. This improvement also brings to the fore questions about accuracy, efficiency, and guarantees which must be considered before deploying such systems.
Read more9/23/2024