When Linear Attention Meets Autoregressive Decoding: Towards More Effective and Efficient Linearized Large Language Models
2406.07368
0
0

Abstract
Autoregressive Large Language Models (LLMs) have achieved impressive performance in language tasks but face two significant bottlenecks: (1) quadratic complexity in the attention module as the number of tokens increases, and (2) limited efficiency due to the sequential processing nature of autoregressive LLMs during generation. While linear attention and speculative decoding offer potential solutions, their applicability and synergistic potential for enhancing autoregressive LLMs remain uncertain. We conduct the first comprehensive study on the efficacy of existing linear attention methods for autoregressive LLMs, integrating them with speculative decoding. We introduce an augmentation technique for linear attention that ensures compatibility with speculative decoding, enabling more efficient training and serving of LLMs. Extensive experiments and ablation studies involving seven existing linear attention models and five encoder/decoder-based LLMs consistently validate the effectiveness of our augmented linearized LLMs. Notably, our approach achieves up to a 6.67 reduction in perplexity on the LLaMA model and up to a 2$times$ speedup during generation compared to prior linear attention methods. Codes and models are available at https://github.com/GATECH-EIC/Linearized-LLM.
Create account to get full access
Overview
- The paper proposes a novel approach called "Linearized Language Models" that combines linear attention mechanisms with autoregressive decoding to improve the efficiency and effectiveness of large language models.
- The key ideas include using linear attention to reduce the computational complexity of attention, and leveraging autoregressive decoding to enable more efficient inference.
- The authors demonstrate the effectiveness of their approach through experiments on several language modeling benchmarks, showing improvements in both performance and efficiency.
Plain English Explanation
Large language models like GPT-3 have revolutionized natural language processing, but they can be computationally expensive and slow, especially during inference (when generating new text). <a href="https://aimodels.fyi/papers/arxiv/efficient-economic-large-language-model-inference-attention">Efficient inference of large language models</a> is an active area of research.
The authors of this paper propose a new approach called "Linearized Language Models" that aims to make large language models more efficient and effective. The key idea is to combine two important techniques:
-
Linear Attention: Instead of the traditional "quadratic" attention mechanism used in Transformers, which is computationally expensive, the authors use a <a href="https://aimodels.fyi/papers/arxiv/gated-linear-attention-transformers-hardware-efficient-training">linear attention mechanism</a>. This reduces the computational complexity and makes the model more efficient.
-
Autoregressive Decoding: The authors use an autoregressive decoding strategy, where the model generates text one token at a time, <a href="https://aimodels.fyi/papers/arxiv/comprehensive-survey-accelerated-generation-techniques-large-language">similar to how humans read and write</a>. This allows the model to be more efficient during inference, as it doesn't need to generate the entire output at once.
By combining these two techniques, the authors create a "Linearized Language Model" that is both more effective (better performance on language modeling benchmarks) and more efficient (faster inference) than traditional large language models.
Technical Explanation
The paper proposes a novel approach called "Linearized Language Models" that combines linear attention mechanisms and autoregressive decoding to improve the efficiency and effectiveness of large language models.
The key technical elements of the paper include:
-
Linear Attention: Instead of using the standard quadratic attention mechanism in Transformer models, the authors employ a <a href="https://aimodels.fyi/papers/arxiv/gated-linear-attention-transformers-hardware-efficient-training">gated linear attention mechanism</a>. This reduces the computational complexity from O(n^2) to O(n), making the attention module more efficient.
-
Autoregressive Decoding: The authors use an autoregressive decoding strategy, where the model generates text one token at a time, <a href="https://aimodels.fyi/papers/arxiv/comprehensive-survey-accelerated-generation-techniques-large-language">similar to how humans read and write</a>. This allows the model to be more efficient during inference, as it doesn't need to generate the entire output at once.
-
Linearized Language Model Architecture: By combining the linear attention mechanism and autoregressive decoding, the authors create a "Linearized Language Model" architecture that is more efficient and effective than traditional large language models.
The authors evaluate their Linearized Language Model on several language modeling benchmarks, including WikiText-103, Wikitext-2, and LAMBADA. They show that their approach outperforms state-of-the-art large language models in terms of both performance and efficiency, as measured by perplexity and inference latency.
Critical Analysis
The paper provides a compelling approach to improving the efficiency and effectiveness of large language models, which is an important and actively researched area. The authors' combination of linear attention and autoregressive decoding is a novel and promising direction.
One potential limitation of the paper is that it focuses primarily on language modeling benchmarks, and does not evaluate the performance of Linearized Language Models on other downstream tasks, such as question answering or text generation. <a href="https://aimodels.fyi/papers/arxiv/survey-efficient-inference-large-language-models">Evaluating the broader applicability of the approach would be valuable</a>.
Additionally, the paper does not provide a detailed analysis of the tradeoffs between the linear attention mechanism and the autoregressive decoding strategy. It would be interesting to understand the relative contributions of each component to the overall performance and efficiency gains.
Finally, the paper does not address potential limitations or edge cases of the Linearized Language Model approach, such as how it might perform on very long input sequences or how it could be further optimized for specific hardware or deployment scenarios.
Overall, the paper presents an innovative and promising approach to improving large language models, but further research and analysis would be valuable to fully understand the strengths, weaknesses, and broader implications of the Linearized Language Model technique.
Conclusion
The paper introduces a novel approach called "Linearized Language Models" that combines linear attention mechanisms and autoregressive decoding to create more efficient and effective large language models. The authors demonstrate the effectiveness of their approach through experiments on several language modeling benchmarks, showing improvements in both performance and efficiency.
This work represents an important step forward in the ongoing effort to make large language models more practical and accessible, with potential applications in a wide range of natural language processing tasks. By focusing on both effectiveness and efficiency, the Linearized Language Model approach could help enable the widespread deployment and use of these powerful AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
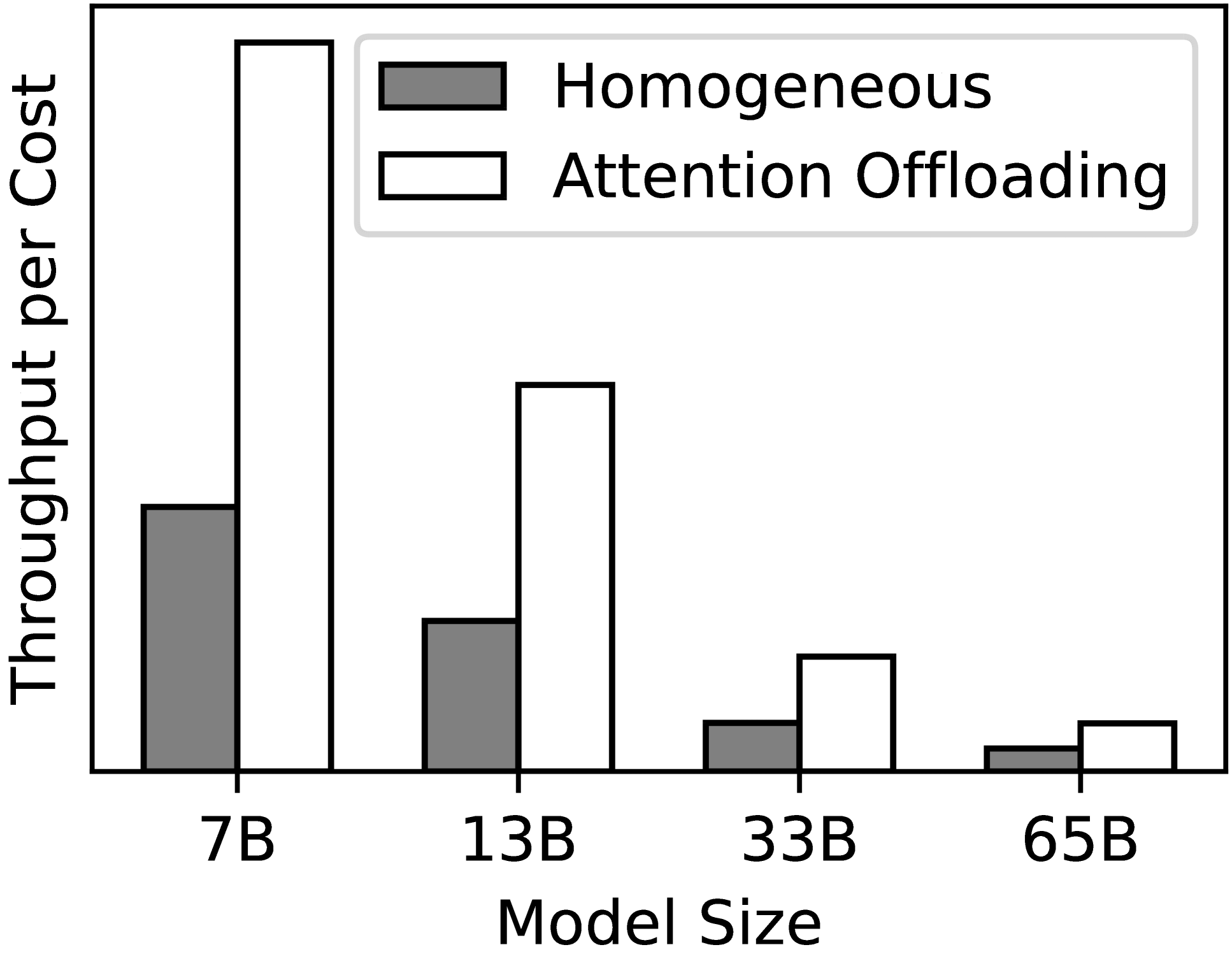
Efficient and Economic Large Language Model Inference with Attention Offloading
Shaoyuan Chen, Yutong Lin, Mingxing Zhang, Yongwei Wu
0
0
Transformer-based large language models (LLMs) exhibit impressive performance in generative tasks but introduce significant challenges in real-world serving due to inefficient use of the expensive, computation-optimized accelerators. This mismatch arises from the autoregressive nature of LLMs, where the generation phase comprises operators with varying resource demands. Specifically, the attention operator is memory-intensive, exhibiting a memory access pattern that clashes with the strengths of modern accelerators, especially as context length increases. To enhance the efficiency and cost-effectiveness of LLM serving, we introduce the concept of attention offloading. This approach leverages a collection of cheap, memory-optimized devices for the attention operator while still utilizing high-end accelerators for other parts of the model. This heterogeneous setup ensures that each component is tailored to its specific workload, maximizing overall performance and cost efficiency. Our comprehensive analysis and experiments confirm the viability of splitting the attention computation over multiple devices. Also, the communication bandwidth required between heterogeneous devices proves to be manageable with prevalent networking technologies. To further validate our theory, we develop Lamina, an LLM inference system that incorporates attention offloading. Experimental results indicate that Lamina can provide 1.48x-12.1x higher estimated throughput per dollar than homogeneous solutions.
5/6/2024

CLLMs: Consistency Large Language Models
Siqi Kou, Lanxiang Hu, Zhezhi He, Zhijie Deng, Hao Zhang
0
0
Parallel decoding methods such as Jacobi decoding show promise for more efficient LLM inference as it breaks the sequential nature of the LLM decoding process and transforms it into parallelizable computation. However, in practice, it achieves little speedup compared to traditional autoregressive (AR) decoding, primarily because Jacobi decoding seldom accurately predicts more than one token in a single fixed-point iteration step. To address this, we develop a new approach aimed at realizing fast convergence from any state to the fixed point on a Jacobi trajectory. This is accomplished by refining the target LLM to consistently predict the fixed point given any state as input. Extensive experiments demonstrate the effectiveness of our method, showing 2.4$times$ to 3.4$times$ improvements in generation speed while preserving generation quality across both domain-specific and open-domain benchmarks.
6/14/2024
A Survey on Efficient Inference for Large Language Models
Zixuan Zhou, Xuefei Ning, Ke Hong, Tianyu Fu, Jiaming Xu, Shiyao Li, Yuming Lou, Luning Wang, Zhihang Yuan, Xiuhong Li, Shengen Yan, Guohao Dai, Xiao-Ping Zhang, Yuhan Dong, Yu Wang
0
0
Large Language Models (LLMs) have attracted extensive attention due to their remarkable performance across various tasks. However, the substantial computational and memory requirements of LLM inference pose challenges for deployment in resource-constrained scenarios. Efforts within the field have been directed towards developing techniques aimed at enhancing the efficiency of LLM inference. This paper presents a comprehensive survey of the existing literature on efficient LLM inference. We start by analyzing the primary causes of the inefficient LLM inference, i.e., the large model size, the quadratic-complexity attention operation, and the auto-regressive decoding approach. Then, we introduce a comprehensive taxonomy that organizes the current literature into data-level, model-level, and system-level optimization. Moreover, the paper includes comparative experiments on representative methods within critical sub-fields to provide quantitative insights. Last but not least, we provide some knowledge summary and discuss future research directions.
6/11/2024
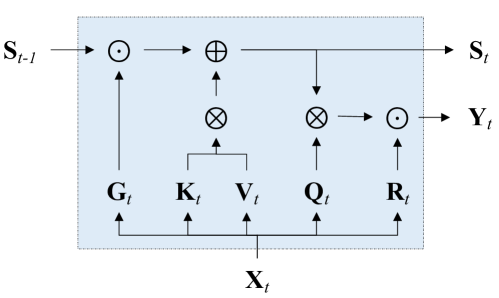
Gated Linear Attention Transformers with Hardware-Efficient Training
Songlin Yang, Bailin Wang, Yikang Shen, Rameswar Panda, Yoon Kim
0
0
Transformers with linear attention allow for efficient parallel training but can simultaneously be formulated as an RNN with 2D (matrix-valued) hidden states, thus enjoying linear-time inference complexity. However, linear attention generally underperforms ordinary softmax attention. Moreover, current implementations of linear attention lack I/O-awareness and are thus slower than highly optimized implementations of softmax attention. This work describes a hardware-efficient algorithm for linear attention that trades off memory movement against parallelizability. The resulting implementation, dubbed FLASHLINEARATTENTION, is faster than FLASHATTENTION-2 (Dao, 2023) as a standalone layer even on short sequence lengths (e.g., 1K). We then generalize this algorithm to a more expressive variant of linear attention with data-dependent gates. When used as a replacement for the standard attention layer in Transformers, the resulting gated linear attention (GLA) Transformer is found to perform competitively against the LLaMA-architecture Transformer (Touvron et al., 2023) as well recent linear-time-inference baselines such as RetNet (Sun et al., 2023a) and Mamba (Gu & Dao, 2023) on moderate-scale language modeling experiments. GLA Transformer is especially effective at length generalization, enabling a model trained on 2K to generalize to sequences longer than 20K without significant perplexity degradations. For training speed, the GLA Transformer has higher throughput than a similarly-sized Mamba model.
6/6/2024