Whisper-SV: Adapting Whisper for Low-data-resource Speaker Verification

0
Sign in to get full access
Overview
- The paper proposes a new system called "Whisper-SV" that adapts the popular Whisper speech recognition model for low-data-resource speaker verification tasks.
- Whisper-SV leverages the pre-trained Whisper model's ability to extract rich audio representations and fine-tunes it for speaker verification on small datasets.
- The key innovation is a novel adapter module that enables efficient transfer learning from Whisper to the target speaker verification task.
Plain English Explanation
The researchers have developed a new system called Whisper-SV that takes an existing speech recognition model called Whisper and adapts it to work well for the task of speaker verification, even when only limited training data is available.
Whisper is a powerful speech recognition model that can transcribe audio into text. Whisper-SV builds on top of Whisper by adding a special "adapter" module that allows the model to be fine-tuned for the specific task of speaker verification.
Speaker verification is the process of determining whether a given voice sample belongs to a particular speaker. This is useful for applications like secure voice authentication. But training a speaker verification model from scratch often requires a lot of labeled voice data, which can be hard to come by, especially for less common languages or speakers.
By starting with the pre-trained Whisper model and just fine-tuning the adapter module, Whisper-SV is able to achieve strong speaker verification performance even when only limited training data is available. This makes the system useful for real-world applications where large voice datasets may not be accessible.
Technical Explanation
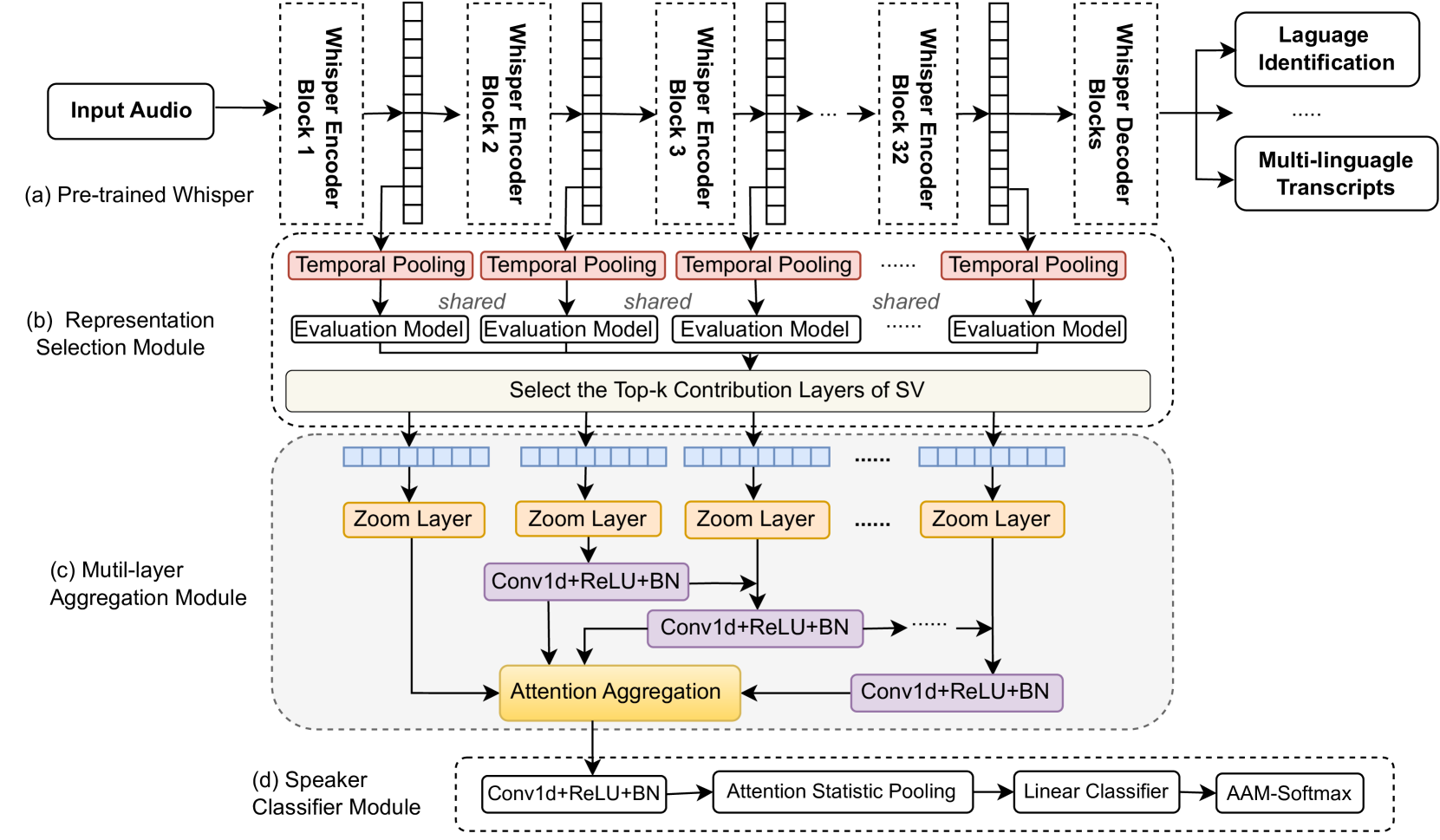
The core idea behind Whisper-SV is to leverage the rich audio representations learned by the pre-trained Whisper model and adapt them for the speaker verification task through the use of a novel adapter module.
The Whisper model is first used to extract audio features from the input speech samples. These features capture important information about the speech content, speaker characteristics, and other acoustic properties. The adapter module is then trained on top of the Whisper features to learn a speaker-discriminative representation, using only the limited labeled data available for the target speaker verification task.
The adapter module consists of a series of convolutional and pooling layers that transform the Whisper features into a compact fixed-size embedding. This embedding is then used for speaker verification, either by computing similarity scores between enrollment and test samples, or by training a classifier to predict speaker identity.
The key advantage of this approach is that the majority of the model parameters, i.e., the Whisper base model, are shared across the speech recognition and speaker verification tasks. This enables efficient transfer learning and allows Whisper-SV to achieve strong performance even when only small amounts of speaker verification data are available for fine-tuning.
Critical Analysis
The authors demonstrate the effectiveness of Whisper-SV on several low-resource speaker verification benchmarks, showing significant improvements over previous transfer learning approaches. However, the paper does not provide a thorough analysis of the model's limitations or potential failure cases.
One area that could be explored further is the generalization of Whisper-SV to more diverse speaker populations and acoustic environments. The experiments in the paper focus on relatively clean speech data, and it's unclear how the system would perform in the presence of background noise, accents, or other real-world challenges.
Additionally, the paper does not discuss the computational and memory efficiency of Whisper-SV compared to training a speaker verification model from scratch. While the use of the Whisper base model is likely to provide some efficiency benefits, the overhead of the adapter module and the fine-tuning process should be evaluated.
Overall, the Whisper-SV approach is a promising step towards improving the data efficiency of speaker verification systems, but further research is needed to fully understand its limitations and potential for real-world deployment.
Conclusion
The Whisper-SV paper presents a novel approach for adapting the powerful Whisper speech recognition model to the task of low-data-resource speaker verification. By leveraging the rich audio representations learned by Whisper and fine-tuning them with a specialized adapter module, Whisper-SV is able to achieve strong speaker verification performance even when only limited training data is available.
This work demonstrates the potential of transfer learning and model adaptation techniques to enable robust and data-efficient speech technologies, which could have important applications in areas like secure authentication, personalized assistants, and accessibility tools. While the system's performance is promising, further research is needed to explore its generalization capabilities and real-world practicality.
Overall, the Whisper-SV paper makes a valuable contribution to the field of speaker verification and highlights the value of building upon state-of-the-art models like Whisper to tackle challenging low-resource problems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Whisper-SV: Adapting Whisper for Low-data-resource Speaker Verification
Li Zhang, Ning Jiang, Qing Wang, Yue Li, Quan Lu, Lei Xie
Trained on 680,000 hours of massive speech data, Whisper is a multitasking, multilingual speech foundation model demonstrating superior performance in automatic speech recognition, translation, and language identification. However, its applicability in speaker verification (SV) tasks remains unexplored, particularly in low-data-resource scenarios where labeled speaker data in specific domains are limited. To fill this gap, we propose a lightweight adaptor framework to boost SV with Whisper, namely Whisper-SV. Given that Whisper is not specifically optimized for SV tasks, we introduce a representation selection module to quantify the speaker-specific characteristics contained in each layer of Whisper and select the top-k layers with prominent discriminative speaker features. To aggregate pivotal speaker-related features while diminishing non-speaker redundancies across the selected top-k distinct layers of Whisper, we design a multi-layer aggregation module in Whisper-SV to integrate multi-layer representations into a singular, compacted representation for SV. In the multi-layer aggregation module, we employ convolutional layers with shortcut connections among different layers to refine speaker characteristics derived from multi-layer representations from Whisper. In addition, an attention aggregation layer is used to reduce non-speaker interference and amplify speaker-specific cues for SV tasks. Finally, a simple classification module is used for speaker classification. Experiments on VoxCeleb1, FFSVC, and IMSV datasets demonstrate that Whisper-SV achieves EER/minDCF of 2.22%/0.307, 6.14%/0.488, and 7.50%/0.582, respectively, showing superior performance in low-data-resource SV scenarios.
Read more7/16/2024

0
Whisper-PMFA: Partial Multi-Scale Feature Aggregation for Speaker Verification using Whisper Models
Yiyang Zhao, Shuai Wang, Guangzhi Sun, Zehua Chen, Chao Zhang, Mingxing Xu, Thomas Fang Zheng
In this paper, Whisper, a large-scale pre-trained model for automatic speech recognition, is proposed to apply to speaker verification. A partial multi-scale feature aggregation (PMFA) approach is proposed based on a subset of Whisper encoder blocks to derive highly discriminative speaker embeddings.Experimental results demonstrate that using the middle to later blocks of the Whisper encoder keeps more speaker information. On the VoxCeleb1 and CN-Celeb1 datasets, our system achieves 1.42% and 8.23% equal error rates (EERs) respectively, receiving 0.58% and 1.81% absolute EER reductions over the ECAPA-TDNN baseline, and 0.46% and 0.97% over the ResNet34 baseline. Furthermore, our results indicate that using Whisper models trained on multilingual data can effectively enhance the model's robustness across languages. Finally, the low-rank adaptation approach is evaluated, which reduces the trainable model parameters by approximately 45 times while only slightly increasing EER by 0.2%.
Read more8/29/2024
0
Efficient Compression of Multitask Multilingual Speech Models
Thomas Palmeira Ferraz
Whisper is a multitask and multilingual speech model covering 99 languages. It yields commendable automatic speech recognition (ASR) results in a subset of its covered languages, but the model still underperforms on a non-negligible number of under-represented languages, a problem exacerbated in smaller model versions. In this work, we examine its limitations, demonstrating the presence of speaker-related (gender, age) and model-related (resourcefulness and model size) bias. Despite that, we show that only model-related bias are amplified by quantization, impacting more low-resource languages and smaller models. Searching for a better compression approach, we propose DistilWhisper, an approach that is able to bridge the performance gap in ASR for these languages while retaining the advantages of multitask and multilingual capabilities. Our approach involves two key strategies: lightweight modular ASR fine-tuning of whisper-small using language-specific experts, and knowledge distillation from whisper-large-v2. This dual approach allows us to effectively boost ASR performance while keeping the robustness inherited from the multitask and multilingual pre-training. Results demonstrate that our approach is more effective than standard fine-tuning or LoRA adapters, boosting performance in the targeted languages for both in- and out-of-domain test sets, while introducing only a negligible parameter overhead at inference.
Read more5/3/2024
🔍
0
Whispy: Adapting STT Whisper Models to Real-Time Environments
Antonio Bevilacqua, Paolo Saviano, Alessandro Amirante, Simon Pietro Romano
Large general-purpose transformer models have recently become the mainstay in the realm of speech analysis. In particular, Whisper achieves state-of-the-art results in relevant tasks such as speech recognition, translation, language identification, and voice activity detection. However, Whisper models are not designed to be used in real-time conditions, and this limitation makes them unsuitable for a vast plethora of practical applications. In this paper, we introduce Whispy, a system intended to bring live capabilities to the Whisper pretrained models. As a result of a number of architectural optimisations, Whispy is able to consume live audio streams and generate high level, coherent voice transcriptions, while still maintaining a low computational cost. We evaluate the performance of our system on a large repository of publicly available speech datasets, investigating how the transcription mechanism introduced by Whispy impacts on the Whisper output. Experimental results show how Whispy excels in robustness, promptness, and accuracy.
Read more5/7/2024