Whisper-Flamingo: Integrating Visual Features into Whisper for Audio-Visual Speech Recognition and Translation

0

Sign in to get full access
Overview
- Introduces Whisper-Flamingo, a model that integrates visual features into the Whisper audio-to-text model to improve performance on audio-visual speech recognition and translation tasks.
- Builds on previous research in audio-Flamingo, Multilingual Audio-Visual Speech Recognition, VisPer, and Efficient Compression of Multitask Multilingual Speech Models.
- Explores a multitask training approach to enhance the Whisper model's performance on contextual tasks, as discussed in Multitask Training Approach to Enhance Whisper Contextual.
Plain English Explanation
Whisper-Flamingo is a new artificial intelligence (AI) model that combines visual information with audio data to improve speech recognition and translation. The model is built on top of the existing Whisper audio-to-text model, which is known for its impressive performance on speech-to-text tasks.
By incorporating visual features, such as the movements of a speaker's lips and facial expressions, Whisper-Flamingo can better understand the context and meaning of spoken language. This is particularly useful in situations where the audio quality is poor, or the speaker has an accent or speaks a different language.
The researchers behind Whisper-Flamingo have also explored ways to enhance the model's ability to handle contextual information, such as the topic of conversation or the relationship between the speakers. This can be especially helpful in scenarios where the meaning of a word or phrase depends on the broader context.
Overall, Whisper-Flamingo represents an exciting advance in the field of audio-visual speech recognition and translation, with the potential to improve communication and understanding in a wide range of applications, from real-time translation services to assistive technology for people with hearing or speech impairments.
Technical Explanation
Whisper-Flamingo builds on the Whisper model, a state-of-the-art audio-to-text transformer-based model, by integrating visual features from the Flamingo multimodal language model. The researchers hypothesized that incorporating visual information, such as lip movements and facial expressions, could improve the model's performance on audio-visual speech recognition and translation tasks.
The Whisper-Flamingo architecture consists of a shared encoder that processes both audio and visual inputs, followed by separate decoders for speech recognition and translation. The audio encoder is based on the Whisper model, while the visual encoder is adapted from the Flamingo model. The model is trained in a multitask fashion, where it learns to perform speech recognition and translation simultaneously.
To enhance the model's ability to handle contextual information, the researchers also explored a multitask training approach, where the model is trained on additional tasks, such as language modeling and question answering, in addition to the core speech recognition and translation tasks. This approach, as discussed in Multitask Training Approach to Enhance Whisper Contextual, aims to improve the model's understanding of language and its ability to leverage contextual cues.
The Whisper-Flamingo model was evaluated on a range of audio-visual speech recognition and translation benchmarks, including the Multilingual Audio-Visual Speech Recognition and VisPer datasets. The results demonstrate the effectiveness of integrating visual features and leveraging contextual information, with Whisper-Flamingo outperforming the original Whisper model on several key metrics.
Critical Analysis
While the Whisper-Flamingo model shows promising results, the paper acknowledges several limitations and areas for further research. One key limitation is the reliance on high-quality visual input, which may not always be available in real-world scenarios. The researchers suggest exploring ways to make the model more robust to variations in visual data quality and availability.
Additionally, the paper notes that the multitask training approach used to enhance contextual understanding may not be applicable to all scenarios, and the benefits may vary depending on the specific tasks and datasets involved. Further research is needed to better understand the optimal multitask training strategies and their generalization to different applications.
Another potential concern is the computational complexity and resource requirements of the Whisper-Flamingo model, which could limit its deployment in resource-constrained environments. The paper mentions efforts to optimize the model's efficiency, but more work may be needed to address these challenges.
Overall, the Whisper-Flamingo research represents an important step forward in the field of audio-visual speech recognition and translation, but more work is needed to fully realize the potential of this technology and address the remaining challenges.
Conclusion
The Whisper-Flamingo model demonstrates the power of integrating visual features with audio data to improve speech recognition and translation performance. By leveraging the strengths of the Whisper and Flamingo models, the researchers have developed a system that can better understand the context and meaning of spoken language, even in challenging scenarios.
The multitask training approach used to enhance Whisper-Flamingo's contextual understanding is a promising area of research that could have broader implications for language models and their ability to handle complex, real-world language use.
Overall, the Whisper-Flamingo work represents an important advancement in the field of audio-visual speech processing, with the potential to improve communication, accessibility, and understanding across a wide range of applications. As the technology continues to evolve, it will be important to address the remaining challenges and explore new ways to make this technology more robust, efficient, and widely accessible.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Whisper-Flamingo: Integrating Visual Features into Whisper for Audio-Visual Speech Recognition and Translation
Andrew Rouditchenko, Yuan Gong, Samuel Thomas, Leonid Karlinsky, Hilde Kuehne, Rogerio Feris, James Glass
Audio-Visual Speech Recognition (AVSR) uses lip-based video to improve performance in noise. Since videos are harder to obtain than audio, the video training data of AVSR models is usually limited to a few thousand hours. In contrast, speech models such as Whisper are trained with hundreds of thousands of hours of data, and thus learn a better speech-to-text decoder. The huge training data difference motivates us to adapt Whisper to handle video inputs. Inspired by Flamingo which injects visual features into language models, we propose Whisper-Flamingo which integrates visual features into the Whisper speech recognition and translation model with gated cross attention. Our audio-visual Whisper-Flamingo outperforms audio-only Whisper on English speech recognition and En-X translation for 6 languages in noisy conditions. Moreover, Whisper-Flamingo is a versatile model and conducts all of these tasks using one set of parameters, while prior methods are trained separately on each language.
Read more6/17/2024

0
Audio Flamingo: A Novel Audio Language Model with Few-Shot Learning and Dialogue Abilities
Zhifeng Kong, Arushi Goel, Rohan Badlani, Wei Ping, Rafael Valle, Bryan Catanzaro
Augmenting large language models (LLMs) to understand audio -- including non-speech sounds and non-verbal speech -- is critically important for diverse real-world applications of LLMs. In this paper, we propose Audio Flamingo, a novel audio language model with 1) strong audio understanding abilities, 2) the ability to quickly adapt to unseen tasks via in-context learning and retrieval, and 3) strong multi-turn dialogue abilities. We introduce a series of training techniques, architecture design, and data strategies to enhance our model with these abilities. Extensive evaluations across various audio understanding tasks confirm the efficacy of our method, setting new state-of-the-art benchmarks. Our demo website is https://audioflamingo.github.io/ and the code is open-sourced at https://github.com/NVIDIA/audio-flamingo.
Read more5/29/2024
0
Whisper-SV: Adapting Whisper for Low-data-resource Speaker Verification
Li Zhang, Ning Jiang, Qing Wang, Yue Li, Quan Lu, Lei Xie
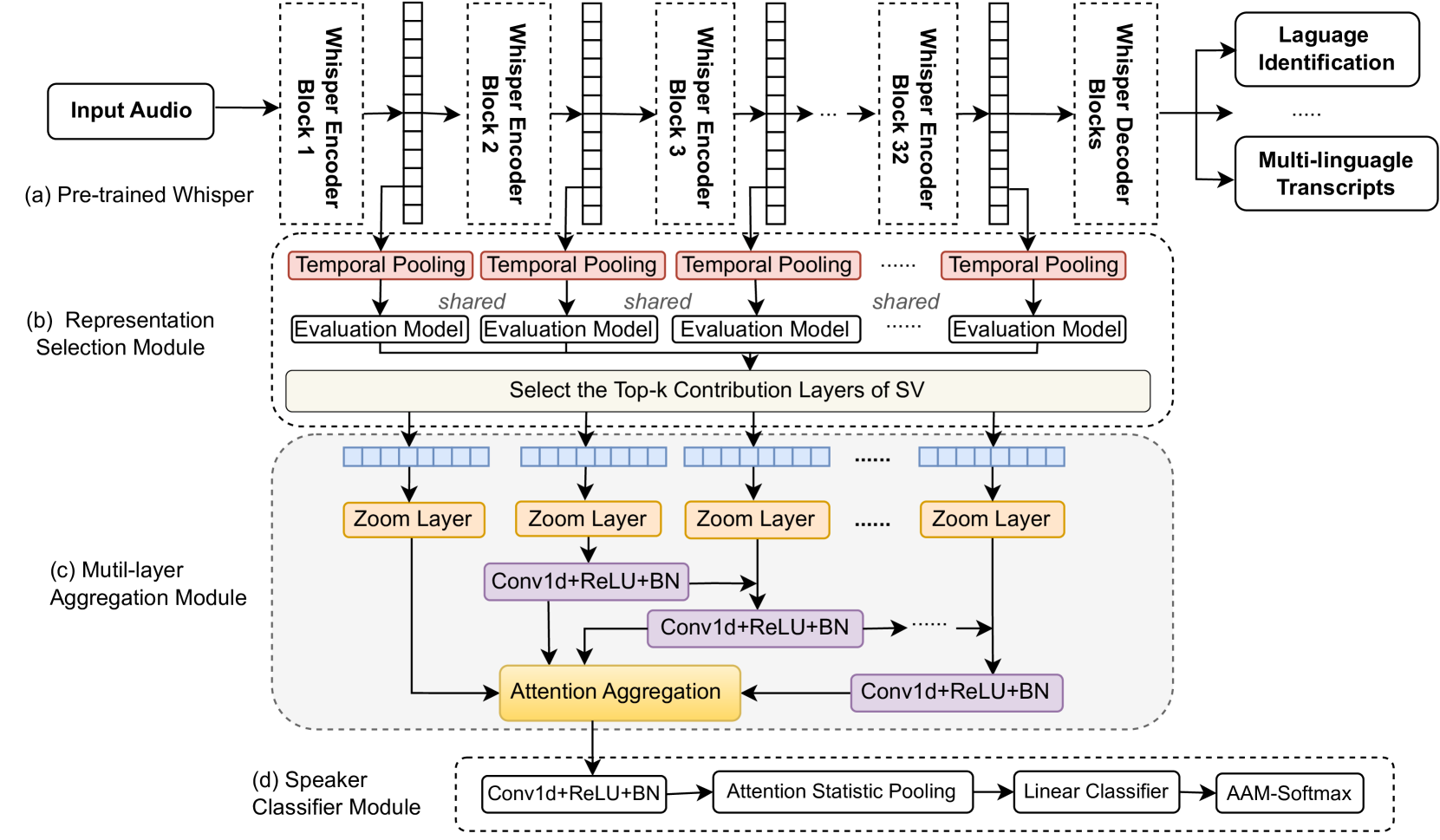
Trained on 680,000 hours of massive speech data, Whisper is a multitasking, multilingual speech foundation model demonstrating superior performance in automatic speech recognition, translation, and language identification. However, its applicability in speaker verification (SV) tasks remains unexplored, particularly in low-data-resource scenarios where labeled speaker data in specific domains are limited. To fill this gap, we propose a lightweight adaptor framework to boost SV with Whisper, namely Whisper-SV. Given that Whisper is not specifically optimized for SV tasks, we introduce a representation selection module to quantify the speaker-specific characteristics contained in each layer of Whisper and select the top-k layers with prominent discriminative speaker features. To aggregate pivotal speaker-related features while diminishing non-speaker redundancies across the selected top-k distinct layers of Whisper, we design a multi-layer aggregation module in Whisper-SV to integrate multi-layer representations into a singular, compacted representation for SV. In the multi-layer aggregation module, we employ convolutional layers with shortcut connections among different layers to refine speaker characteristics derived from multi-layer representations from Whisper. In addition, an attention aggregation layer is used to reduce non-speaker interference and amplify speaker-specific cues for SV tasks. Finally, a simple classification module is used for speaker classification. Experiments on VoxCeleb1, FFSVC, and IMSV datasets demonstrate that Whisper-SV achieves EER/minDCF of 2.22%/0.307, 6.14%/0.488, and 7.50%/0.582, respectively, showing superior performance in low-data-resource SV scenarios.
Read more7/16/2024
🗣️
0
Multilingual Audio-Visual Speech Recognition with Hybrid CTC/RNN-T Fast Conformer
Maxime Burchi, Krishna C. Puvvada, Jagadeesh Balam, Boris Ginsburg, Radu Timofte
Humans are adept at leveraging visual cues from lip movements for recognizing speech in adverse listening conditions. Audio-Visual Speech Recognition (AVSR) models follow similar approach to achieve robust speech recognition in noisy conditions. In this work, we present a multilingual AVSR model incorporating several enhancements to improve performance and audio noise robustness. Notably, we adapt the recently proposed Fast Conformer model to process both audio and visual modalities using a novel hybrid CTC/RNN-T architecture. We increase the amount of audio-visual training data for six distinct languages, generating automatic transcriptions of unlabelled multilingual datasets (VoxCeleb2 and AVSpeech). Our proposed model achieves new state-of-the-art performance on the LRS3 dataset, reaching WER of 0.8%. On the recently introduced MuAViC benchmark, our model yields an absolute average-WER reduction of 11.9% in comparison to the original baseline. Finally, we demonstrate the ability of the proposed model to perform audio-only, visual-only, and audio-visual speech recognition at test time.
Read more5/24/2024