Whispers of Doubt Amidst Echoes of Triumph in NLP Robustness

0
📉
Sign in to get full access
Overview
- Researchers investigated whether larger and more powerful language models can resolve longstanding issues with robustness in natural language processing (NLP) systems.
- They evaluated over 20 different language models of varying sizes and architectural choices on several tests, including out-of-domain datasets, behavioral testing, contrast sets, and adversarial inputs.
- The results suggest that simply scaling up model size does not necessarily make them more robust, and current approaches to measuring robustness may have their own limitations.
Plain English Explanation
Robustness is an important goal in natural language processing (NLP) - the ability of AI systems to handle a wide range of language tasks accurately, even when faced with unusual or challenging inputs. This paper examines whether building larger and more powerful language models can help solve this problem.
The researchers tested over 20 different language models, ranging from small to very large, on a variety of evaluation tasks. These included seeing how the models performed on datasets that were outside their original training domain, as well as more specialized tests like "behavioral testing" to assess their deeper language understanding, and "contrast sets" that introduced small but meaningful changes to sentences to see if the models could distinguish them.
The key finding is that simply making the models bigger and more powerful does not automatically make them more robust. The models still struggled with many of the more challenging evaluation tasks, revealing gaps in their language abilities. Additionally, the researchers noted that the current methods used to test for model robustness, such as generating adversarial inputs to confuse the models, may have their own limitations and not provide a sufficiently deep probe of true robustness.
In summary, the quest for robust NLP systems remains an open challenge - increasing model size is not a silver bullet, and the field may need to re-evaluate how it measures and defines robustness going forward.
Technical Explanation
This paper explores whether scaling up language models can improve their robustness - their ability to handle a diverse range of language tasks accurately, even with unusual or challenging inputs. The researchers evaluated over 20 different language models with varying sizes, architectural choices, and pretraining objectives on several robustness tests:
- Out-of-domain evaluations: Assessing performance on datasets outside the models' original training distribution.
- Behavioral testing with CheckLists: Using specialized test suites to probe the models' deeper language understanding.
- Contrast sets: Making small but meaningful changes to inputs to see if models can distinguish them.
- Adversarial inputs: Attempting to confuse the models with adversarially-generated inputs.
The key findings are:
- Not all out-of-domain tests provide clear insights into model robustness. The researchers found gaps in performance on the behavioral testing and contrast set evaluations, indicating that scaling model size alone does not make them adequately robust.
- The current approaches for adversarial evaluations have limitations - the adversarial examples can be easily circumvented, and these evaluations may not represent a sufficiently deep probe of model robustness.
The paper concludes that the problem of robustness in NLP remains unresolved, and the methods used to measure it also need to be reassessed.
Critical Analysis
The paper raises important points about the challenges of achieving robust natural language processing systems. While increasing model size and power is an intuitive approach, the results show this is not a panacea for robustness issues.
One limitation acknowledged by the authors is that their analysis of adversarial evaluations suggests these methods may have flaws and not provide a comprehensive assessment of model robustness. This is a critical point, as adversarial testing has become a common way to probe the limits of AI systems. Further research is needed to develop more reliable approaches for evaluating robustness.
Additionally, the paper does not delve into the potential reasons why simply scaling up models does not reliably improve robustness. This could be an area for future investigation - understanding the underlying factors that contribute to robust language understanding could inform the development of more effective modeling approaches.
Overall, this research highlights the continued difficulty of building truly robust NLP systems, and the need for the field to re-examine its assumptions and methods around this challenge. A more holistic understanding of the drivers of robustness may be required to make substantive progress.
Conclusion
This paper illustrates that the quest for robust natural language processing remains an open problem, despite the rapid advances in language model scale and capability. Merely increasing model size does not automatically resolve longstanding issues with NLP robustness, as evidenced by the models' performance gaps on specialized evaluation tasks.
Moreover, the current methods used to assess robustness, such as adversarial testing, may have their own limitations and not provide a comprehensive measure of a model's true language understanding abilities. Addressing the challenge of robustness in NLP will likely require a more nuanced and multifaceted approach, going beyond simplistic scaling of model size.
Looking ahead, further research is needed to better understand the factors that contribute to robust language processing, and to develop more reliable evaluation frameworks. Solving the robustness problem could unlock significant advancements in the real-world applicability of NLP systems. This paper serves as an important reminder that the field still has work to do in this critical area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📉
0
Whispers of Doubt Amidst Echoes of Triumph in NLP Robustness
Ashim Gupta, Rishanth Rajendhran, Nathan Stringham, Vivek Srikumar, Ana Marasovi'c
Do larger and more performant models resolve NLP's longstanding robustness issues? We investigate this question using over 20 models of different sizes spanning different architectural choices and pretraining objectives. We conduct evaluations using (a) out-of-domain and challenge test sets, (b) behavioral testing with CheckLists, (c) contrast sets, and (d) adversarial inputs. Our analysis reveals that not all out-of-domain tests provide insight into robustness. Evaluating with CheckLists and contrast sets shows significant gaps in model performance; merely scaling models does not make them adequately robust. Finally, we point out that current approaches for adversarial evaluations of models are themselves problematic: they can be easily thwarted, and in their current forms, do not represent a sufficiently deep probe of model robustness. We conclude that not only is the question of robustness in NLP as yet unresolved, but even some of the approaches to measure robustness need to be reassessed.
Read more4/4/2024
💬
0
Evaluating Concurrent Robustness of Language Models Across Diverse Challenge Sets
Vatsal Gupta, Pranshu Pandya, Tushar Kataria, Vivek Gupta, Dan Roth
Language models, characterized by their black-box nature, often hallucinate and display sensitivity to input perturbations, causing concerns about trust. To enhance trust, it is imperative to gain a comprehensive understanding of the model's failure modes and develop effective strategies to improve their performance. In this study, we introduce a methodology designed to examine how input perturbations affect language models across various scales, including pre-trained models and large language models (LLMs). Utilizing fine-tuning, we enhance the model's robustness to input perturbations. Additionally, we investigate whether exposure to one perturbation enhances or diminishes the model's performance with respect to other perturbations. To address robustness against multiple perturbations, we present three distinct fine-tuning strategies. Furthermore, we broaden the scope of our methodology to encompass large language models (LLMs) by leveraging a chain of thought (CoT) prompting approach augmented with exemplars. We employ the Tabular-NLI task to showcase how our proposed strategies adeptly train a robust model, enabling it to address diverse perturbations while maintaining accuracy on the original dataset.
Read more7/17/2024
0
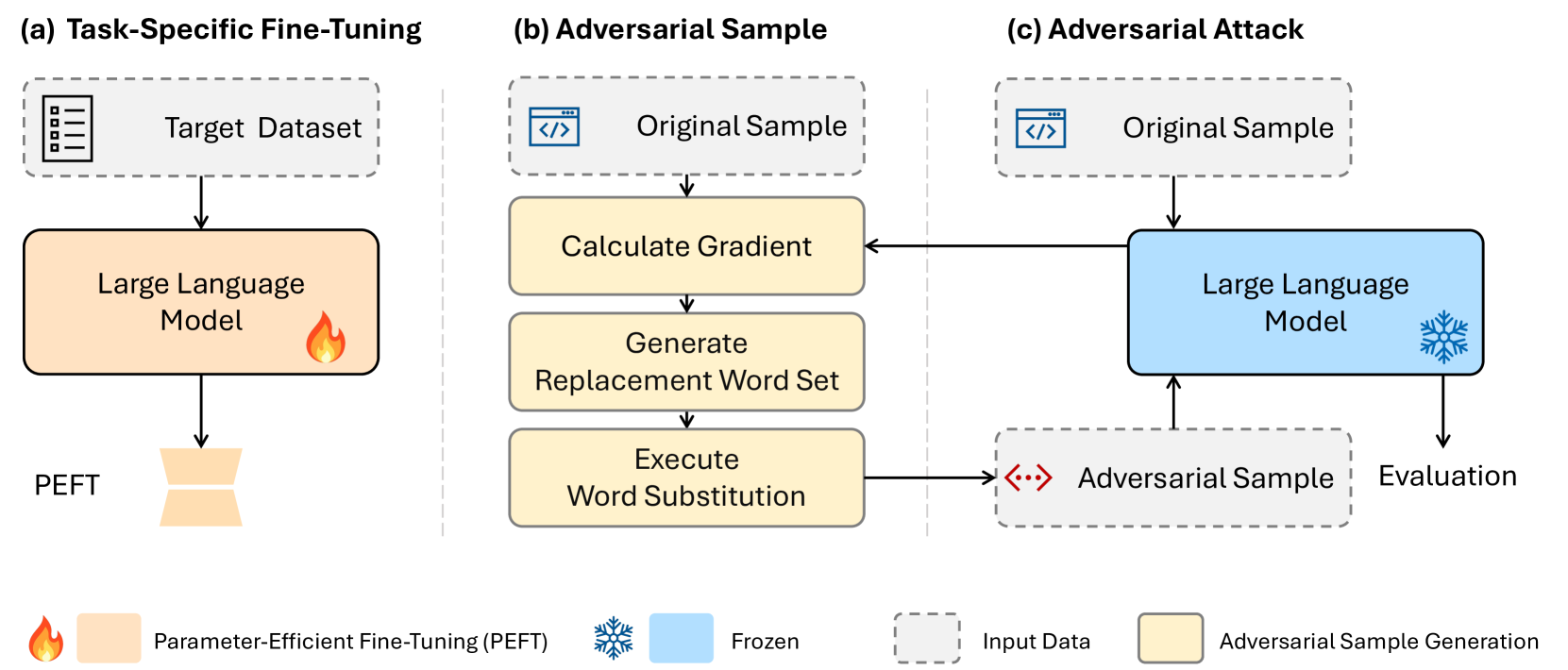
Assessing Adversarial Robustness of Large Language Models: An Empirical Study
Zeyu Yang, Zhao Meng, Xiaochen Zheng, Roger Wattenhofer
Large Language Models (LLMs) have revolutionized natural language processing, but their robustness against adversarial attacks remains a critical concern. We presents a novel white-box style attack approach that exposes vulnerabilities in leading open-source LLMs, including Llama, OPT, and T5. We assess the impact of model size, structure, and fine-tuning strategies on their resistance to adversarial perturbations. Our comprehensive evaluation across five diverse text classification tasks establishes a new benchmark for LLM robustness. The findings of this study have far-reaching implications for the reliable deployment of LLMs in real-world applications and contribute to the advancement of trustworthy AI systems.
Read more9/16/2024

0
Exploring Scaling Trends in LLM Robustness
Nikolaus Howe, Micha{l} Zajac, Ian McKenzie, Oskar Hollinsworth, Tom Tseng, Pierre-Luc Bacon, Adam Gleave
Language model capabilities predictably improve from scaling a model's size and training data. Motivated by this, increasingly large language models have been trained, yielding an array of impressive capabilities. Yet these models are vulnerable to adversarial prompts, such as jailbreaks that hijack models to perform undesired behaviors, posing a significant risk of misuse. Prior work indicates that computer vision models become more robust with model and data scaling, raising the question: does language model robustness also improve with scale? We study this question empirically, finding that larger models respond substantially better to adversarial training, but there is little to no benefit from model scale in the absence of explicit defenses.
Read more7/29/2024