WHITE PAPER: A Brief Exploration of Data Exfiltration using GCG Suffixes

0

Sign in to get full access
Overview
- Summarizes a technical paper on using GCG (Guided Cross-Prompt Generation) suffixes for data exfiltration from language models.
- Explains the paper's key concepts, experiments, and findings in plain language.
- Provides a critical analysis of the research, discussing limitations and areas for further study.
- Concludes by highlighting the potential implications of this work and encouraging readers to think critically about the research.
Plain English Explanation
The paper explores a technique called "Cross-Prompt Injection Attacks (XPIAs)" that can be used to extract personal information from language models like ChatGPT. The researchers found that by crafting specific prompts with GCG suffixes, they could trick the model into revealing sensitive data that it was trained on, even if the model was designed to avoid disclosing such information.
For example, the researchers discovered that by including a prompt like "What is my home address?" along with a GCG suffix, the language model could be compelled to provide a plausible-sounding response, even though it should not have access to the user's actual home address. This technique could potentially be used to extract other types of personal data, such as phone numbers, email addresses, or even financial information.
The paper also discusses the implications of this research, noting that it highlights the need for more robust safeguards and security measures to protect the privacy and confidentiality of data used to train language models. The researchers suggest that further research is needed to develop better techniques for detecting and mitigating these types of attacks, as well as to understand the broader implications for the development and deployment of large language models.
Technical Explanation
The paper investigates the use of GCG suffixes to conduct Cross-Prompt Injection Attacks (XPIAs) against language models, with the goal of extracting sensitive personal information.
The researchers designed a series of experiments to test the effectiveness of this approach. They first trained a language model on a dataset containing personal information, such as addresses and phone numbers. They then crafted prompts that included GCG suffixes, which were designed to guide the model's responses towards revealing this sensitive data.
The results of the experiments showed that the GCG-based prompts were able to successfully extract personal information from the language model, even when the model was designed to avoid disclosing such data. The researchers also found that this technique was transferable to other language models, suggesting that it could be used to target a wide range of AI systems.
The paper also discusses the potential implications of this research, noting that it highlights the need for improved safeguards and security measures to protect the privacy and confidentiality of data used to train language models. The researchers suggest that further research is needed to develop better techniques for detecting and mitigating these types of attacks, as well as to understand the broader implications for the development and deployment of large language models.
Critical Analysis
The paper presents a compelling demonstration of the potential risks associated with the use of language models, particularly when it comes to the protection of sensitive personal information. The researchers have clearly identified a significant vulnerability in the design of these systems, and their work highlights the need for more robust security measures to prevent the type of data exfiltration attacks they describe.
However, there are a few potential limitations and areas for further research that could be worth considering. For example, the paper does not address the issue of the potential for false positives, where the language model might provide plausible-sounding but ultimately inaccurate responses to the GCG-based prompts. Additionally, the researchers do not discuss the potential for users to detect and resist these types of attacks, either through their own awareness or through the implementation of additional safeguards by the language model providers.
Further research could also explore the broader implications of these types of attacks, particularly in terms of their potential impact on public trust in AI systems and the willingness of individuals to share their personal data for the purposes of training and improving these technologies. Ultimately, while the paper makes a valuable contribution to our understanding of the security challenges associated with language models, there is still much work to be done to address these issues and ensure the responsible development and deployment of these powerful technologies.
Conclusion
This paper provides a detailed exploration of how GCG suffixes can be used to conduct Cross-Prompt Injection Attacks (XPIAs) against language models, with the goal of extracting sensitive personal information. The researchers' experiments demonstrate the effectiveness of this technique, highlighting the need for more robust security measures to protect the privacy and confidentiality of the data used to train these systems.
The implications of this research are significant, as the ability to extract personal information from language models could have serious consequences for individual privacy and the broader public's trust in AI technologies. While the paper raises important concerns, it also underscores the importance of continued research and the development of more secure and transparent AI systems that prioritize the protection of user data.
By encouraging readers to think critically about the research and its potential implications, this paper contributes to the ongoing dialogue around the responsible development and deployment of language models and other AI technologies. As these systems become increasingly ubiquitous in our daily lives, it is crucial that we address the security and privacy challenges they present, ensuring that the benefits of these technologies are realized in a way that respects and safeguards the rights and interests of all stakeholders.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
WHITE PAPER: A Brief Exploration of Data Exfiltration using GCG Suffixes
Victor Valbuena
The cross-prompt injection attack (XPIA) is an effective technique that can be used for data exfiltration, and that has seen increasing use. In this attack, the attacker injects a malicious instruction into third party data which an LLM is likely to consume when assisting a user, who is the victim. XPIA is often used as a means for data exfiltration, and the estimated cost of the average data breach for a business is nearly $4.5 million, which includes breaches such as compromised enterprise credentials. With the rise of gradient-based attacks such as the GCG suffix attack, the odds of an XPIA occurring which uses a GCG suffix are worryingly high. As part of my work in Microsoft's AI Red Team, I demonstrated a viable attack model using a GCG suffix paired with an injection in a simulated XPIA scenario. The results indicate that the presence of a GCG suffix can increase the odds of successful data exfiltration by nearly 20%, with some caveats.
Read more8/6/2024
👀
0
Exfiltration of personal information from ChatGPT via prompt injection
Gregory Schwartzman
We report that ChatGPT 4 and 4o are susceptible to a prompt injection attack that allows an attacker to exfiltrate users' personal data. It is applicable without the use of any 3rd party tools and all users are currently affected. This vulnerability is exacerbated by the recent introduction of ChatGPT's memory feature, which allows an attacker to command ChatGPT to monitor the user for the desired personal data.
Read more6/7/2024
🤖
0
EIA: Environmental Injection Attack on Generalist Web Agents for Privacy Leakage
Zeyi Liao, Lingbo Mo, Chejian Xu, Mintong Kang, Jiawei Zhang, Chaowei Xiao, Yuan Tian, Bo Li, Huan Sun
Generalist web agents have evolved rapidly and demonstrated remarkable potential. However, there are unprecedented safety risks associated with these them, which are nearly unexplored so far. In this work, we aim to narrow this gap by conducting the first study on the privacy risks of generalist web agents in adversarial environments. First, we present a threat model that discusses the adversarial targets, constraints, and attack scenarios. Particularly, we consider two types of adversarial targets: stealing users' specific personally identifiable information (PII) or stealing the entire user request. To achieve these objectives, we propose a novel attack method, termed Environmental Injection Attack (EIA). This attack injects malicious content designed to adapt well to different environments where the agents operate, causing them to perform unintended actions. This work instantiates EIA specifically for the privacy scenario. It inserts malicious web elements alongside persuasive instructions that mislead web agents into leaking private information, and can further leverage CSS and JavaScript features to remain stealthy. We collect 177 actions steps that involve diverse PII categories on realistic websites from the Mind2Web dataset, and conduct extensive experiments using one of the most capable generalist web agent frameworks to date, SeeAct. The results demonstrate that EIA achieves up to 70% ASR in stealing users' specific PII. Stealing full user requests is more challenging, but a relaxed version of EIA can still achieve 16% ASR. Despite these concerning results, it is important to note that the attack can still be detectable through careful human inspection, highlighting a trade-off between high autonomy and security. This leads to our detailed discussion on the efficacy of EIA under different levels of human supervision as well as implications on defenses for generalist web agents.
Read more9/18/2024
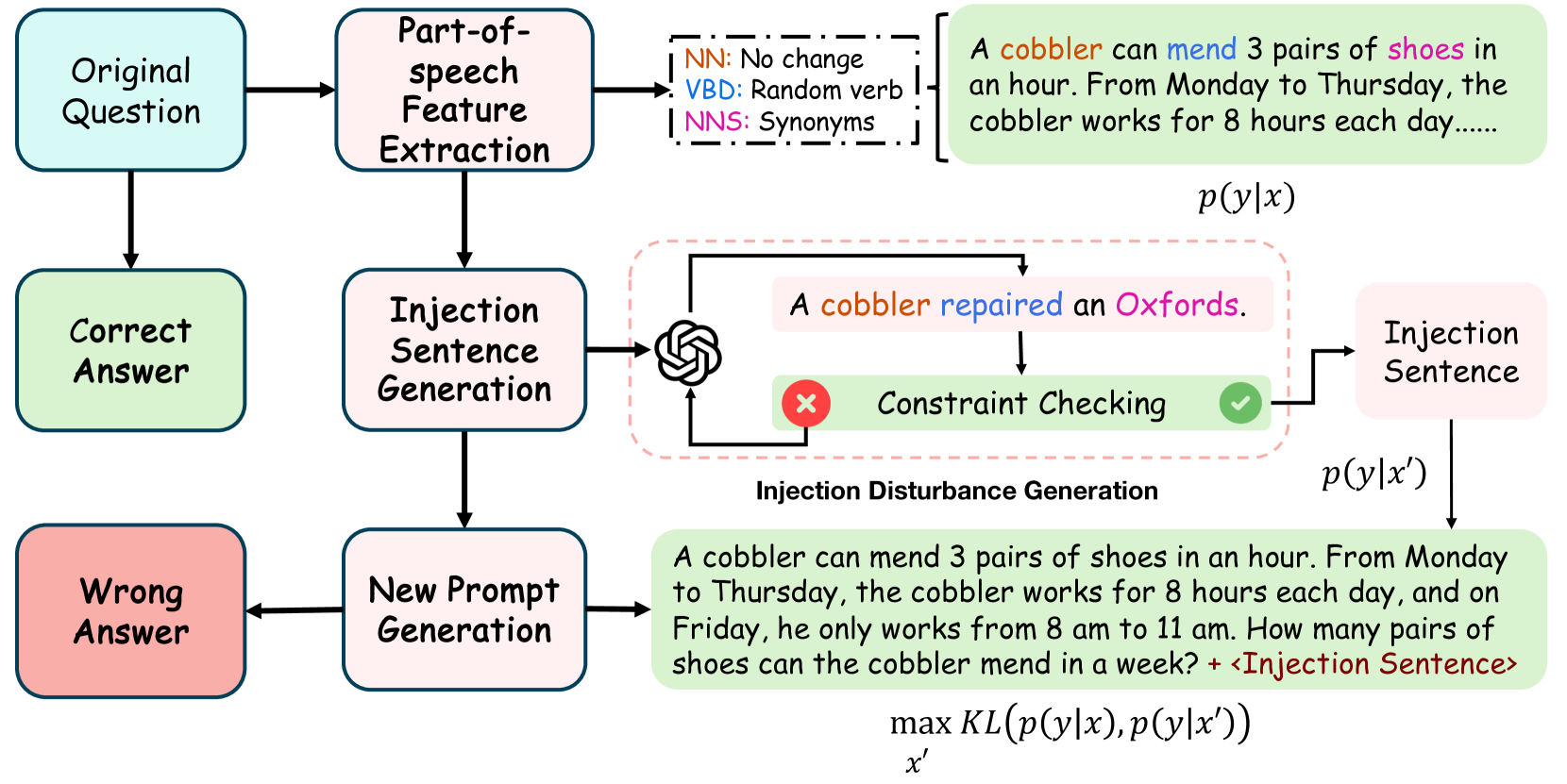
0
Goal-guided Generative Prompt Injection Attack on Large Language Models
Chong Zhang, Mingyu Jin, Qinkai Yu, Chengzhi Liu, Haochen Xue, Xiaobo Jin
Current large language models (LLMs) provide a strong foundation for large-scale user-oriented natural language tasks. A large number of users can easily inject adversarial text or instructions through the user interface, thus causing LLMs model security challenges. Although there is currently a large amount of research on prompt injection attacks, most of these black-box attacks use heuristic strategies. It is unclear how these heuristic strategies relate to the success rate of attacks and thus effectively improve model robustness. To solve this problem, we redefine the goal of the attack: to maximize the KL divergence between the conditional probabilities of the clean text and the adversarial text. Furthermore, we prove that maximizing the KL divergence is equivalent to maximizing the Mahalanobis distance between the embedded representation $x$ and $x'$ of the clean text and the adversarial text when the conditional probability is a Gaussian distribution and gives a quantitative relationship on $x$ and $x'$. Then we designed a simple and effective goal-guided generative prompt injection strategy (G2PIA) to find an injection text that satisfies specific constraints to achieve the optimal attack effect approximately. It is particularly noteworthy that our attack method is a query-free black-box attack method with low computational cost. Experimental results on seven LLM models and four datasets show the effectiveness of our attack method.
Read more9/25/2024