Wicked Oddities: Selectively Poisoning for Effective Clean-Label Backdoor Attacks

0

Sign in to get full access
Overview
- This paper presents a new type of backdoor attack called "Wicked Oddities" that can bypass existing defense mechanisms.
- The attack selectively poisons a small subset of the training data to create a backdoor that is difficult to detect.
- The backdoor can be triggered by "oddities" in the input, such as slightly modified pixels, that are imperceptible to humans.
- The authors demonstrate the effectiveness of this attack on various models and datasets, including CIFAR-10, ImageNet, and TinyImageNet.
Plain English Explanation
The paper introduces a new type of attack called "Wicked Oddities" that can be used to secretly manipulate the behavior of AI models. The key idea is to make small, almost imperceptible changes to a small subset of the training data used to teach the AI. These changes create a "backdoor" that can be triggered by specific, hard-to-detect patterns in the input.
For example, the AI might be trained on images of dogs and cats, but the attacker could secretly modify a few of the dog images in a way that's barely noticeable to humans. When the AI is later shown an image of a dog with that specific modification, it will mistakenly classify it as a cat, even though the image looks normal to a person. This backdoor can be very difficult to detect, as it only affects a small portion of the training data.
The paper demonstrates that this "Wicked Oddities" attack can work against a variety of AI models and datasets, including common benchmarks like CIFAR-10, ImageNet, and TinyImageNet. The authors show that this attack can bypass existing defense mechanisms that are designed to detect and mitigate other types of backdoor attacks.
Technical Explanation
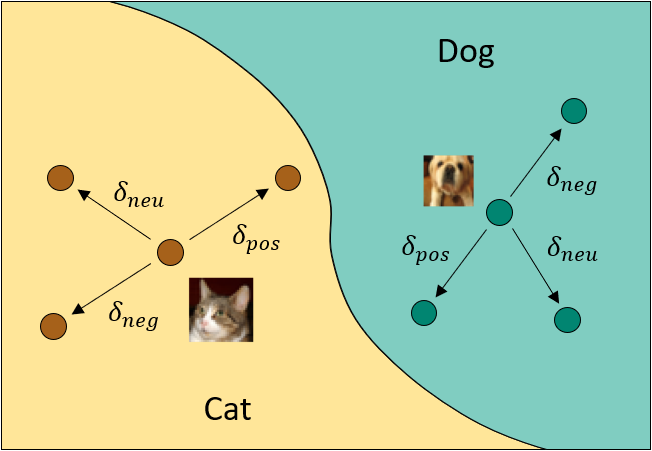
The key innovation of the "Wicked Oddities" attack is the selective poisoning of a small subset of the training data. Rather than modifying all (or a large portion) of the training samples, the attackers only target a carefully chosen subset. This makes the backdoor much harder to detect, as it doesn't significantly impact the overall performance of the model on the clean (unmodified) test data.
The authors propose a optimization-based approach to identify the most effective subset of training samples to poison. They formulate the problem as a constrained optimization problem, where the goal is to find the minimal set of training samples that, when modified, will result in the most effective backdoor. This optimization problem is solved using gradient-based techniques.
The authors evaluate their "Wicked Oddities" attack on a range of datasets and model architectures, including CIFAR-10, ImageNet, and TinyImageNet. They demonstrate that the attack can achieve high success rates while being nearly imperceptible to existing defense mechanisms, such as model-agnostic clean-label backdoor mitigation and partial training isolation.
Critical Analysis
One potential limitation of the "Wicked Oddities" attack is that it requires the attacker to have access to the training data and the ability to modify it. In a real-world scenario, this may not always be feasible. Additionally, the authors acknowledge that their optimization-based approach to selecting the poisoned subset of training samples may not be scalable to very large datasets.
Another concern is the potential for the "Wicked Oddities" attack to be used maliciously, as it can be difficult to detect and mitigate. The authors note that further research is needed to develop more robust defense mechanisms that can reliably identify and neutralize such selective poisoning attacks.
It's also important to consider the broader implications of this type of attack on the trustworthiness and reliability of AI systems. As research on backdoor attacks continues to evolve, it underscores the need for rigorous testing, auditing, and security measures to ensure the integrity of AI models, especially in critical applications.
Conclusion
The "Wicked Oddities" attack presented in this paper represents a significant advancement in the field of backdoor attacks on AI systems. By selectively poisoning a small subset of the training data, the attackers can create a backdoor that is highly effective yet extremely difficult to detect and mitigate.
The implications of this research are profound, as it highlights the importance of developing robust defense mechanisms and securing the entire AI supply chain, from data collection to model deployment. As the use of AI continues to expand, it is crucial that the research community and industry work together to address these emerging security challenges and ensure the trustworthiness of AI-powered systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Wicked Oddities: Selectively Poisoning for Effective Clean-Label Backdoor Attacks
Quang H. Nguyen, Nguyen Ngoc-Hieu, The-Anh Ta, Thanh Nguyen-Tang, Kok-Seng Wong, Hoang Thanh-Tung, Khoa D. Doan
Deep neural networks are vulnerable to backdoor attacks, a type of adversarial attack that poisons the training data to manipulate the behavior of models trained on such data. Clean-label attacks are a more stealthy form of backdoor attacks that can perform the attack without changing the labels of poisoned data. Early works on clean-label attacks added triggers to a random subset of the training set, ignoring the fact that samples contribute unequally to the attack's success. This results in high poisoning rates and low attack success rates. To alleviate the problem, several supervised learning-based sample selection strategies have been proposed. However, these methods assume access to the entire labeled training set and require training, which is expensive and may not always be practical. This work studies a new and more practical (but also more challenging) threat model where the attacker only provides data for the target class (e.g., in face recognition systems) and has no knowledge of the victim model or any other classes in the training set. We study different strategies for selectively poisoning a small set of training samples in the target class to boost the attack success rate in this setting. Our threat model poses a serious threat in training machine learning models with third-party datasets, since the attack can be performed effectively with limited information. Experiments on benchmark datasets illustrate the effectiveness of our strategies in improving clean-label backdoor attacks.
Read more7/17/2024
0
Poisoning-based Backdoor Attacks for Arbitrary Target Label with Positive Triggers
Binxiao Huang, Jason Chun Lok, Chang Liu, Ngai Wong
Poisoning-based backdoor attacks expose vulnerabilities in the data preparation stage of deep neural network (DNN) training. The DNNs trained on the poisoned dataset will be embedded with a backdoor, making them behave well on clean data while outputting malicious predictions whenever a trigger is applied. To exploit the abundant information contained in the input data to output label mapping, our scheme utilizes the network trained from the clean dataset as a trigger generator to produce poisons that significantly raise the success rate of backdoor attacks versus conventional approaches. Specifically, we provide a new categorization of triggers inspired by the adversarial technique and develop a multi-label and multi-payload Poisoning-based backdoor attack with Positive Triggers (PPT), which effectively moves the input closer to the target label on benign classifiers. After the classifier is trained on the poisoned dataset, we can generate an input-label-aware trigger to make the infected classifier predict any given input to any target label with a high possibility. Under both dirty- and clean-label settings, we show empirically that the proposed attack achieves a high attack success rate without sacrificing accuracy across various datasets, including SVHN, CIFAR10, GTSRB, and Tiny ImageNet. Furthermore, the PPT attack can elude a variety of classical backdoor defenses, proving its effectiveness.
Read more5/10/2024

0
Towards Clean-Label Backdoor Attacks in the Physical World
Thinh Dao, Cuong Chi Le, Khoa D Doan, Kok-Seng Wong
Deep Neural Networks (DNNs) are vulnerable to backdoor poisoning attacks, with most research focusing on digital triggers, special patterns digitally added to test-time inputs to induce targeted misclassification. In contrast, physical triggers, which are natural objects within a physical scene, have emerged as a desirable alternative since they enable real-time backdoor activations without digital manipulation. However, current physical attacks require that poisoned inputs have incorrect labels, making them easily detectable upon human inspection. In this paper, we collect a facial dataset of 21,238 images with 7 common accessories as triggers and use it to study the threat of clean-label backdoor attacks in the physical world. Our study reveals two findings. First, the success of physical attacks depends on the poisoning algorithm, physical trigger, and the pair of source-target classes. Second, although clean-label poisoned samples preserve ground-truth labels, their perceptual quality could be seriously degraded due to conspicuous artifacts in the images. Such samples are also vulnerable to statistical filtering methods because they deviate from the distribution of clean samples in the feature space. To address these issues, we propose replacing the standard $ell_infty$ regularization with a novel pixel regularization and feature regularization that could enhance the imperceptibility of poisoned samples without compromising attack performance. Our study highlights accidental backdoor activations as a key limitation of clean-label physical backdoor attacks. This happens when unintended objects or classes accidentally cause the model to misclassify as the target class.
Read more7/30/2024

0
Model-agnostic clean-label backdoor mitigation in cybersecurity environments
Giorgio Severi, Simona Boboila, John Holodnak, Kendra Kratkiewicz, Rauf Izmailov, Alina Oprea
The training phase of machine learning models is a delicate step, especially in cybersecurity contexts. Recent research has surfaced a series of insidious training-time attacks that inject backdoors in models designed for security classification tasks without altering the training labels. With this work, we propose new techniques that leverage insights in cybersecurity threat models to effectively mitigate these clean-label poisoning attacks, while preserving the model utility. By performing density-based clustering on a carefully chosen feature subspace, and progressively isolating the suspicious clusters through a novel iterative scoring procedure, our defensive mechanism can mitigate the attacks without requiring many of the common assumptions in the existing backdoor defense literature. To show the generality of our proposed mitigation, we evaluate it on two clean-label model-agnostic attacks on two different classic cybersecurity data modalities: network flows classification and malware classification, using gradient boosting and neural network models.
Read more7/12/2024