WildChat: 1M ChatGPT Interaction Logs in the Wild

0
👨🏫
Sign in to get full access
Overview
- This paper describes the creation of a new dataset called WildChat, which contains over 1 million conversations between users and the chatbot GPT-4.
- The researchers collected these conversations by offering free access to ChatGPT in exchange for users' consent to anonymously record their chat transcripts and request headers.
- The dataset is designed to help researchers study how people actually use chatbots like GPT-4 in the real world, as opposed to controlled experiments.
Plain English Explanation
The researchers behind this paper wanted to study how people use chatbots like GPT-4 and ChatGPT in their day-to-day lives. While these chatbots are now used by millions of people, there hasn't been much public data available that shows how they're actually being used.
To address this, the researchers offered free access to ChatGPT, but with the caveat that they would anonymously record the chat transcripts and some basic information about the users, like their location and the devices they were using. Over 1 million users agreed to this, and the researchers compiled all of this data into a new dataset called WildChat.
Compared to other chatbot interaction datasets, WildChat stands out because it contains a much more diverse set of user prompts and use cases, including some that could be considered "toxic" or inappropriate. It also covers a wider range of languages and provides additional demographic information about the users. This makes WildChat a valuable resource for researchers who want to study how people really use these chatbots and develop better ways to ensure they're used responsibly.
Technical Explanation
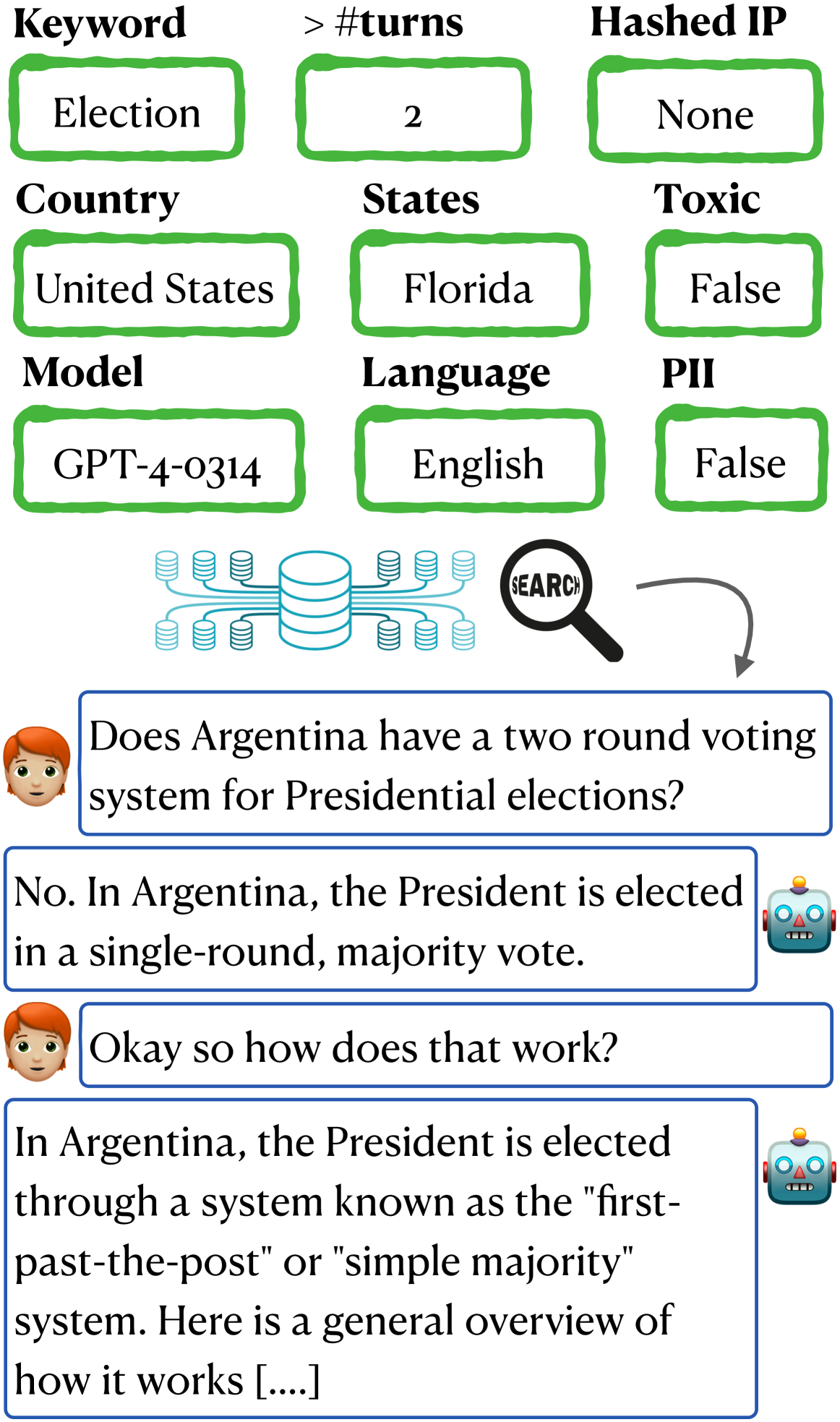
The researchers created the WildChat dataset by offering free access to ChatGPT in exchange for users' consent to anonymously record their chat transcripts and request headers. This resulted in a corpus of over 1 million user-ChatGPT conversations, comprising more than 2.5 million interaction turns.
Compared to other popular user-chatbot interaction datasets, the researchers found that WildChat offers the most diverse set of user prompts, contains the largest number of languages, and presents the richest variety of potentially toxic use-cases. In addition to the timestamped chat transcripts, the dataset is also enriched with demographic data, including state, country, and hashed IP addresses, as well as request headers. This additional information allows for more detailed analysis of user behaviors across different geographical regions and temporal dimensions.
The researchers demonstrate the potential utility of the WildChat dataset in fine-tuning instruction-following models, which could be used to improve the linguistic capabilities of chatbots and enhance their ability to provide useful advice.
Critical Analysis
One potential limitation of the WildChat dataset is that the researchers relied on users' voluntary consent to collect the data, which could introduce some selection bias. It's possible that the users who agreed to participate may not be representative of the general population of chatbot users.
Additionally, the dataset's inclusion of potentially toxic use-cases raises ethical concerns about the responsible use of such data. While the researchers argue that this information is valuable for studying and addressing these issues, there is a risk that the dataset could be misused or misinterpreted.
Further research may be needed to better understand the demographic and behavioral patterns within the WildChat dataset, as well as to explore the long-term implications of large-scale chatbot usage on individuals and society.
Conclusion
The WildChat dataset represents an important step forward in the study of how people actually use chatbots like GPT-4 and ChatGPT in their daily lives. By capturing a diverse range of user prompts and interactions, the dataset provides researchers with a valuable resource for understanding the real-world power and limitations of these technologies. While there are some ethical and methodological considerations to address, the potential insights that can be drawn from WildChat could help inform the development of more responsible and effective chatbot systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👨🏫
0
WildChat: 1M ChatGPT Interaction Logs in the Wild
Wenting Zhao, Xiang Ren, Jack Hessel, Claire Cardie, Yejin Choi, Yuntian Deng
Chatbots such as GPT-4 and ChatGPT are now serving millions of users. Despite their widespread use, there remains a lack of public datasets showcasing how these tools are used by a population of users in practice. To bridge this gap, we offered free access to ChatGPT for online users in exchange for their affirmative, consensual opt-in to anonymously collect their chat transcripts and request headers. From this, we compiled WildChat, a corpus of 1 million user-ChatGPT conversations, which consists of over 2.5 million interaction turns. We compare WildChat with other popular user-chatbot interaction datasets, and find that our dataset offers the most diverse user prompts, contains the largest number of languages, and presents the richest variety of potentially toxic use-cases for researchers to study. In addition to timestamped chat transcripts, we enrich the dataset with demographic data, including state, country, and hashed IP addresses, alongside request headers. This augmentation allows for more detailed analysis of user behaviors across different geographical regions and temporal dimensions. Finally, because it captures a broad range of use cases, we demonstrate the dataset's potential utility in fine-tuning instruction-following models. WildChat is released at https://wildchat.allen.ai under AI2 ImpACT Licenses.
Read more5/3/2024
0
WildVis: Open Source Visualizer for Million-Scale Chat Logs in the Wild
Yuntian Deng, Wenting Zhao, Jack Hessel, Xiang Ren, Claire Cardie, Yejin Choi
The increasing availability of real-world conversation data offers exciting opportunities for researchers to study user-chatbot interactions. However, the sheer volume of this data makes manually examining individual conversations impractical. To overcome this challenge, we introduce WildVis, an interactive tool that enables fast, versatile, and large-scale conversation analysis. WildVis provides search and visualization capabilities in the text and embedding spaces based on a list of criteria. To manage million-scale datasets, we implemented optimizations including search index construction, embedding precomputation and compression, and caching to ensure responsive user interactions within seconds. We demonstrate WildVis' utility through three case studies: facilitating chatbot misuse research, visualizing and comparing topic distributions across datasets, and characterizing user-specific conversation patterns. WildVis is open-source and designed to be extendable, supporting additional datasets and customized search and visualization functionalities.
Read more9/10/2024
📊
0
Analyzing Chat Protocols of Novice Programmers Solving Introductory Programming Tasks with ChatGPT
Andreas Scholl, Daniel Schiffner, Natalie Kiesler
Large Language Models (LLMs) have taken the world by storm, and students are assumed to use related tools at a great scale. In this research paper we aim to gain an understanding of how introductory programming students chat with LLMs and related tools, e.g., ChatGPT-3.5. To address this goal, computing students at a large German university were motivated to solve programming exercises with the assistance of ChatGPT as part of their weekly introductory course exercises. Then students (n=213) submitted their chat protocols (with 2335 prompts in sum) as data basis for this analysis. The data was analyzed w.r.t. the prompts, frequencies, the chats' progress, contents, and other use pattern, which revealed a great variety of interactions, both potentially supportive and concerning. Learning about students' interactions with ChatGPT will help inform and align teaching practices and instructions for future introductory programming courses in higher education.
Read more5/30/2024
📊
0
ChatGPT in Data Visualization Education: A Student Perspective
Nam Wook Kim, Hyung-Kwon Ko, Grace Myers, Benjamin Bach
Unlike traditional educational chatbots that rely on pre-programmed responses, large-language model-driven chatbots, such as ChatGPT, demonstrate remarkable versatility to serve as a dynamic resource for addressing student needs from understanding advanced concepts to solving complex problems. This work explores the impact of such technology on student learning in an interdisciplinary, project-oriented data visualization course. Throughout the semester, students engaged with ChatGPT across four distinct projects, designing and implementing data visualizations using a variety of tools such as Tableau, D3, and Vega-lite. We collected conversation logs and reflection surveys after each assignment and conducted interviews with selected students to gain deeper insights into their experiences with ChatGPT. Our analysis examined the advantages and barriers of using ChatGPT, students' querying behavior, the types of assistance sought, and its impact on assignment outcomes and engagement. We discuss design considerations for an educational solution tailored for data visualization education, extending beyond ChatGPT's basic interface.
Read more8/20/2024