WoLF: Wide-scope Large Language Model Framework for CXR Understanding

0

Sign in to get full access
Overview
- This paper presents a "Wide-scope Large Language Model (WoLF) Framework" for improving the understanding and analysis of Chest X-Ray (CXR) medical images using large language models (LLMs).
- The researchers aim to leverage the powerful capabilities of LLMs, typically trained on vast amounts of text data, to enhance CXR interpretation and disease detection.
- The framework involves fine-tuning LLMs on CXR-specific datasets and tasks to enable the models to better understand radiological concepts and patterns.
- The key focus is on demonstrating how LLMs can be effectively adapted and applied to medical imaging domains like CXR analysis.
Plain English Explanation
The paper introduces a new framework called WoLF (Wide-scope Large Language Model Framework) that aims to harness the power of large language models (LLMs) to improve the understanding and analysis of chest X-ray (CXR) medical images. LLMs are AI models that have been trained on vast amounts of text data, allowing them to develop a deep understanding of language and general knowledge.
The researchers hypothesize that by fine-tuning these powerful LLMs on CXR-specific datasets and tasks, the models can learn to better recognize and interpret the radiological patterns and concepts relevant to CXR analysis. This could lead to improvements in tasks like disease detection, diagnosis, and overall CXR understanding.
The framework involves several steps to adapt the LLMs for CXR analysis. First, the LLMs are trained on large text corpora to build a strong foundation of general knowledge. Then, the models are fine-tuned on CXR-specific datasets, where they learn to associate the visual patterns in the X-ray images with the corresponding medical terminology and concepts. This fine-tuning process helps the LLMs develop a more specialized understanding of radiology that can be applied to real-world CXR analysis tasks.
By leveraging the rich knowledge and language understanding capabilities of LLMs, the WoLF framework aims to enhance the performance and interpretability of CXR analysis, potentially leading to more accurate disease detection and better-informed clinical decision-making.
Technical Explanation
The paper presents a novel framework called "WoLF: Wide-scope Large Language Model Framework for CXR Understanding" that leverages the capabilities of large language models (LLMs) to improve the analysis and interpretation of chest X-ray (CXR) medical images.
The key components of the WoLF framework are:
-
LLM Training: The researchers start with a pre-trained LLM, such as BERT or GPT, that has been trained on vast amounts of text data, allowing the model to develop a rich understanding of language and general knowledge.
-
CXR-specific Fine-tuning: The pre-trained LLM is then fine-tuned on CXR-specific datasets and tasks, such as disease classification or radiological report generation. This fine-tuning process enables the LLM to learn the specific medical terminology, concepts, and visual patterns relevant to CXR analysis.
-
Multimodal Fusion: The fine-tuned LLM is combined with a vision-based model, such as a convolutional neural network (CNN), to create a multimodal system that can process both the text and visual information in the CXR images.
-
Task-specific Optimization: The multimodal model is further optimized and fine-tuned on specific CXR-related tasks, such as disease detection, diagnosis, or report generation, to maximize its performance on these targeted applications.
The researchers evaluate the WoLF framework on various CXR-related tasks, including disease classification, report generation, and visual-semantic alignment. The results demonstrate that the WoLF framework outperforms standalone vision-based models and achieves state-of-the-art performance on these CXR understanding tasks.
The key insights from the study include the importance of leveraging the rich knowledge and language understanding capabilities of LLMs to enhance medical image analysis, as well as the effectiveness of the multimodal fusion approach in integrating textual and visual information for improved CXR understanding.
Critical Analysis
The paper presents a well-designed and thorough study on the application of large language models (LLMs) to chest X-ray (CXR) understanding. The researchers have carefully considered the limitations of standalone vision-based models and have effectively demonstrated the potential of the WoLF framework to leverage the strengths of LLMs to enhance CXR analysis.
One potential area for further investigation is the interpretability and explainability of the WoLF framework. While the multimodal fusion approach shows promising results, it would be valuable to explore methods that can provide more insights into how the LLM-based component contributes to the final decisions and how the textual and visual information are integrated to arrive at the predictions.
Additionally, the researchers could consider evaluating the WoLF framework on a wider range of CXR-related tasks, such as differential diagnosis, risk stratification, or longitudinal disease monitoring. Expanding the scope of the evaluation could further showcase the versatility and clinical relevance of the proposed framework.
Overall, the WoLF framework represents a significant step forward in the integration of powerful language models with medical imaging analysis, and the research team has made a valuable contribution to the field of computer-aided CXR understanding.
Conclusion
The "WoLF: Wide-scope Large Language Model Framework for CXR Understanding" paper introduces a novel approach to leveraging the capabilities of large language models (LLMs) to enhance the analysis and interpretation of chest X-ray (CXR) medical images. By fine-tuning pre-trained LLMs on CXR-specific datasets and tasks, the researchers have demonstrated the potential of these models to develop a deep understanding of radiological concepts and patterns, leading to improved performance on various CXR-related tasks.
The multimodal fusion of the fine-tuned LLMs with vision-based models further strengthens the framework's ability to integrate textual and visual information for more comprehensive CXR analysis. The reported results suggest that the WoLF framework can outperform standalone vision-based models and achieve state-of-the-art performance on CXR understanding tasks.
This research represents an important step forward in the integration of advanced language models with medical imaging analysis, paving the way for more accurate disease detection, better-informed clinical decision-making, and ultimately, improved patient outcomes. As the field continues to evolve, further exploration of the interpretability, scalability, and clinical applicability of the WoLF framework will be crucial in realizing its full potential.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
WoLF: Wide-scope Large Language Model Framework for CXR Understanding
Seil Kang, Donghyun Kim, Junhyeok Kim, Hyo Kyung Lee, Seong Jae Hwang
Significant methodological strides have been made toward Chest X-ray (CXR) understanding via modern vision-language models (VLMs), demonstrating impressive Visual Question Answering (VQA) and CXR report generation abilities. However, existing CXR understanding frameworks still possess several procedural caveats. (1) Previous methods solely use CXR reports, which are insufficient for comprehensive Visual Question Answering (VQA), especially when additional health-related data like medication history and prior diagnoses are needed. (2) Previous methods use raw CXR reports, which are often arbitrarily structured. While modern language models can understand various text formats, restructuring reports for clearer, organized anatomy-based information could enhance their usefulness. (3) Current evaluation methods for CXR-VQA primarily emphasize linguistic correctness, lacking the capability to offer nuanced assessments of the generated answers. In this work, to address the aforementioned caveats, we introduce WoLF, a Wide-scope Large Language Model Framework for CXR understanding. To resolve (1), we capture multi-faceted records of patients, which are utilized for accurate diagnoses in real-world clinical scenarios. Specifically, we adopt the Electronic Health Records (EHR) to generate instruction-following data suited for CXR understanding. Regarding (2), we enhance report generation performance by decoupling knowledge in CXR reports based on anatomical structure even within the attention step via masked attention. To address (3), we introduce an AI-evaluation protocol optimized for assessing the capabilities of LLM. Through extensive experimental validations, WoLF demonstrates superior performance over other models on MIMIC-CXR in the AI-evaluation arena about VQA (up to +9.47%p mean score) and by metrics about report generation (+7.3%p BLEU-1).
Read more4/1/2024
0
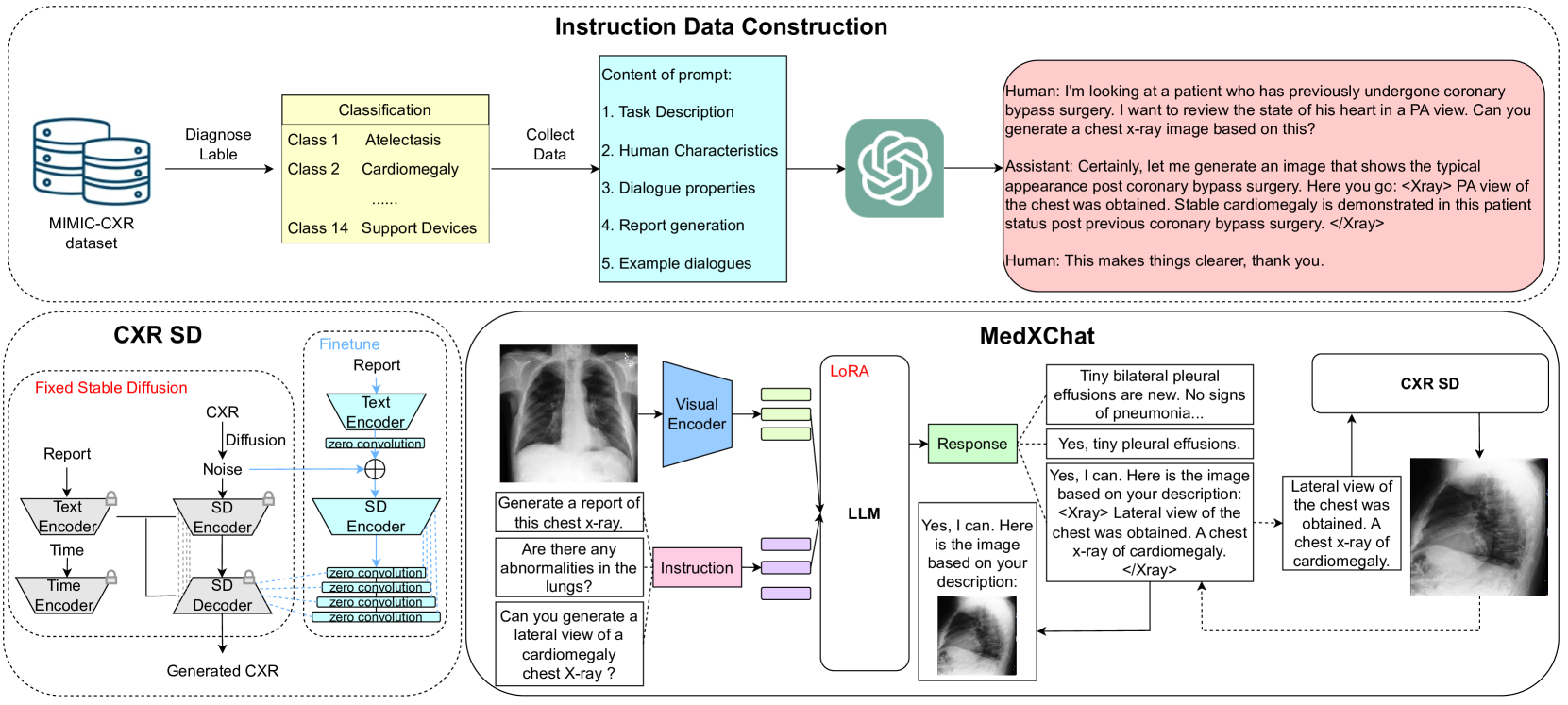
MedXChat: A Unified Multimodal Large Language Model Framework towards CXRs Understanding and Generation
Ling Yang, Zhanyu Wang, Zhenghao Chen, Xinyu Liang, Luping Zhou
Multimodal Large Language Models (MLLMs) have shown success in various general image processing tasks, yet their application in medical imaging is nascent, lacking tailored models. This study investigates the potential of MLLMs in improving the understanding and generation of Chest X-Rays (CXRs). We introduce MedXChat, a unified framework facilitating seamless interactions between medical assistants and users for diverse CXR tasks, including text report generation, visual question-answering (VQA), and Text-to-CXR generation. Our MLLMs using natural language as the input breaks task boundaries, maximally simplifying medical professional training by allowing diverse tasks within a single environment. For CXR understanding, we leverage powerful off-the-shelf visual encoders (e.g., ViT) and LLMs (e.g., mPLUG-Owl) to convert medical imagery into language-like features, and subsequently fine-tune our large pre-trained models for medical applications using a visual adapter network and a delta-tuning approach. For CXR generation, we introduce an innovative synthesis approach that utilizes instruction-following capabilities within the Stable Diffusion (SD) architecture. This technique integrates smoothly with the existing model framework, requiring no extra parameters, thereby maintaining the SD's generative strength while also bestowing upon it the capacity to render fine-grained medical images with high fidelity. Through comprehensive experiments, our model demonstrates exceptional cross-task adaptability, displaying adeptness across all three defined tasks. Our MedXChat model and the instruction dataset utilized in this research will be made publicly available to encourage further exploration in the field.
Read more5/13/2024
0
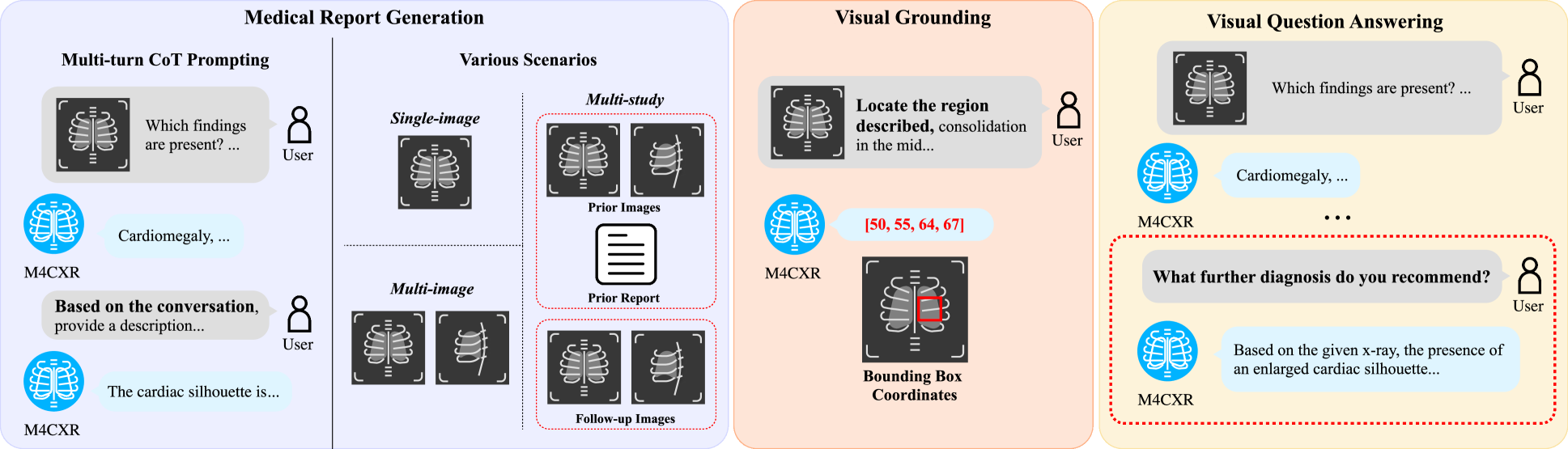
M4CXR: Exploring Multi-task Potentials of Multi-modal Large Language Models for Chest X-ray Interpretation
Jonggwon Park, Soobum Kim, Byungmu Yoon, Jihun Hyun, Kyoyun Choi
The rapid evolution of artificial intelligence, especially in large language models (LLMs), has significantly impacted various domains, including healthcare. In chest X-ray (CXR) analysis, previous studies have employed LLMs, but with limitations: either underutilizing the multi-tasking capabilities of LLMs or lacking clinical accuracy. This paper presents M4CXR, a multi-modal LLM designed to enhance CXR interpretation. The model is trained on a visual instruction-following dataset that integrates various task-specific datasets in a conversational format. As a result, the model supports multiple tasks such as medical report generation (MRG), visual grounding, and visual question answering (VQA). M4CXR achieves state-of-the-art clinical accuracy in MRG by employing a chain-of-thought prompting strategy, in which it identifies findings in CXR images and subsequently generates corresponding reports. The model is adaptable to various MRG scenarios depending on the available inputs, such as single-image, multi-image, and multi-study contexts. In addition to MRG, M4CXR performs visual grounding at a level comparable to specialized models and also demonstrates outstanding performance in VQA. Both quantitative and qualitative assessments reveal M4CXR's versatility in MRG, visual grounding, and VQA, while consistently maintaining clinical accuracy.
Read more8/30/2024

0
Beyond the Hype: A dispassionate look at vision-language models in medical scenario
Yang Nan, Huichi Zhou, Xiaodan Xing, Guang Yang
Recent advancements in Large Vision-Language Models (LVLMs) have demonstrated remarkable capabilities across diverse tasks, garnering significant attention in AI communities. However, their performance and reliability in specialized domains such as medicine remain insufficiently assessed. In particular, most assessments over-concentrate in evaluating VLMs based on simple Visual Question Answering (VQA) on multi-modality data, while ignoring the in-depth characteristic of LVLMs. In this study, we introduce RadVUQA, a novel Radiological Visual Understanding and Question Answering benchmark, to comprehensively evaluate existing LVLMs. RadVUQA mainly validates LVLMs across five dimensions: 1) Anatomical understanding, assessing the models' ability to visually identify biological structures; 2) Multimodal comprehension, which involves the capability of interpreting linguistic and visual instructions to produce desired outcomes; 3) Quantitative and spatial reasoning, evaluating the models' spatial awareness and proficiency in combining quantitative analysis with visual and linguistic information; 4) Physiological knowledge, measuring the models' capability to comprehend functions and mechanisms of organs and systems; and 5) Robustness, which assesses the models' capabilities against unharmonised and synthetic data. The results indicate that both generalized LVLMs and medical-specific LVLMs have critical deficiencies with weak multimodal comprehension and quantitative reasoning capabilities. Our findings reveal the large gap between existing LVLMs and clinicians, highlighting the urgent need for more robust and intelligent LVLMs. The code and dataset will be available after the acceptance of this paper.
Read more8/19/2024