Beyond the Hype: A dispassionate look at vision-language models in medical scenario

0

Sign in to get full access
Overview
- Vision-language models are large AI systems that can understand and generate text based on images
- These models have shown impressive performance on a range of tasks, including in the medical domain
- However, there are concerns about the hype and limitations surrounding the use of these models in medical scenarios
Plain English Explanation
Vision-language models are powerful AI systems that can understand and describe images using natural language. They have been applied to various medical tasks, such as generating radiological reports or assisting with surgical procedures.
While these models have demonstrated impressive capabilities, there are concerns about the hype and limitations surrounding their use in medical scenarios. The paper aims to provide a more objective and balanced assessment of the current state of vision-language models in the medical domain.
Technical Explanation
The paper discusses the use of vision-language models in medical scenarios, highlighting both their strengths and limitations. The authors analyze the performance of these models on a range of medical tasks, including question answering, report generation, and surgical assistance.
The paper emphasizes the need for a more nuanced understanding of the capabilities and limitations of these models, particularly in sensitive medical domains. The authors caution against the hype and overly enthusiastic claims often associated with these technologies, and instead call for a dispassionate and critical analysis of their real-world performance and potential risks.
Critical Analysis
The paper raises important points about the need to temper the hype surrounding vision-language models in medical scenarios. While these models have shown impressive capabilities, the authors rightly note that there are significant limitations and caveats that must be carefully considered.
For example, the authors highlight the potential for bias and inaccuracies in the models' outputs, which could have serious consequences in medical decision-making. They also emphasize the need for rigorous testing and evaluation before these models are deployed in real-world medical settings.
Overall, the paper presents a balanced and thoughtful perspective on the use of vision-language models in the medical domain. While acknowledging the potential benefits of these technologies, the authors encourage readers to think critically about their limitations and potential risks.
Conclusion
This paper provides a much-needed counterpoint to the hype and enthusiasm often surrounding the use of vision-language models in medical scenarios. By offering a more dispassionate and nuanced analysis, the authors encourage a more critical and responsible approach to the deployment of these powerful AI systems in sensitive medical domains.
As the use of vision-language models in healthcare continues to grow, this paper serves as an important reminder to carefully consider the limitations and potential risks associated with these technologies, and to strive for a balanced and evidence-based understanding of their capabilities and limitations.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Beyond the Hype: A dispassionate look at vision-language models in medical scenario
Yang Nan, Huichi Zhou, Xiaodan Xing, Guang Yang
Recent advancements in Large Vision-Language Models (LVLMs) have demonstrated remarkable capabilities across diverse tasks, garnering significant attention in AI communities. However, their performance and reliability in specialized domains such as medicine remain insufficiently assessed. In particular, most assessments over-concentrate in evaluating VLMs based on simple Visual Question Answering (VQA) on multi-modality data, while ignoring the in-depth characteristic of LVLMs. In this study, we introduce RadVUQA, a novel Radiological Visual Understanding and Question Answering benchmark, to comprehensively evaluate existing LVLMs. RadVUQA mainly validates LVLMs across five dimensions: 1) Anatomical understanding, assessing the models' ability to visually identify biological structures; 2) Multimodal comprehension, which involves the capability of interpreting linguistic and visual instructions to produce desired outcomes; 3) Quantitative and spatial reasoning, evaluating the models' spatial awareness and proficiency in combining quantitative analysis with visual and linguistic information; 4) Physiological knowledge, measuring the models' capability to comprehend functions and mechanisms of organs and systems; and 5) Robustness, which assesses the models' capabilities against unharmonised and synthetic data. The results indicate that both generalized LVLMs and medical-specific LVLMs have critical deficiencies with weak multimodal comprehension and quantitative reasoning capabilities. Our findings reveal the large gap between existing LVLMs and clinicians, highlighting the urgent need for more robust and intelligent LVLMs. The code and dataset will be available after the acceptance of this paper.
Read more8/19/2024
👁️
0
OmniMedVQA: A New Large-Scale Comprehensive Evaluation Benchmark for Medical LVLM
Yutao Hu, Tianbin Li, Quanfeng Lu, Wenqi Shao, Junjun He, Yu Qiao, Ping Luo
Large Vision-Language Models (LVLMs) have demonstrated remarkable capabilities in various multimodal tasks. However, their potential in the medical domain remains largely unexplored. A significant challenge arises from the scarcity of diverse medical images spanning various modalities and anatomical regions, which is essential in real-world medical applications. To solve this problem, in this paper, we introduce OmniMedVQA, a novel comprehensive medical Visual Question Answering (VQA) benchmark. This benchmark is collected from 73 different medical datasets, including 12 different modalities and covering more than 20 distinct anatomical regions. Importantly, all images in this benchmark are sourced from authentic medical scenarios, ensuring alignment with the requirements of the medical field and suitability for evaluating LVLMs. Through our extensive experiments, we have found that existing LVLMs struggle to address these medical VQA problems effectively. Moreover, what surprises us is that medical-specialized LVLMs even exhibit inferior performance to those general-domain models, calling for a more versatile and robust LVLM in the biomedical field. The evaluation results not only reveal the current limitations of LVLM in understanding real medical images but also highlight our dataset's significance. Our code with dataset are available at https://github.com/OpenGVLab/Multi-Modality-Arena.
Read more4/23/2024
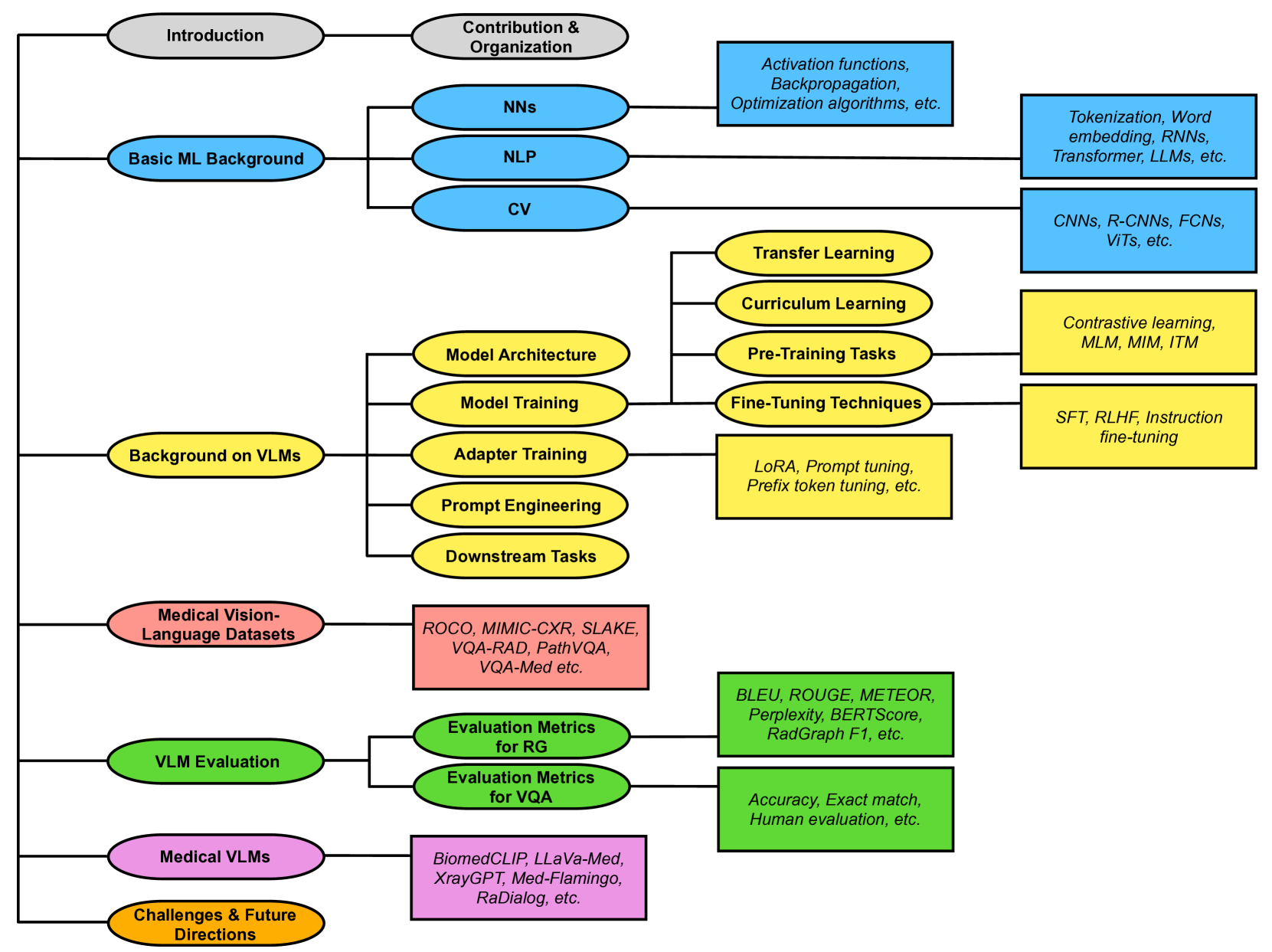
0
Vision-Language Models for Medical Report Generation and Visual Question Answering: A Review
Iryna Hartsock, Ghulam Rasool
Medical vision-language models (VLMs) combine computer vision (CV) and natural language processing (NLP) to analyze visual and textual medical data. Our paper reviews recent advancements in developing VLMs specialized for healthcare, focusing on models designed for medical report generation and visual question answering (VQA). We provide background on NLP and CV, explaining how techniques from both fields are integrated into VLMs to enable learning from multimodal data. Key areas we address include the exploration of medical vision-language datasets, in-depth analyses of architectures and pre-training strategies employed in recent noteworthy medical VLMs, and comprehensive discussion on evaluation metrics for assessing VLMs' performance in medical report generation and VQA. We also highlight current challenges and propose future directions, including enhancing clinical validity and addressing patient privacy concerns. Overall, our review summarizes recent progress in developing VLMs to harness multimodal medical data for improved healthcare applications.
Read more4/16/2024
👀
0
Fusion of Domain-Adapted Vision and Language Models for Medical Visual Question Answering
Cuong Nhat Ha, Shima Asaadi, Sanjeev Kumar Karn, Oladimeji Farri, Tobias Heimann, Thomas Runkler
Vision-language models, while effective in general domains and showing strong performance in diverse multi-modal applications like visual question-answering (VQA), struggle to maintain the same level of effectiveness in more specialized domains, e.g., medical. We propose a medical vision-language model that integrates large vision and language models adapted for the medical domain. This model goes through three stages of parameter-efficient training using three separate biomedical and radiology multi-modal visual and text datasets. The proposed model achieves state-of-the-art performance on the SLAKE 1.0 medical VQA (MedVQA) dataset with an overall accuracy of 87.5% and demonstrates strong performance on another MedVQA dataset, VQA-RAD, achieving an overall accuracy of 73.2%.
Read more4/26/2024