WorkBench: a Benchmark Dataset for Agents in a Realistic Workplace Setting

0
🔄
Sign in to get full access
Overview
- The authors introduce WorkBench, a benchmark dataset for evaluating AI agents' ability to execute common business tasks in a workplace setting.
- WorkBench contains a simulated environment with 5 databases, 26 tools, and 690 tasks representing real-world activities like sending emails and scheduling meetings.
- The tasks are challenging, requiring planning, tool selection, and often multiple actions to complete successfully.
- The benchmark uses outcome-centric evaluation, where the correct result is unique and unambiguous, allowing for automated assessment.
- The authors evaluate 5 existing AI agents on WorkBench and find they can complete as few as 3% (Llama2-70B) to 43% (GPT-4) of the tasks.
- The errors made by agents can lead to problematic outcomes, like sending emails to the wrong person.
- WorkBench reveals weaknesses in agents' ability to handle common workplace tasks, raising questions about their suitability for high-stakes business environments.
Plain English Explanation
The researchers have created a new test called WorkBench to see how well AI assistants can handle typical business tasks, like sending emails and scheduling meetings. WorkBench is a simulated workplace environment with a set of databases, tools, and 690 tasks that represent common work activities.
The tasks in WorkBench are designed to be challenging, requiring the AI agent to plan out a series of actions, choose the right tools, and complete the task correctly. If the agent makes a mistake, it could lead to the wrong outcome, like an email being sent to the wrong person.
The researchers tested 5 existing AI agents on WorkBench and found that they could only complete a small fraction of the tasks successfully - as low as 3% for one agent, and up to 43% for the best performer. This suggests that current AI assistants still struggle with the types of complex, multi-step activities that are common in real-world workplaces.
The WorkBench benchmark aims to provide a realistic and rigorous way to evaluate how capable AI systems are at handling the kinds of tasks that people encounter in their jobs every day. By revealing the limitations of existing agents, it raises important questions about whether these AI systems are ready to be deployed in high-stakes business settings.
Technical Explanation
The authors introduce WorkBench, a new benchmark dataset for evaluating the capabilities of AI agents in a workplace setting. WorkBench consists of a simulated environment with 5 databases, 26 tools, and 690 tasks that represent common business activities such as sending emails and scheduling meetings.
The tasks in WorkBench are designed to be challenging, requiring agents to engage in planning, tool selection, and often multiple actions to successfully complete them. The benchmark uses an outcome-centric evaluation approach, where the correct result for each task is unique and unambiguous, allowing for automated assessment of the agents' performance.
The authors evaluate the performance of 5 existing AI agents on WorkBench, including Llama2-70B and GPT-4. They find that the agents can complete as few as 3% (Llama2-70B) and up to 43% (GPT-4) of the tasks successfully. Importantly, the authors also observe that the agents' errors can lead to problematic outcomes, such as an email being sent to the wrong person.
The authors argue that WorkBench reveals significant weaknesses in the ability of current AI agents to handle common workplace tasks, raising concerns about their suitability for use in high-stakes business settings. The benchmark is publicly available as a free resource at https://github.com/olly-styles/WorkBench.
Critical Analysis
The WorkBench benchmark provides a valuable contribution to the field by creating a realistic and challenging evaluation environment for AI agents in a workplace setting. The authors' use of outcome-centric evaluation is a key strength, as it allows for a clear and unambiguous assessment of the agents' performance.
However, the paper does not provide detailed information on the specific tasks included in WorkBench, their level of complexity, or the criteria used to determine successful task completion. Additional details on these aspects would help readers better understand the scope and difficulty of the benchmark.
Furthermore, the paper does not address the potential biases or limitations in the dataset, such as the representation of different types of business activities or the diversity of the task descriptions. These factors could influence the generalizability of the findings to real-world workplace scenarios.
The authors' conclusion that the performance of existing AI agents raises concerns about their suitability for high-stakes business settings is well-founded, but the paper could have delved deeper into the specific implications and potential solutions. For example, it could have explored the types of enhancements or architectures that might be needed to address the identified weaknesses.
Overall, WorkBench is a valuable contribution to the field of AI evaluation, but the paper could have provided more detailed information and a more comprehensive discussion of the implications and future research directions.
Conclusion
The introduction of WorkBench, a benchmark dataset for evaluating AI agents' ability to execute common business tasks, represents an important step in assessing the readiness of these systems for real-world workplace settings. The authors' findings suggest that current AI agents struggle to complete a significant portion of the tasks in WorkBench, and that their errors can lead to problematic outcomes.
These results raise important questions about the suitability of existing AI systems for high-stakes business environments and highlight the need for continued research and development to address the identified weaknesses. By providing a free, publicly available resource, WorkBench offers a valuable tool for the broader AI research community to further explore these challenges and drive progress in the field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔄
0
WorkBench: a Benchmark Dataset for Agents in a Realistic Workplace Setting
Olly Styles, Sam Miller, Patricio Cerda-Mardini, Tanaya Guha, Victor Sanchez, Bertie Vidgen
We introduce WorkBench: a benchmark dataset for evaluating agents' ability to execute tasks in a workplace setting. WorkBench contains a sandbox environment with five databases, 26 tools, and 690 tasks. These tasks represent common business activities, such as sending emails and scheduling meetings. The tasks in WorkBench are challenging as they require planning, tool selection, and often multiple actions. If a task has been successfully executed, one (or more) of the database values may change. The correct outcome for each task is unique and unambiguous, which allows for robust, automated evaluation. We call this key contribution outcome-centric evaluation. We evaluate five existing ReAct agents on WorkBench, finding they successfully complete as few as 3% of tasks (Llama2-70B), and just 43% for the best-performing (GPT-4). We further find that agents' errors can result in the wrong action being taken, such as an email being sent to the wrong person. WorkBench reveals weaknesses in agents' ability to undertake common business activities, raising questions about their use in high-stakes workplace settings. WorkBench is publicly available as a free resource at https://github.com/olly-styles/WorkBench.
Read more5/3/2024
🛸
0
WorkArena++: Towards Compositional Planning and Reasoning-based Common Knowledge Work Tasks
L'eo Boisvert, Megh Thakkar, Maxime Gasse, Massimo Caccia, Thibault Le Sellier De Chezelles, Quentin Cappart, Nicolas Chapados, Alexandre Lacoste, Alexandre Drouin
The ability of large language models (LLMs) to mimic human-like intelligence has led to a surge in LLM-based autonomous agents. Though recent LLMs seem capable of planning and reasoning given user instructions, their effectiveness in applying these capabilities for autonomous task solving remains underexplored. This is especially true in enterprise settings, where automated agents hold the promise of a high impact. To fill this gap, we propose WorkArena++, a novel benchmark consisting of 682 tasks corresponding to realistic workflows routinely performed by knowledge workers. WorkArena++ is designed to evaluate the planning, problem-solving, logical/arithmetic reasoning, retrieval, and contextual understanding abilities of web agents. Our empirical studies across state-of-the-art LLMs and vision-language models (VLMs), as well as human workers, reveal several challenges for such models to serve as useful assistants in the workplace. In addition to the benchmark, we provide a mechanism to effortlessly generate thousands of ground-truth observation/action traces, which can be used for fine-tuning existing models. Overall, we expect this work to serve as a useful resource to help the community progress toward capable autonomous agents. The benchmark can be found at https://github.com/ServiceNow/WorkArena/tree/workarena-plus-plus.
Read more7/9/2024
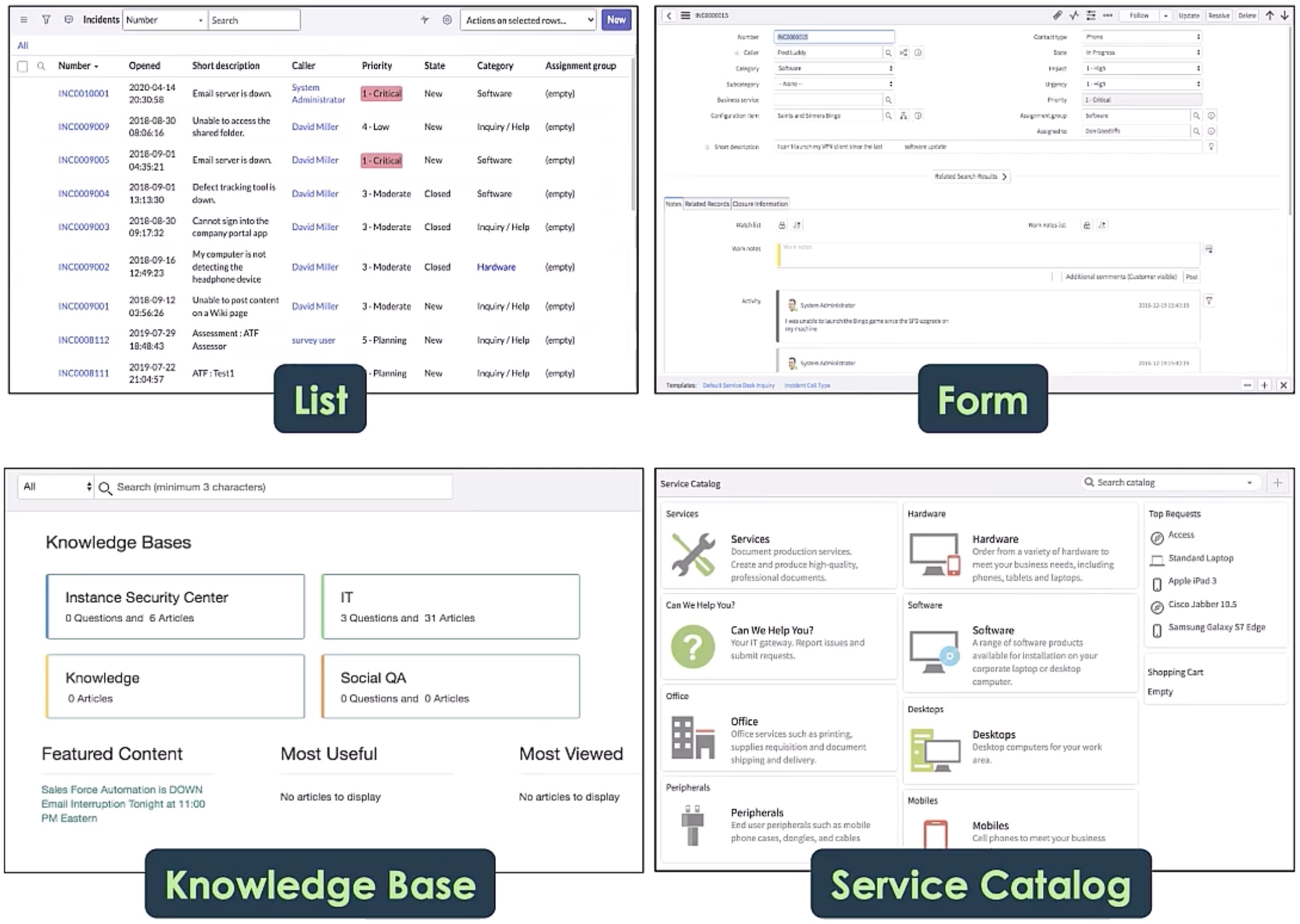
0
WorkArena: How Capable Are Web Agents at Solving Common Knowledge Work Tasks?
Alexandre Drouin, Maxime Gasse, Massimo Caccia, Issam H. Laradji, Manuel Del Verme, Tom Marty, L'eo Boisvert, Megh Thakkar, Quentin Cappart, David Vazquez, Nicolas Chapados, Alexandre Lacoste
We study the use of large language model-based agents for interacting with software via web browsers. Unlike prior work, we focus on measuring the agents' ability to perform tasks that span the typical daily work of knowledge workers utilizing enterprise software systems. To this end, we propose WorkArena, a remote-hosted benchmark of 33 tasks based on the widely-used ServiceNow platform. We also introduce BrowserGym, an environment for the design and evaluation of such agents, offering a rich set of actions as well as multimodal observations. Our empirical evaluation reveals that while current agents show promise on WorkArena, there remains a considerable gap towards achieving full task automation. Notably, our analysis uncovers a significant performance disparity between open and closed-source LLMs, highlighting a critical area for future exploration and development in the field.
Read more7/24/2024

0
New!CORE-Bench: Fostering the Credibility of Published Research Through a Computational Reproducibility Agent Benchmark
Zachary S. Siegel, Sayash Kapoor, Nitya Nagdir, Benedikt Stroebl, Arvind Narayanan
AI agents have the potential to aid users on a variety of consequential tasks, including conducting scientific research. To spur the development of useful agents, we need benchmarks that are challenging, but more crucially, directly correspond to real-world tasks of interest. This paper introduces such a benchmark, designed to measure the accuracy of AI agents in tackling a crucial yet surprisingly challenging aspect of scientific research: computational reproducibility. This task, fundamental to the scientific process, involves reproducing the results of a study using the provided code and data. We introduce CORE-Bench (Computational Reproducibility Agent Benchmark), a benchmark consisting of 270 tasks based on 90 scientific papers across three disciplines (computer science, social science, and medicine). Tasks in CORE-Bench consist of three difficulty levels and include both language-only and vision-language tasks. We provide an evaluation system to measure the accuracy of agents in a fast and parallelizable way, saving days of evaluation time for each run compared to a sequential implementation. We evaluated two baseline agents: the general-purpose AutoGPT and a task-specific agent called CORE-Agent. We tested both variants using two underlying language models: GPT-4o and GPT-4o-mini. The best agent achieved an accuracy of 21% on the hardest task, showing the vast scope for improvement in automating routine scientific tasks. Having agents that can reproduce existing work is a necessary step towards building agents that can conduct novel research and could verify and improve the performance of other research agents. We hope that CORE-Bench can improve the state of reproducibility and spur the development of future research agents.
Read more9/18/2024