World Model on Million-Length Video And Language With Blockwise RingAttention

1

Sign in to get full access
Overview
- This paper introduces a novel approach called "World Model on Million-Length Video And Language With RingAttention" for learning long-context language models.
- The proposed method aims to enable models to understand and reason about long-range dependencies in video and language data.
- The key innovation is the use of a "RingAttention" mechanism, which allows the model to efficiently attend to relevant context from across the entire input sequence.
Plain English Explanation
The researchers behind this work wanted to create AI models that can understand and reason about long videos and language that span many paragraphs or pages. Typical language models struggle with this because they can only focus on a small window of the input at a time.
The researchers' solution is a new type of attention mechanism they call "RingAttention." This allows the model to efficiently connect relevant information from across the entire input, no matter how long it is. For example, if you're reading a long story, the RingAttention mechanism would let the model understand how details early in the story are connected to events much later on.
By leveraging this RingAttention, the model is able to build a more complete "world model" that captures the rich context and relationships in long videos and language. This enables the model to engage in more sophisticated reasoning and understanding compared to standard language models.
Technical Explanation
The paper presents a two-stage training approach. In Stage I, the researchers train long-context language models using a novel RingAttention mechanism. This allows the models to efficiently attend to relevant information from across the entire input sequence, rather than being limited to a small local context window.
The RingAttention module works by arranging the input sequence in a circular "ring" structure. This enables each token to attend to relevant context from both the past and future relative to its position in the sequence. The researchers show this improves performance on long-range language tasks compared to standard attention.
In Stage II, the pre-trained long-context language model is fine-tuned on large-scale video and language datasets. This allows the model to build a comprehensive "world model" that can understand and reason about the rich context and relationships present in long video and language inputs.
The paper evaluates the trained models on a variety of long-range language and video understanding benchmarks, demonstrating significant performance improvements over prior approaches.
Critical Analysis
The paper presents a compelling approach for building more powerful language models that can handle long-form inputs. The RingAttention mechanism is a novel and promising technique that allows the model to maintain awareness of relevant context from across the entire input sequence.
One potential limitation is that the model may still struggle with very extreme long-range dependencies, as the circular structure of the RingAttention module has a fixed size. Exploring ways to make the receptive field truly unbounded could be an area for future research.
Additionally, the resource requirements of the two-stage training approach may limit its practicality for some applications. The authors mention the need for large-scale video and language datasets, which may not be readily available in all domains.
Overall, this work represents an important step forward in developing AI systems that can truly understand and reason about long-form, contextually rich data. Further advancements in this area could unlock powerful new capabilities for language and video understanding.
Conclusion
This paper introduces a novel approach called "World Model on Million-Length Video And Language With RingAttention" that enables AI models to understand and reason about long-form video and language data.
The key innovation is the use of a RingAttention mechanism, which allows the model to efficiently attend to relevant context from across the entire input sequence. This enables the model to build a comprehensive "world model" that captures rich contextual relationships, leading to improved performance on long-range language and video understanding tasks.
While the resource requirements of the training approach may be a practical limitation, this work represents an important advancement in developing AI systems with more sophisticated reasoning abilities. Further research in this area could yield transformative breakthroughs in natural language processing and video understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
1
World Model on Million-Length Video And Language With Blockwise RingAttention
Hao Liu, Wilson Yan, Matei Zaharia, Pieter Abbeel
Current language models fall short in understanding aspects of the world not easily described in words, and struggle with complex, long-form tasks. Video sequences offer valuable temporal information absent in language and static images, making them attractive for joint modeling with language. Such models could develop a understanding of both human textual knowledge and the physical world, enabling broader AI capabilities for assisting humans. However, learning from millions of tokens of video and language sequences poses challenges due to memory constraints, computational complexity, and limited datasets. To address these challenges, we curate a large dataset of diverse videos and books, utilize the Blockwise RingAttention technique to scalably train on long sequences, and gradually increase context size from 4K to 1M tokens. This paper makes the following contributions: (a) Largest context size neural network: We train one of the largest context size transformers on long video and language sequences, setting new benchmarks in difficult retrieval tasks and long video understanding. (b) Solutions for overcoming vision-language training challenges, including using masked sequence packing for mixing different sequence lengths, loss weighting to balance language and vision, and model-generated QA dataset for long sequence chat. (c) A highly-optimized implementation with RingAttention, Blockwise Transformers, masked sequence packing, and other key features for training on millions-length multimodal sequences. (d) Fully open-sourced a family of 7B parameter models capable of processing long text documents (LWM-Text, LWM-Text-Chat) and videos (LWM, LWM-Chat) of over 1M tokens. This work paves the way for training on massive datasets of long video and language to develop understanding of both human knowledge and the multimodal world, and broader capabilities.
Read more7/25/2024

0
LongVILA: Scaling Long-Context Visual Language Models for Long Videos
Fuzhao Xue, Yukang Chen, Dacheng Li, Qinghao Hu, Ligeng Zhu, Xiuyu Li, Yunhao Fang, Haotian Tang, Shang Yang, Zhijian Liu, Ethan He, Hongxu Yin, Pavlo Molchanov, Jan Kautz, Linxi Fan, Yuke Zhu, Yao Lu, Song Han
Long-context capability is critical for multi-modal foundation models, especially for long video understanding. We introduce LongVILA, a full-stack solution for long-context visual-language models by co-designing the algorithm and system. For model training, we upgrade existing VLMs to support long video understanding by incorporating two additional stages, i.e., long context extension and long supervised fine-tuning. However, training on long video is computationally and memory intensive. We introduce the long-context Multi-Modal Sequence Parallelism (MM-SP) system that efficiently parallelizes long video training and inference, enabling 2M context length training on 256 GPUs without any gradient checkpointing. LongVILA efficiently extends the number of video frames of VILA from 8 to 1024, improving the long video captioning score from 2.00 to 3.26 (out of 5), achieving 99.5% accuracy in 1400-frame (274k context length) video needle-in-a-haystack. LongVILA-8B demonstrates consistent accuracy improvements on long videos in the VideoMME benchmark as the number of frames increases. Besides, MM-SP is 2.1x - 5.7x faster than ring sequence parallelism and 1.1x - 1.4x faster than Megatron with context parallelism + tensor parallelism. Moreover, it seamlessly integrates with Hugging Face Transformers.
Read more8/22/2024

0
Long Context Transfer from Language to Vision
Peiyuan Zhang, Kaichen Zhang, Bo Li, Guangtao Zeng, Jingkang Yang, Yuanhan Zhang, Ziyue Wang, Haoran Tan, Chunyuan Li, Ziwei Liu
Video sequences offer valuable temporal information, but existing large multimodal models (LMMs) fall short in understanding extremely long videos. Many works address this by reducing the number of visual tokens using visual resamplers. Alternatively, in this paper, we approach this problem from the perspective of the language model. By simply extrapolating the context length of the language backbone, we enable LMMs to comprehend orders of magnitude more visual tokens without any video training. We call this phenomenon long context transfer and carefully ablate its properties. To effectively measure LMMs' ability to generalize to long contexts in the vision modality, we develop V-NIAH (Visual Needle-In-A-Haystack), a purely synthetic long vision benchmark inspired by the language model's NIAH test. Our proposed Long Video Assistant (LongVA) can process 2000 frames or over 200K visual tokens without additional complexities. With its extended context length, LongVA achieves state-of-the-art performance on Video-MME among 7B-scale models by densely sampling more input frames. Our work is open-sourced at https://github.com/EvolvingLMMs-Lab/LongVA.
Read more7/2/2024
27
Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention
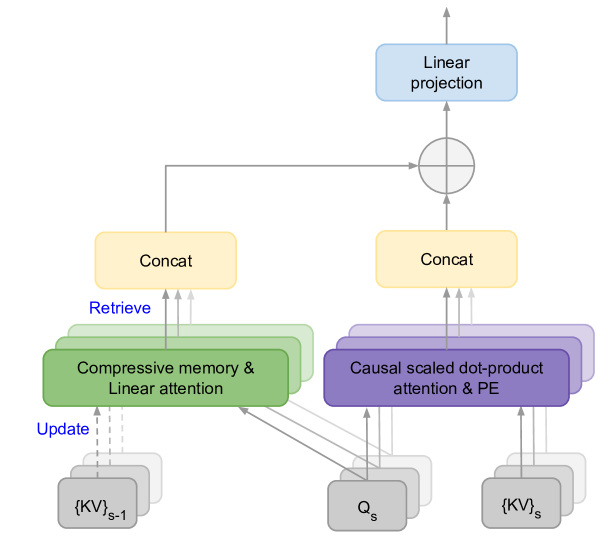
Tsendsuren Munkhdalai, Manaal Faruqui, Siddharth Gopal
This work introduces an efficient method to scale Transformer-based Large Language Models (LLMs) to infinitely long inputs with bounded memory and computation. A key component in our proposed approach is a new attention technique dubbed Infini-attention. The Infini-attention incorporates a compressive memory into the vanilla attention mechanism and builds in both masked local attention and long-term linear attention mechanisms in a single Transformer block. We demonstrate the effectiveness of our approach on long-context language modeling benchmarks, 1M sequence length passkey context block retrieval and 500K length book summarization tasks with 1B and 8B LLMs. Our approach introduces minimal bounded memory parameters and enables fast streaming inference for LLMs.
Read more8/13/2024