WorldCoder, a Model-Based LLM Agent: Building World Models by Writing Code and Interacting with the Environment
2402.12275
0
0
⚙️
Abstract
We give a model-based agent that builds a Python program representing its knowledge of the world based on its interactions with the environment. The world model tries to explain its interactions, while also being optimistic about what reward it can achieve. We define this optimism as a logical constraint between a program and a planner. We study our agent on gridworlds, and on task planning, finding our approach is more sample-efficient compared to deep RL, more compute-efficient compared to ReAct-style agents, and that it can transfer its knowledge across environments by editing its code.
Create account to get full access
Overview
- This paper presents a model-based agent that builds a Python program to represent its knowledge of the world based on interactions with the environment.
- The world model tries to explain the agent's interactions, while also being optimistic about the reward it can achieve.
- The authors define this optimism as a logical constraint between a program and a planner.
- The agent is evaluated on gridworlds and task planning, and the authors find it is more sample-efficient than deep reinforcement learning and more compute-efficient than ReAct-style agents.
- The agent can also transfer its knowledge across environments by editing its code.
Plain English Explanation
The researchers have created an AI agent that learns about the world by interacting with it and building a computer program to represent what it has learned. This program, or "world model," tries to both explain the agent's past experiences and predict what rewards it can get in the future.
The key idea is that the agent is "optimistic" about what it can achieve, meaning the program it builds has a built-in drive to find the best possible outcomes. The researchers define this optimism as a logical constraint that links the program to the agent's planning process.
When tested on simple grid-based environments and more complex task planning problems, this agent performs better than standard deep reinforcement learning approaches in terms of how efficiently it learns, and it uses less computational power than other program-building AI agents like ReAct.
Importantly, the agent can also take the code it has written and adapt it to work in new environments, rather than having to start from scratch. This ability to transfer its knowledge across environments by editing its code is a promising direction for building more generalizable AI agents that can apply what they've learned in one setting to perform well in others.
Technical Explanation
The key components of this approach are:
- A model-based agent that constructs a Python program to represent its understanding of the world based on interactions with the environment.
- A "world model" that tries to both explain the agent's past experiences and predict the rewards it can achieve in the future.
- A definition of "optimism" as a logical constraint that links the program representation to the agent's planning process, giving it a drive to find the best possible outcomes.
In experiments, the agent was evaluated on simple gridworld environments as well as more complex task planning problems. The results show the agent is more sample-efficient than deep reinforcement learning and more compute-efficient than ReAct-style agents that also build program representations.
Crucially, the agent can transfer its knowledge across environments by editing its code, rather than having to start from scratch in new settings. This is a promising step towards building more generalizable AI agents that can apply their learned knowledge and skills across a variety of domains.
Critical Analysis
The paper presents an intriguing approach to building AI agents that can learn about the world through interaction and represent that knowledge in the form of executable code. The authors' definition of "optimism" as a guiding principle for the agent's world model is an interesting theoretical concept that warrants further exploration.
However, the experiments conducted in this work are relatively limited in scope, focused primarily on gridworld and task planning environments. It remains to be seen how well this approach would scale to more complex, real-world scenarios that introduce additional challenges like partial observability, significant stochasticity, and rich sensory inputs.
Additionally, the paper does not provide much detail on the specific mechanisms by which the agent edits and transfers its code-based world model across environments. More insight into this process would be valuable for understanding the limitations and potential pitfalls of this knowledge transfer capability.
Overall, this research represents a promising step towards more agile, adaptable AI agents that can learn and reason about the world in sophisticated ways. Further investigation into the scalability, robustness, and generalization abilities of this approach could yield important insights for the field of artificial intelligence.
Conclusion
This paper presents an innovative model-based agent that builds a Python program to represent its understanding of the world, based on interactions with the environment. The key innovation is the definition of "optimism" as a logical constraint that guides the agent's world model to predict the best possible rewards.
Experimental results show this agent is more sample-efficient than deep reinforcement learning and more compute-efficient than other program-building approaches like ReAct. Crucially, the agent can also transfer its learned knowledge across environments by editing its code, rather than starting from scratch.
While the experiments are limited in scope, this research represents an important step towards building more flexible, adaptable AI agents that can learn, reason, and apply their knowledge in sophisticated ways. Further investigation into the scalability and generalization capabilities of this approach could yield valuable insights for the field of artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Generating Code World Models with Large Language Models Guided by Monte Carlo Tree Search
Nicola Dainese, Matteo Merler, Minttu Alakuijala, Pekka Marttinen
0
0
In this work we consider Code World Models, world models generated by a Large Language Model (LLM) in the form of Python code for model-based Reinforcement Learning (RL). Calling code instead of LLMs for planning has the advantages of being precise, reliable, interpretable, and extremely efficient. However, writing appropriate Code World Models requires the ability to understand complex instructions, to generate exact code with non-trivial logic and to self-debug a long program with feedback from unit tests and environment trajectories. To address these challenges, we propose Generate, Improve and Fix with Monte Carlo Tree Search (GIF-MCTS), a new code generation strategy for LLMs. To test our approach, we introduce the Code World Models Benchmark (CWMB), a suite of program synthesis and planning tasks comprised of 18 diverse RL environments paired with corresponding textual descriptions and curated trajectories. GIF-MCTS surpasses all baselines on the CWMB and two other benchmarks, and we show that the Code World Models synthesized with it can be successfully used for planning, resulting in model-based RL agents with greatly improved sample efficiency and inference speed.
5/27/2024
📈
Agent Planning with World Knowledge Model
Shuofei Qiao, Runnan Fang, Ningyu Zhang, Yuqi Zhu, Xiang Chen, Shumin Deng, Yong Jiang, Pengjun Xie, Fei Huang, Huajun Chen
0
0
Recent endeavors towards directly using large language models (LLMs) as agent models to execute interactive planning tasks have shown commendable results. Despite their achievements, however, they still struggle with brainless trial-and-error in global planning and generating hallucinatory actions in local planning due to their poor understanding of the ''real'' physical world. Imitating humans' mental world knowledge model which provides global prior knowledge before the task and maintains local dynamic knowledge during the task, in this paper, we introduce parametric World Knowledge Model (WKM) to facilitate agent planning. Concretely, we steer the agent model to self-synthesize knowledge from both expert and sampled trajectories. Then we develop WKM, providing prior task knowledge to guide the global planning and dynamic state knowledge to assist the local planning. Experimental results on three complex real-world simulated datasets with three state-of-the-art open-source LLMs, Mistral-7B, Gemma-7B, and Llama-3-8B, demonstrate that our method can achieve superior performance compared to various strong baselines. Besides, we analyze to illustrate that our WKM can effectively alleviate the blind trial-and-error and hallucinatory action issues, providing strong support for the agent's understanding of the world. Other interesting findings include: 1) our instance-level task knowledge can generalize better to unseen tasks, 2) weak WKM can guide strong agent model planning, and 3) unified WKM training has promising potential for further development. Code will be available at https://github.com/zjunlp/WKM.
5/24/2024
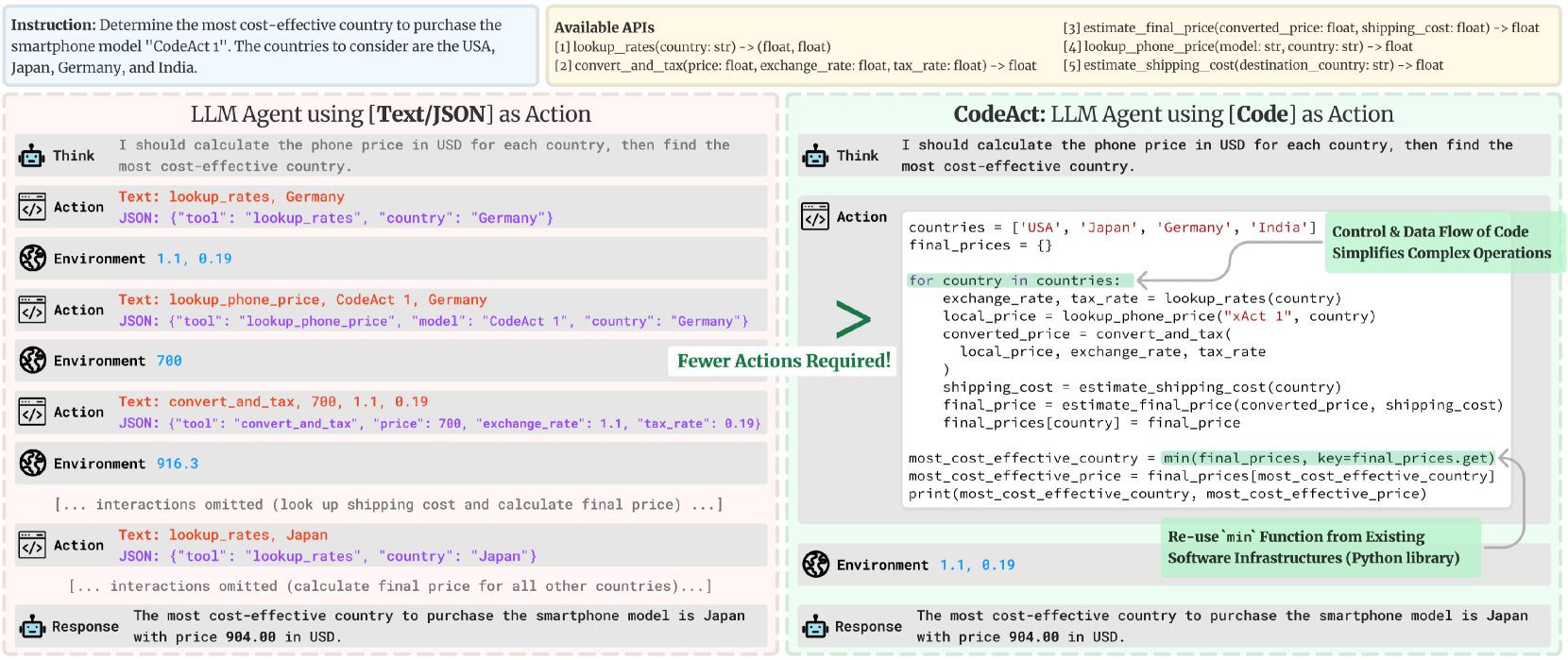
Executable Code Actions Elicit Better LLM Agents
Xingyao Wang, Yangyi Chen, Lifan Yuan, Yizhe Zhang, Yunzhu Li, Hao Peng, Heng Ji
0
0
Large Language Model (LLM) agents, capable of performing a broad range of actions, such as invoking tools and controlling robots, show great potential in tackling real-world challenges. LLM agents are typically prompted to produce actions by generating JSON or text in a pre-defined format, which is usually limited by constrained action space (e.g., the scope of pre-defined tools) and restricted flexibility (e.g., inability to compose multiple tools). This work proposes to use executable Python code to consolidate LLM agents' actions into a unified action space (CodeAct). Integrated with a Python interpreter, CodeAct can execute code actions and dynamically revise prior actions or emit new actions upon new observations through multi-turn interactions. Our extensive analysis of 17 LLMs on API-Bank and a newly curated benchmark shows that CodeAct outperforms widely used alternatives (up to 20% higher success rate). The encouraging performance of CodeAct motivates us to build an open-source LLM agent that interacts with environments by executing interpretable code and collaborates with users using natural language. To this end, we collect an instruction-tuning dataset CodeActInstruct that consists of 7k multi-turn interactions using CodeAct. We show that it can be used with existing data to improve models in agent-oriented tasks without compromising their general capability. CodeActAgent, finetuned from Llama2 and Mistral, is integrated with Python interpreter and uniquely tailored to perform sophisticated tasks (e.g., model training) using existing libraries and autonomously self-debug.
6/10/2024
⛏️
An Embodied Generalist Agent in 3D World
Jiangyong Huang, Silong Yong, Xiaojian Ma, Xiongkun Linghu, Puhao Li, Yan Wang, Qing Li, Song-Chun Zhu, Baoxiong Jia, Siyuan Huang
0
0
Leveraging massive knowledge from large language models (LLMs), recent machine learning models show notable successes in general-purpose task solving in diverse domains such as computer vision and robotics. However, several significant challenges remain: (i) most of these models rely on 2D images yet exhibit a limited capacity for 3D input; (ii) these models rarely explore the tasks inherently defined in 3D world, e.g., 3D grounding, embodied reasoning and acting. We argue these limitations significantly hinder current models from performing real-world tasks and approaching general intelligence. To this end, we introduce LEO, an embodied multi-modal generalist agent that excels in perceiving, grounding, reasoning, planning, and acting in the 3D world. LEO is trained with a unified task interface, model architecture, and objective in two stages: (i) 3D vision-language (VL) alignment and (ii) 3D vision-language-action (VLA) instruction tuning. We collect large-scale datasets comprising diverse object-level and scene-level tasks, which require considerable understanding of and interaction with the 3D world. Moreover, we meticulously design an LLM-assisted pipeline to produce high-quality 3D VL data. Through extensive experiments, we demonstrate LEO's remarkable proficiency across a wide spectrum of tasks, including 3D captioning, question answering, embodied reasoning, navigation and manipulation. Our ablative studies and scaling analyses further provide valuable insights for developing future embodied generalist agents. Code and data are available on project page.
5/10/2024