X-3D: Explicit 3D Structure Modeling for Point Cloud Recognition

0
👁️
Sign in to get full access
Overview
- Prior studies have focused on constructing relation vectors and embedding them into high-dimensional spaces to capture local structures.
- However, this implicit high-dimensional structure modeling approach does not adequately represent the local geometric structure of point clouds due to the absence of explicit structural information.
- The paper introduces X-3D, an explicit 3D structure modeling approach that captures local structural information and uses it to produce dynamic kernels with shared weights.
- This approach introduces effective geometric prior and reduces the disparity between the local structure of the embedding space and the original input point cloud, improving local feature extraction.
- The method achieves state-of-the-art performance on a variety of tasks, including segmentation, classification, and detection, with lower computational cost.
Plain English Explanation
The paper presents a new way to analyze and understand 3D point cloud data, which is a common format for representing 3D objects and scenes. Prior approaches have tried to capture the local structures within the point cloud by embedding them into high-dimensional spaces. However, this implicit approach has limitations in fully representing the true local geometric structure of the point cloud.
The researchers introduce a new method called X-3D that explicitly models the local 3D structure of the point cloud. Instead of just looking at individual points, X-3D considers the surrounding neighborhood of each point and uses this local structural information to generate dynamic "kernels" or filters that can be applied to the point cloud. This allows the method to better preserve the underlying geometry of the data, leading to improved performance on tasks like object classification, scene segmentation, and 3D detection.
Compared to previous techniques, X-3D is able to achieve state-of-the-art results on benchmark datasets, while also being computationally efficient. This suggests that explicitly modeling the 3D structure of point clouds is a powerful approach for extracting meaningful information and features from this type of data.
Technical Explanation
The paper introduces X-3D, an explicit 3D structure modeling approach for processing 3D point cloud data. Prior studies have primarily focused on constructing relation vectors for individual neighborhood points and embedding them into high-dimensional spaces to capture implicit local structures. However, the authors argue that this implicit high-dimensional structure modeling approach does not adequately represent the local geometric structure of point clouds due to the absence of explicit structural information.
To address this, X-3D captures the explicit local structural information within the input 3D space and employs it to produce dynamic kernels with shared weights for all neighborhood points within the current local region. This modeling approach introduces effective geometric prior and significantly diminishes the disparity between the local structure of the embedding space and the original input point cloud, thereby improving the extraction of local features.
The proposed method can be used in conjunction with a variety of existing point cloud processing techniques, and the authors demonstrate state-of-the-art performance on segmentation, classification, and detection tasks. Specifically, they report 90.7% accuracy on ScanObjectNN for classification, 79.2% on S3DIS 6 fold and 74.3% on S3DIS Area 5 for segmentation, 76.3% on ScanNetV2 for segmentation, and 64.5% mAP on SUN RGB-D and 69.0% mAP on ScanNetV2 for detection. Importantly, this improved performance is achieved with lower computational overhead compared to previous methods.
Critical Analysis
The paper provides a compelling approach to explicitly modeling the local 3D structure of point clouds, which addresses a key limitation of prior implicit high-dimensional embedding techniques. By leveraging the geometric information inherent in the 3D data, X-3D is able to better capture the underlying local structures and improve the performance on a variety of 3D perception tasks.
However, the paper does not extensively discuss the potential limitations or caveats of the proposed method. For example, it is unclear how well X-3D would perform on more complex or noisy 3D data, or how sensitive the approach is to variations in point cloud density or coverage. Additionally, the authors do not delve into potential tradeoffs in terms of memory or inference speed compared to other point cloud processing methods.
Further research could explore the robustness of X-3D to real-world conditions, as well as investigate ways to make the method more computationally efficient or generalizable to a wider range of 3D data and tasks. Comparative studies with other state-of-the-art techniques would also help contextualize the strengths and limitations of the proposed approach.
Conclusion
The X-3D method introduced in this paper represents a significant advancement in the field of 3D point cloud processing. By explicitly modeling the local geometric structure of the input data, the approach is able to extract more meaningful features and achieve state-of-the-art performance on a variety of 3D perception tasks, including segmentation, classification, and detection.
The ability to better capture the underlying 3D structure of the data has important implications for applications ranging from autonomous navigation and robotics to 3D reconstruction and virtual/augmented reality. As the field of 3D perception continues to evolve, techniques like X-3D that prioritize the preservation of geometric information will likely play an increasingly vital role in unlocking the full potential of 3D data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👁️
0
X-3D: Explicit 3D Structure Modeling for Point Cloud Recognition
Shuofeng Sun, Yongming Rao, Jiwen Lu, Haibin Yan
Numerous prior studies predominantly emphasize constructing relation vectors for individual neighborhood points and generating dynamic kernels for each vector and embedding these into high-dimensional spaces to capture implicit local structures. However, we contend that such implicit high-dimensional structure modeling approch inadequately represents the local geometric structure of point clouds due to the absence of explicit structural information. Hence, we introduce X-3D, an explicit 3D structure modeling approach. X-3D functions by capturing the explicit local structural information within the input 3D space and employing it to produce dynamic kernels with shared weights for all neighborhood points within the current local region. This modeling approach introduces effective geometric prior and significantly diminishes the disparity between the local structure of the embedding space and the original input point cloud, thereby improving the extraction of local features. Experiments show that our method can be used on a variety of methods and achieves state-of-the-art performance on segmentation, classification, detection tasks with lower extra computational cost, such as textbf{90.7%} on ScanObjectNN for classification, textbf{79.2%} on S3DIS 6 fold and textbf{74.3%} on S3DIS Area 5 for segmentation, textbf{76.3%} on ScanNetV2 for segmentation and textbf{64.5%} mAP , textbf{46.9%} mAP on SUN RGB-D and textbf{69.0%} mAP , textbf{51.1%} mAP on ScanNetV2 . Our code is available at href{https://github.com/sunshuofeng/X-3D}{https://github.com/sunshuofeng/X-3D}.
Read more4/24/2024
0
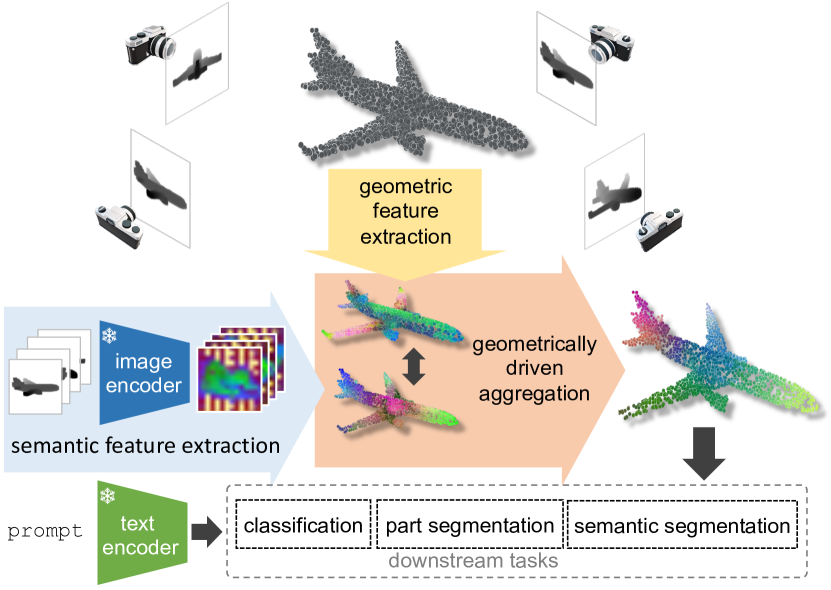
Geometrically-driven Aggregation for Zero-shot 3D Point Cloud Understanding
Guofeng Mei, Luigi Riz, Yiming Wang, Fabio Poiesi
Zero-shot 3D point cloud understanding can be achieved via 2D Vision-Language Models (VLMs). Existing strategies directly map Vision-Language Models from 2D pixels of rendered or captured views to 3D points, overlooking the inherent and expressible point cloud geometric structure. Geometrically similar or close regions can be exploited for bolstering point cloud understanding as they are likely to share semantic information. To this end, we introduce the first training-free aggregation technique that leverages the point cloud's 3D geometric structure to improve the quality of the transferred Vision-Language Models. Our approach operates iteratively, performing local-to-global aggregation based on geometric and semantic point-level reasoning. We benchmark our approach on three downstream tasks, including classification, part segmentation, and semantic segmentation, with a variety of datasets representing both synthetic/real-world, and indoor/outdoor scenarios. Our approach achieves new state-of-the-art results in all benchmarks. Our approach operates iteratively, performing local-to-global aggregation based on geometric and semantic point-level reasoning. Code and dataset are available at https://luigiriz.github.io/geoze-website/
Read more4/16/2024

0
CT3D++: Improving 3D Object Detection with Keypoint-induced Channel-wise Transformer
Hualian Sheng, Sijia Cai, Na Zhao, Bing Deng, Qiao Liang, Min-Jian Zhao, Jieping Ye
The field of 3D object detection from point clouds is rapidly advancing in computer vision, aiming to accurately and efficiently detect and localize objects in three-dimensional space. Current 3D detectors commonly fall short in terms of flexibility and scalability, with ample room for advancements in performance. In this paper, our objective is to address these limitations by introducing two frameworks for 3D object detection with minimal hand-crafted design. Firstly, we propose CT3D, which sequentially performs raw-point-based embedding, a standard Transformer encoder, and a channel-wise decoder for point features within each proposal. Secondly, we present an enhanced network called CT3D++, which incorporates geometric and semantic fusion-based embedding to extract more valuable and comprehensive proposal-aware information. Additionally, CT3D ++ utilizes a point-to-key bidirectional encoder for more efficient feature encoding with reduced computational cost. By replacing the corresponding components of CT3D with these novel modules, CT3D++ achieves state-of-the-art performance on both the KITTI dataset and the large-scale Way-mo Open Dataset. The source code for our frameworks will be made accessible at https://github.com/hlsheng1/CT3D-plusplus.
Read more6/13/2024

0
Sparse Points to Dense Clouds: Enhancing 3D Detection with Limited LiDAR Data
Aakash Kumar, Chen Chen, Ajmal Mian, Neils Lobo, Mubarak Shah
3D detection is a critical task that enables machines to identify and locate objects in three-dimensional space. It has a broad range of applications in several fields, including autonomous driving, robotics and augmented reality. Monocular 3D detection is attractive as it requires only a single camera, however, it lacks the accuracy and robustness required for real world applications. High resolution LiDAR on the other hand, can be expensive and lead to interference problems in heavy traffic given their active transmissions. We propose a balanced approach that combines the advantages of monocular and point cloud-based 3D detection. Our method requires only a small number of 3D points, that can be obtained from a low-cost, low-resolution sensor. Specifically, we use only 512 points, which is just 1% of a full LiDAR frame in the KITTI dataset. Our method reconstructs a complete 3D point cloud from this limited 3D information combined with a single image. The reconstructed 3D point cloud and corresponding image can be used by any multi-modal off-the-shelf detector for 3D object detection. By using the proposed network architecture with an off-the-shelf multi-modal 3D detector, the accuracy of 3D detection improves by 20% compared to the state-of-the-art monocular detection methods and 6% to 9% compare to the baseline multi-modal methods on KITTI and JackRabbot datasets.
Read more4/11/2024