X-Former: Unifying Contrastive and Reconstruction Learning for MLLMs

0

Sign in to get full access
Overview
- Introduces a new model called X-Former that unifies contrastive and reconstruction learning for multi-modal language learning models (MLLMs)
- Aims to address limitations of existing MLLMs by leveraging complementary strengths of contrastive and reconstruction learning
- Demonstrates state-of-the-art performance on various multi-modal benchmarks
Plain English Explanation
The paper presents a new model called X-Former that combines two key machine learning techniques - contrastive learning and reconstruction learning - to improve the performance of multi-modal language learning models (MLLMs).
MLLMs are AI systems that can understand and process information from multiple sources, like text, images, and videos. However, existing MLLMs have limitations - they may struggle to fully capture the relationships between different modalities or to generate high-quality outputs.
The researchers behind X-Former believed that by using both contrastive learning and reconstruction learning, their model could overcome these challenges. Contrastive learning helps the model learn meaningful representations by identifying similarities and differences between inputs. Reconstruction learning trains the model to accurately recreate the original input, which can improve its understanding of the data.
By combining these techniques, X-Former was able to achieve state-of-the-art performance on a variety of multi-modal benchmarks, demonstrating its ability to better comprehend and generate multi-modal content compared to existing MLLMs.
Technical Explanation
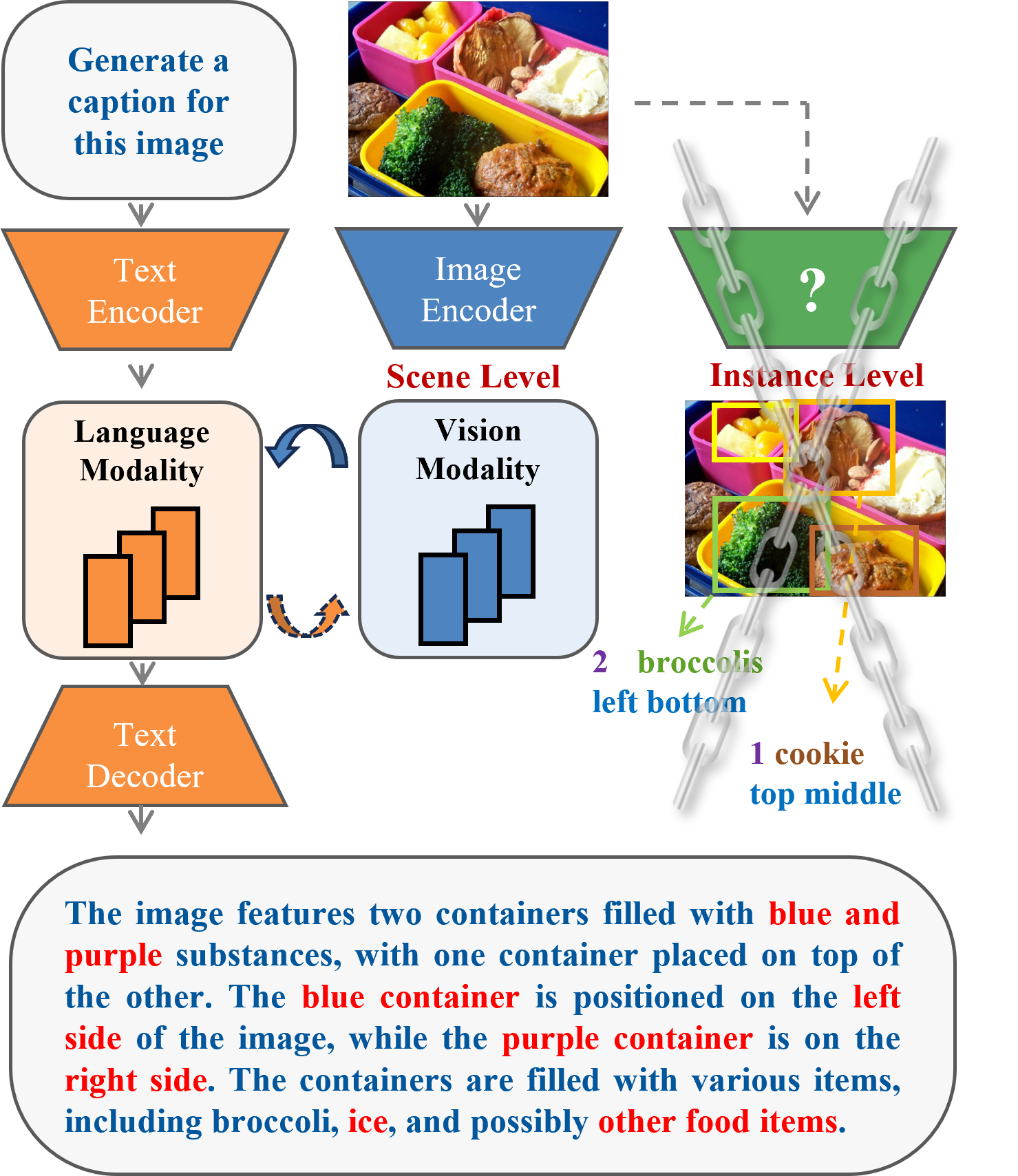
The key innovation of the X-Former model is its unified framework that integrates contrastive and reconstruction learning.
The contrastive learning component trains the model to distinguish between related and unrelated multi-modal input pairs, helping it learn powerful representations that capture the relationships between modalities. This is done by introducing a contrastive loss that encourages the model to assign higher similarity scores to "positive" pairs (e.g. an image and its corresponding caption) compared to "negative" pairs (e.g. an image and an unrelated caption).
The reconstruction learning component trains the model to accurately recreate the original input from its learned representations. This is achieved through a reconstruction loss that penalizes the model when its generated output deviates from the ground truth. This encourages the model to build a more comprehensive understanding of the input data.
The researchers demonstrate that by unifying these two complementary learning objectives, X-Former is able to outperform existing state-of-the-art MLLMs on a variety of tasks, including image-text retrieval, visual question answering, and multi-modal captioning. The model's success highlights the benefits of leveraging both contrastive and reconstruction learning for multi-modal AI systems.
Critical Analysis
The paper provides a compelling technical approach and demonstrates impressive empirical results. However, the authors acknowledge some limitations and areas for future work:
-
The current X-Former model is trained on specific multi-modal datasets, and its performance may not generalize as well to more diverse or noisier real-world data. Further research is needed to assess its robustness.
-
While the unified contrastive and reconstruction learning framework is a key contribution, the specific architectural choices and hyperparameter tuning used in the experiments are not explored in depth. Additional analysis of these design decisions could yield further insights.
-
The paper focuses primarily on evaluating X-Former's performance on standardized benchmarks. Exploring its practical applications and end-user benefits in real-world scenarios could strengthen the overall impact of the research.
Overall, the X-Former model represents an important step forward in multi-modal learning, but continued exploration of its limitations and potential extensions could further advance the field of multi-modal AI.
Conclusion
The X-Former paper introduces a novel unified framework that combines contrastive and reconstruction learning to improve the performance of multi-modal language learning models (MLLMs). By leveraging the complementary strengths of these two techniques, the X-Former model is able to achieve state-of-the-art results on a variety of multi-modal benchmarks.
This research highlights the potential benefits of integrating different machine learning approaches to build more capable and comprehensive multi-modal AI systems. As the use of multi-modal data becomes increasingly prevalent in fields like computer vision, natural language processing, and information retrieval, the X-Former model and similar approaches could have significant real-world impact.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
X-Former: Unifying Contrastive and Reconstruction Learning for MLLMs
Sirnam Swetha, Jinyu Yang, Tal Neiman, Mamshad Nayeem Rizve, Son Tran, Benjamin Yao, Trishul Chilimbi, Mubarak Shah
Recent advancements in Multimodal Large Language Models (MLLMs) have revolutionized the field of vision-language understanding by integrating visual perception capabilities into Large Language Models (LLMs). The prevailing trend in this field involves the utilization of a vision encoder derived from vision-language contrastive learning (CL), showing expertise in capturing overall representations while facing difficulties in capturing detailed local patterns. In this work, we focus on enhancing the visual representations for MLLMs by combining high-frequency and detailed visual representations, obtained through masked image modeling (MIM), with semantically-enriched low-frequency representations captured by CL. To achieve this goal, we introduce X-Former which is a lightweight transformer module designed to exploit the complementary strengths of CL and MIM through an innovative interaction mechanism. Specifically, X-Former first bootstraps vision-language representation learning and multimodal-to-multimodal generative learning from two frozen vision encoders, i.e., CLIP-ViT (CL-based) and MAE-ViT (MIM-based). It further bootstraps vision-to-language generative learning from a frozen LLM to ensure visual features from X-Former can be interpreted by the LLM. To demonstrate the effectiveness of our approach, we assess its performance on tasks demanding detailed visual understanding. Extensive evaluations indicate that X-Former excels in visual reasoning tasks involving both structural and semantic categories in the GQA dataset. Assessment on fine-grained visual perception benchmark further confirms its superior capabilities in visual understanding.
Read more7/22/2024

0
X-InstructBLIP: A Framework for aligning X-Modal instruction-aware representations to LLMs and Emergent Cross-modal Reasoning
Artemis Panagopoulou, Le Xue, Ning Yu, Junnan Li, Dongxu Li, Shafiq Joty, Ran Xu, Silvio Savarese, Caiming Xiong, Juan Carlos Niebles
Recent research has achieved significant advancements in visual reasoning tasks through learning image-to-language projections and leveraging the impressive reasoning abilities of Large Language Models (LLMs). This paper introduces an efficient and effective framework that integrates multiple modalities (images, 3D, audio and video) to a frozen LLM and demonstrates an emergent ability for cross-modal reasoning (2+ modality inputs). Our approach explores two distinct projection mechanisms: Q-Formers and Linear Projections (LPs). Through extensive experimentation across all four modalities on 16 benchmarks, we explore both methods and assess their adaptability in integrated and separate cross-modal reasoning. The Q-Former projection demonstrates superior performance in single modality scenarios and adaptability in joint versus discriminative reasoning involving two or more modalities. However, it exhibits lower generalization capabilities than linear projection in contexts where task-modality data are limited. To enable this framework, we devise a scalable pipeline that automatically generates high-quality, instruction-tuning datasets from readily available captioning data across different modalities, and contribute 24K QA data for audio and 250K QA data for 3D. To facilitate further research in cross-modal reasoning, we introduce the DisCRn (Discriminative Cross-modal Reasoning) benchmark comprising 9K audio-video QA samples and 28K image-3D QA samples that require the model to reason discriminatively across disparate input modalities.
Read more9/10/2024

1
Eyes Wide Shut? Exploring the Visual Shortcomings of Multimodal LLMs
Shengbang Tong, Zhuang Liu, Yuexiang Zhai, Yi Ma, Yann LeCun, Saining Xie
Is vision good enough for language? Recent advancements in multimodal models primarily stem from the powerful reasoning abilities of large language models (LLMs). However, the visual component typically depends only on the instance-level contrastive language-image pre-training (CLIP). Our research reveals that the visual capabilities in recent multimodal LLMs (MLLMs) still exhibit systematic shortcomings. To understand the roots of these errors, we explore the gap between the visual embedding space of CLIP and vision-only self-supervised learning. We identify ''CLIP-blind pairs'' - images that CLIP perceives as similar despite their clear visual differences. With these pairs, we construct the Multimodal Visual Patterns (MMVP) benchmark. MMVP exposes areas where state-of-the-art systems, including GPT-4V, struggle with straightforward questions across nine basic visual patterns, often providing incorrect answers and hallucinated explanations. We further evaluate various CLIP-based vision-and-language models and found a notable correlation between visual patterns that challenge CLIP models and those problematic for multimodal LLMs. As an initial effort to address these issues, we propose a Mixture of Features (MoF) approach, demonstrating that integrating vision self-supervised learning features with MLLMs can significantly enhance their visual grounding capabilities. Together, our research suggests visual representation learning remains an open challenge, and accurate visual grounding is crucial for future successful multimodal systems.
Read more4/26/2024
0
MR-MLLM: Mutual Reinforcement of Multimodal Comprehension and Vision Perception
Guanqun Wang, Xinyu Wei, Jiaming Liu, Ray Zhang, Yichi Zhang, Kevin Zhang, Maurice Chong, Shanghang Zhang
In recent years, multimodal large language models (MLLMs) have shown remarkable capabilities in tasks like visual question answering and common sense reasoning, while visual perception models have made significant strides in perception tasks, such as detection and segmentation. However, MLLMs mainly focus on high-level image-text interpretations and struggle with fine-grained visual understanding, and vision perception models usually suffer from open-world distribution shifts due to their limited model capacity. To overcome these challenges, we propose the Mutually Reinforced Multimodal Large Language Model (MR-MLLM), a novel framework that synergistically enhances visual perception and multimodal comprehension. First, a shared query fusion mechanism is proposed to harmonize detailed visual inputs from vision models with the linguistic depth of language models, enhancing multimodal comprehension and vision perception synergistically. Second, we propose the perception-enhanced cross-modal integration method, incorporating novel modalities from vision perception outputs, like object detection bounding boxes, to capture subtle visual elements, thus enriching the understanding of both visual and textual data. In addition, an innovative perception-embedded prompt generation mechanism is proposed to embed perceptual information into the language model's prompts, aligning the responses contextually and perceptually for a more accurate multimodal interpretation. Extensive experiments demonstrate MR-MLLM's superior performance in various multimodal comprehension and vision perception tasks, particularly those requiring corner case vision perception and fine-grained language comprehension.
Read more6/26/2024