XPrompt:Explaining Large Language Model's Generation via Joint Prompt Attribution
2405.20404
0
0
Abstract
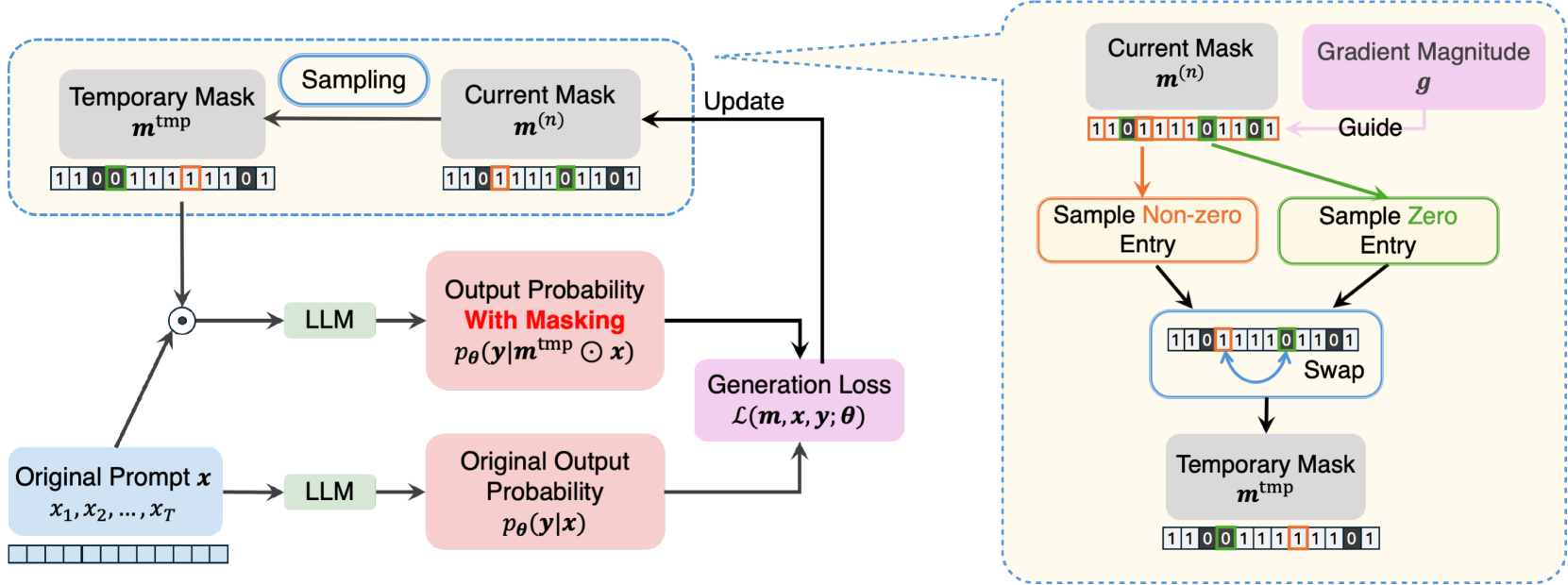
Large Language Models (LLMs) have demonstrated impressive performances in complex text generation tasks. However, the contribution of the input prompt to the generated content still remains obscure to humans, underscoring the necessity of elucidating and explaining the causality between input and output pairs. Existing works for providing prompt-specific explanation often confine model output to be classification or next-word prediction. Few initial attempts aiming to explain the entire language generation often treat input prompt texts independently, ignoring their combinatorial effects on the follow-up generation. In this study, we introduce a counterfactual explanation framework based on joint prompt attribution, XPrompt, which aims to explain how a few prompt texts collaboratively influences the LLM's complete generation. Particularly, we formulate the task of prompt attribution for generation interpretation as a combinatorial optimization problem, and introduce a probabilistic algorithm to search for the casual input combination in the discrete space. We define and utilize multiple metrics to evaluate the produced explanations, demonstrating both faithfulness and efficiency of our framework.
Create account to get full access
Overview
- This paper introduces XPrompt, a method for explaining the generation of large language models (LLMs) by attributing the output to different parts of the input prompt.
- XPrompt uses a novel joint prompt attribution approach to identify which components of the prompt contribute most to the model's output.
- The authors demonstrate the effectiveness of XPrompt on several language tasks, showing it can provide valuable insights into the inner workings of LLMs.
Plain English Explanation
Large language models (LLMs) like GPT-3 are powerful AI systems that can generate human-like text. However, it's often difficult to understand how these models arrive at their outputs. XPrompt: Explaining Large Language Model's Generation via Joint Prompt Attribution introduces a method called XPrompt that aims to shed light on this "black box" by attributing the model's generation to different parts of the input prompt.
The core idea behind XPrompt is to analyze the prompt and identify which components (e.g. specific words or phrases) most influenced the model's output. This is done through a novel "joint prompt attribution" approach that looks at how changes to the prompt affect the final text generation. By understanding which prompt elements are driving the model's behavior, researchers and users can gain valuable insights into how LLMs work and potentially improve their performance and interpretability.
The authors demonstrate XPrompt on several language tasks, showing that it can provide useful explanations of LLM generation. For example, XPrompt might reveal that a model relied more heavily on certain keywords or instructions in the prompt than others when generating its response. This type of information can help users better understand the model's reasoning and make more informed decisions about how to interact with it.
Overall, XPrompt represents an important step towards making large language models more transparent and interpretable. As LLMs become increasingly powerful and influential, developing techniques like this to peek inside the "black box" will be crucial for building trust and ensuring these systems are used responsibly.
Technical Explanation
XPrompt: Explaining Large Language Model's Generation via Joint Prompt Attribution introduces a novel method for attributing the generation of large language models (LLMs) to different components of the input prompt.
The key innovation of XPrompt is its use of a "joint prompt attribution" approach. Rather than looking at how individual prompt elements affect the model's output in isolation, XPrompt considers the joint influence of all prompt components. This allows it to capture more nuanced interactions and dependencies between different parts of the prompt.
Specifically, the XPrompt method works as follows:
- The model is first fine-tuned on a specific task using a training prompt.
- During inference, the input prompt is systematically perturbed by masking or modifying different prompt components.
- The changes in model output between the original and perturbed prompts are then used to compute an attribution score for each prompt element.
- These attribution scores indicate how much each part of the prompt contributed to the final generation.
The authors evaluate XPrompt on a range of language tasks, including text generation, question answering, and sentiment analysis. They show that XPrompt can provide valuable insights, surfacing which prompt components had the greatest impact on the model's outputs.
For example, in a summarization task, XPrompt might reveal that the model relied heavily on specific keywords or instructions in the prompt, rather than generating a completely novel summary. This information can help users understand the model's reasoning and potentially improve prompting strategies.
Overall, XPrompt: Explaining Large Language Model's Generation via Joint Prompt Attribution represents an important advance in the effort to make large language models more transparent and interpretable. Techniques like this will be essential as these powerful AI systems become more widely deployed and influential.
Critical Analysis
The XPrompt method introduced in this paper represents a valuable contribution to the field of large language model (LLM) interpretability. By providing a way to attribute an LLM's generation to different components of the input prompt, XPrompt offers users and researchers a window into the "black box" of these powerful AI systems.
One strength of the XPrompt approach is its ability to capture the joint influence of prompt elements, rather than just looking at individual prompt components in isolation. This allows for a more nuanced understanding of how LLMs respond to prompts and the complex interactions between different prompt features.
That said, the authors acknowledge several limitations of their work. For example, XPrompt may struggle to accurately attribute generation when there are strong dependencies or nonlinearities between prompt elements. Additionally, the method currently relies on systematic prompt perturbations, which can be computationally expensive for large or complex prompts.
Further research is needed to address these challenges and expand the capabilities of XPrompt. Potential avenues for future work include developing more efficient attribution algorithms, exploring the generalization of XPrompt to different model architectures and tasks, and investigating how prompt attribution relates to other interpretability techniques like layer visualization or attention analysis.
Overall, XPrompt: Explaining Large Language Model's Generation via Joint Prompt Attribution represents an important step forward in making large language models more transparent and trustworthy. As these models become increasingly influential, tools like XPrompt will be crucial for ensuring they are used responsibly and ethically.
Conclusion
XPrompt: Explaining Large Language Model's Generation via Joint Prompt Attribution introduces a novel method for attributing the generation of large language models (LLMs) to different components of the input prompt. By using a joint prompt attribution approach, XPrompt can provide valuable insights into how LLMs respond to prompts and which elements most influence their outputs.
The authors demonstrate the effectiveness of XPrompt on a range of language tasks, showing that it can surface important information about an LLM's reasoning and decision-making process. This type of interpretability is crucial as these powerful AI systems become more widely deployed and relied upon.
While XPrompt has some limitations, such as computational complexity and challenges with capturing nonlinearities, the paper represents an important step forward in the field of LLM transparency. As the use of large language models continues to grow, developing techniques like XPrompt will be essential for building trust, ensuring responsible use, and unlocking the full potential of these transformative AI technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
A Better LLM Evaluator for Text Generation: The Impact of Prompt Output Sequencing and Optimization
KuanChao Chu, Yi-Pei Chen, Hideki Nakayama
0
0
This research investigates prompt designs of evaluating generated texts using large language models (LLMs). While LLMs are increasingly used for scoring various inputs, creating effective prompts for open-ended text evaluation remains challenging due to model sensitivity and subjectivity in evaluation of text generation. Our study experimented with different prompt structures, altering the sequence of output instructions and including explanatory reasons. We found that the order of presenting reasons and scores significantly influences LLMs' scoring, with a different level of rule understanding in the prompt. An additional optimization may enhance scoring alignment if sufficient data is available. This insight is crucial for improving the accuracy and consistency of LLM-based evaluations.
6/17/2024

Prompt Exploration with Prompt Regression
Michael Feffer, Ronald Xu, Yuekai Sun, Mikhail Yurochkin
0
0
In the advent of democratized usage of large language models (LLMs), there is a growing desire to systematize LLM prompt creation and selection processes beyond iterative trial-and-error. Prior works majorly focus on searching the space of prompts without accounting for relations between prompt variations. Here we propose a framework, Prompt Exploration with Prompt Regression (PEPR), to predict the effect of prompt combinations given results for individual prompt elements as well as a simple method to select an effective prompt for a given use-case. We evaluate our approach with open-source LLMs of different sizes on several different tasks.
5/21/2024
👨🏫
Extracting Prompts by Inverting LLM Outputs
Collin Zhang, John X. Morris, Vitaly Shmatikov
0
0
We consider the problem of language model inversion: given outputs of a language model, we seek to extract the prompt that generated these outputs. We develop a new black-box method, output2prompt, that learns to extract prompts without access to the model's logits and without adversarial or jailbreaking queries. In contrast to previous work, output2prompt only needs outputs of normal user queries. To improve memory efficiency, output2prompt employs a new sparse encoding techique. We measure the efficacy of output2prompt on a variety of user and system prompts and demonstrate zero-shot transferability across different LLMs.
5/27/2024
Causal Prompting: Debiasing Large Language Model Prompting based on Front-Door Adjustment
Congzhi Zhang, Linhai Zhang, Jialong Wu, Deyu Zhou, Yulan He
0
0
Despite the notable advancements of existing prompting methods, such as In-Context Learning and Chain-of-Thought for Large Language Models (LLMs), they still face challenges related to various biases. Traditional debiasing methods primarily focus on the model training stage, including approaches based on data augmentation and reweighting, yet they struggle with the complex biases inherent in LLMs. To address such limitations, the causal relationship behind the prompting methods is uncovered using a structural causal model, and a novel causal prompting method based on front-door adjustment is proposed to effectively mitigate LLMs biases. In specific, causal intervention is achieved by designing the prompts without accessing the parameters and logits of LLMs. The chain-of-thought generated by LLM is employed as the mediator variable and the causal effect between input prompts and output answers is calculated through front-door adjustment to mitigate model biases. Moreover, to accurately represent the chain-of-thoughts and estimate the causal effects, contrastive learning is used to fine-tune the encoder of chain-of-thought by aligning its space with that of the LLM. Experimental results show that the proposed causal prompting approach achieves excellent performance across seven natural language processing datasets on both open-source and closed-source LLMs.
5/24/2024