Causal Prompting: Debiasing Large Language Model Prompting based on Front-Door Adjustment
2403.02738
0
0
Abstract
Despite the notable advancements of existing prompting methods, such as In-Context Learning and Chain-of-Thought for Large Language Models (LLMs), they still face challenges related to various biases. Traditional debiasing methods primarily focus on the model training stage, including approaches based on data augmentation and reweighting, yet they struggle with the complex biases inherent in LLMs. To address such limitations, the causal relationship behind the prompting methods is uncovered using a structural causal model, and a novel causal prompting method based on front-door adjustment is proposed to effectively mitigate LLMs biases. In specific, causal intervention is achieved by designing the prompts without accessing the parameters and logits of LLMs. The chain-of-thought generated by LLM is employed as the mediator variable and the causal effect between input prompts and output answers is calculated through front-door adjustment to mitigate model biases. Moreover, to accurately represent the chain-of-thoughts and estimate the causal effects, contrastive learning is used to fine-tune the encoder of chain-of-thought by aligning its space with that of the LLM. Experimental results show that the proposed causal prompting approach achieves excellent performance across seven natural language processing datasets on both open-source and closed-source LLMs.
Create account to get full access
Overview
• This paper introduces Causal Prompting, a new approach to debiasing large language model prompting based on the front-door adjustment technique from causal inference.
• The authors aim to reduce biases in language model outputs by explicitly modeling the causal relationships between the prompt, the language model's internal representations, and the final output.
• Key ideas include incorporating causal knowledge into prompting, using front-door adjustment to debias model outputs, and evaluating the method on language understanding and generation tasks.
Plain English Explanation
Causal Prompting is a new way to reduce biases in the outputs of large language models. Large language models, like GPT-3, can sometimes generate biased or unfair text because of the data they were trained on. The authors of this paper wanted to find a way to fix this problem.
They realized that the way the prompts (the text you give the model to start with) interact with the model's internal representations can lead to biased outputs. So they developed a method that explicitly models these causal relationships. By understanding how the prompt, the model's inner workings, and the final output are connected, they can adjust the prompts to reduce biases.
The key idea is to use a technique called front-door adjustment from causal inference. This allows them to "debias" the model's outputs by changing the prompts in a smart way. They tested this approach on language understanding and generation tasks, and found that it can effectively reduce biases while maintaining the model's overall performance.
The goal is to make large language models more fair and reliable, so they can be used safely and responsibly in real-world applications. This research is an important step towards developing more ethical and trustworthy AI systems.
Technical Explanation
The authors propose a new framework called Causal Prompting that leverages causal inference to debias large language model prompting. The key idea is to explicitly model the causal relationships between the prompt, the language model's internal representations, and the final output.
By using the front-door adjustment technique from causal inference, the authors can adjust the prompts to mitigate biases in the model's outputs. The front-door adjustment allows them to break the causal pathway between the prompt and the biased output, and instead route the information through a debiased set of intermediate representations.
The authors evaluate their Causal Prompting approach on a range of language understanding and generation tasks, including toxicity detection, sentiment analysis, and open-ended text generation. They show that Causal Prompting can effectively reduce biases in the model's outputs while maintaining overall performance.
This work builds on previous research on debiasing large language models, causal decision-making in language models, and evaluating the causal reasoning capabilities of language models. The authors also discuss connections to work on causal explainable guardrails for language models and exploring the capabilities of prompted language models.
Critical Analysis
The Causal Prompting approach presented in this paper is a promising step towards developing more ethical and reliable large language models. By explicitly modeling the causal relationships in the prompting process, the authors are able to effectively debias the model's outputs.
However, the authors note that their approach relies on the availability of causal knowledge about the prompting process, which may not always be easy to obtain. Additionally, the front-door adjustment technique used in Causal Prompting requires careful estimation of the relevant causal parameters, which could be challenging in practice.
Furthermore, while the authors demonstrate the effectiveness of Causal Prompting on a range of tasks, it would be valuable to see how the approach performs on a wider variety of applications and datasets, especially in real-world settings. The generalizability of the method could be an area for further investigation.
It's also important to consider potential limitations and unintended consequences of Causal Prompting. For example, the authors note that the method may not be able to completely eliminate all biases, and there could be tradeoffs between debiasing and other desirable model properties, such as performance or coherence.
Overall, the Causal Prompting framework represents an important step forward in the ongoing effort to develop more ethical and trustworthy large language models. The authors have made a valuable contribution to the field, and their work opens up new avenues for further research and development in this critical area.
Conclusion
The Causal Prompting approach introduced in this paper offers a novel way to debias the outputs of large language models by explicitly modeling the causal relationships in the prompting process. By using front-door adjustment, the authors are able to reduce biases in the model's outputs while maintaining overall performance.
This research is a significant contribution to the growing field of ethical AI, as it addresses a key challenge in the development of reliable and trustworthy language models. The Causal Prompting framework could have important implications for a wide range of real-world applications that rely on large language models, from content moderation to personal assistants.
While the method has some limitations and areas for further exploration, the authors have demonstrated the potential of causal reasoning to improve the fairness and robustness of these powerful AI systems. As the use of large language models continues to expand, approaches like Causal Prompting will be increasingly important for ensuring that these technologies are developed and deployed in a responsible and ethical manner.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Thinking Fair and Slow: On the Efficacy of Structured Prompts for Debiasing Language Models
Shaz Furniturewala, Surgan Jandial, Abhinav Java, Pragyan Banerjee, Simra Shahid, Sumit Bhatia, Kokil Jaidka
0
0
Existing debiasing techniques are typically training-based or require access to the model's internals and output distributions, so they are inaccessible to end-users looking to adapt LLM outputs for their particular needs. In this study, we examine whether structured prompting techniques can offer opportunities for fair text generation. We evaluate a comprehensive end-user-focused iterative framework of debiasing that applies System 2 thinking processes for prompts to induce logical, reflective, and critical text generation, with single, multi-step, instruction, and role-based variants. By systematically evaluating many LLMs across many datasets and different prompting strategies, we show that the more complex System 2-based Implicative Prompts significantly improve over other techniques demonstrating lower mean bias in the outputs with competitive performance on the downstream tasks. Our work offers research directions for the design and the potential of end-user-focused evaluative frameworks for LLM use.
5/20/2024

Out-Of-Context Prompting Boosts Fairness and Robustness in Large Language Model Predictions
Leonardo Cotta, Chris J. Maddison
0
0
Frontier Large Language Models (LLMs) are increasingly being deployed for high-stakes decision-making. On the other hand, these models are still consistently making predictions that contradict users' or society's expectations, e.g., hallucinating, or discriminating. Thus, it is important that we develop test-time strategies to improve their trustworthiness. Inspired by prior work, we leverage causality as a tool to formally encode two aspects of trustworthiness in LLMs: fairness and robustness. Under this perspective, existing test-time solutions explicitly instructing the model to be fair or robust implicitly depend on the LLM's causal reasoning capabilities. In this work, we explore the opposite approach. Instead of explicitly asking the LLM for trustworthiness, we design prompts to encode the underlying causal inference algorithm that will, by construction, result in more trustworthy predictions. Concretely, we propose out-of-context prompting as a test-time solution to encourage fairness and robustness in LLMs. Out-of-context prompting leverages the user's prior knowledge of the task's causal model to apply (random) counterfactual transformations and improve the model's trustworthiness. Empirically, we show that out-of-context prompting consistently improves the fairness and robustness of frontier LLMs across five different benchmark datasets without requiring additional data, finetuning or pre-training.
6/13/2024
Large Language Model for Causal Decision Making
Haitao Jiang, Lin Ge, Yuhe Gao, Jianian Wang, Rui Song
0
0
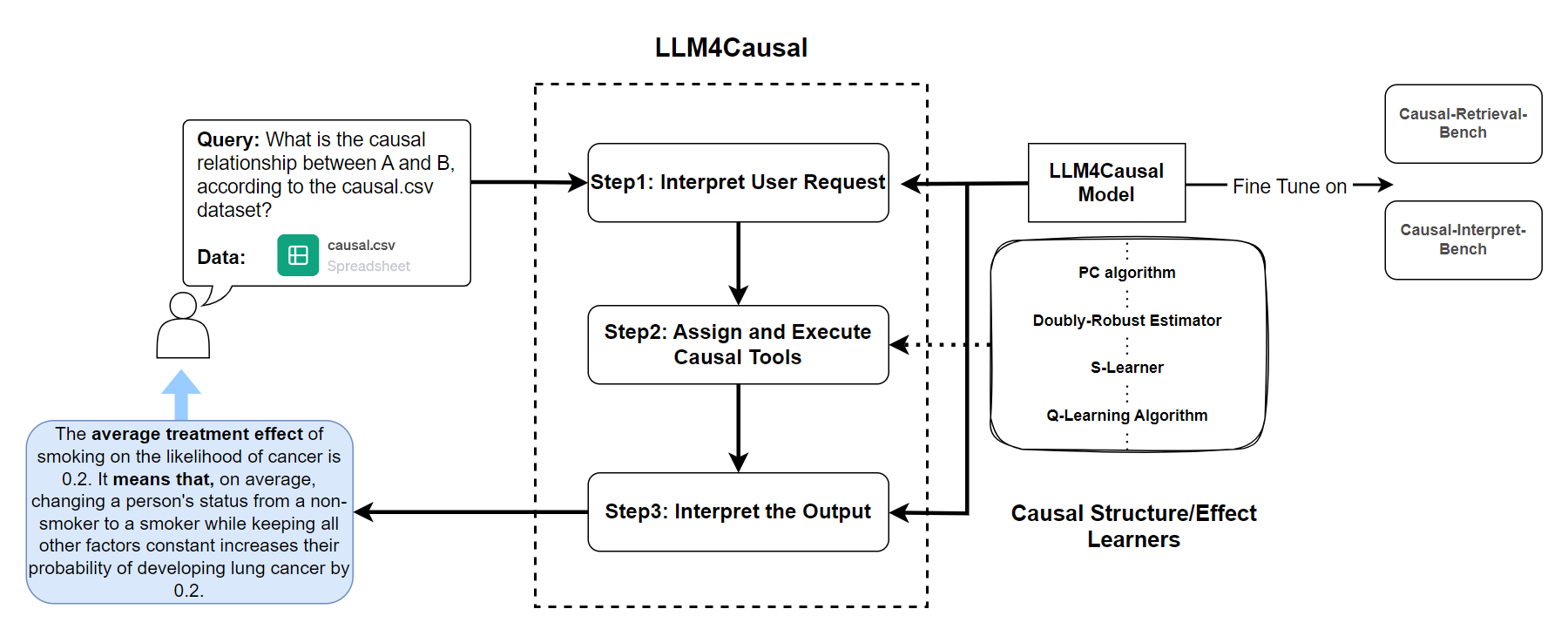
Large Language Models (LLMs) have shown their success in language understanding and reasoning on general topics. However, their capability to perform inference based on user-specified structured data and knowledge in corpus-rare concepts, such as causal decision-making is still limited. In this work, we explore the possibility of fine-tuning an open-sourced LLM into LLM4Causal, which can identify the causal task, execute a corresponding function, and interpret its numerical results based on users' queries and the provided dataset. Meanwhile, we propose a data generation process for more controllable GPT prompting and present two instruction-tuning datasets: (1) Causal-Retrieval-Bench for causal problem identification and input parameter extraction for causal function calling and (2) Causal-Interpret-Bench for in-context causal interpretation. By conducting end-to-end evaluations and two ablation studies, we showed that LLM4Causal can deliver end-to-end solutions for causal problems and provide easy-to-understand answers, which significantly outperforms the baselines.
4/15/2024
XPrompt:Explaining Large Language Model's Generation via Joint Prompt Attribution
Yurui Chang, Bochuan Cao, Yujia Wang, Jinghui Chen, Lu Lin
0
0
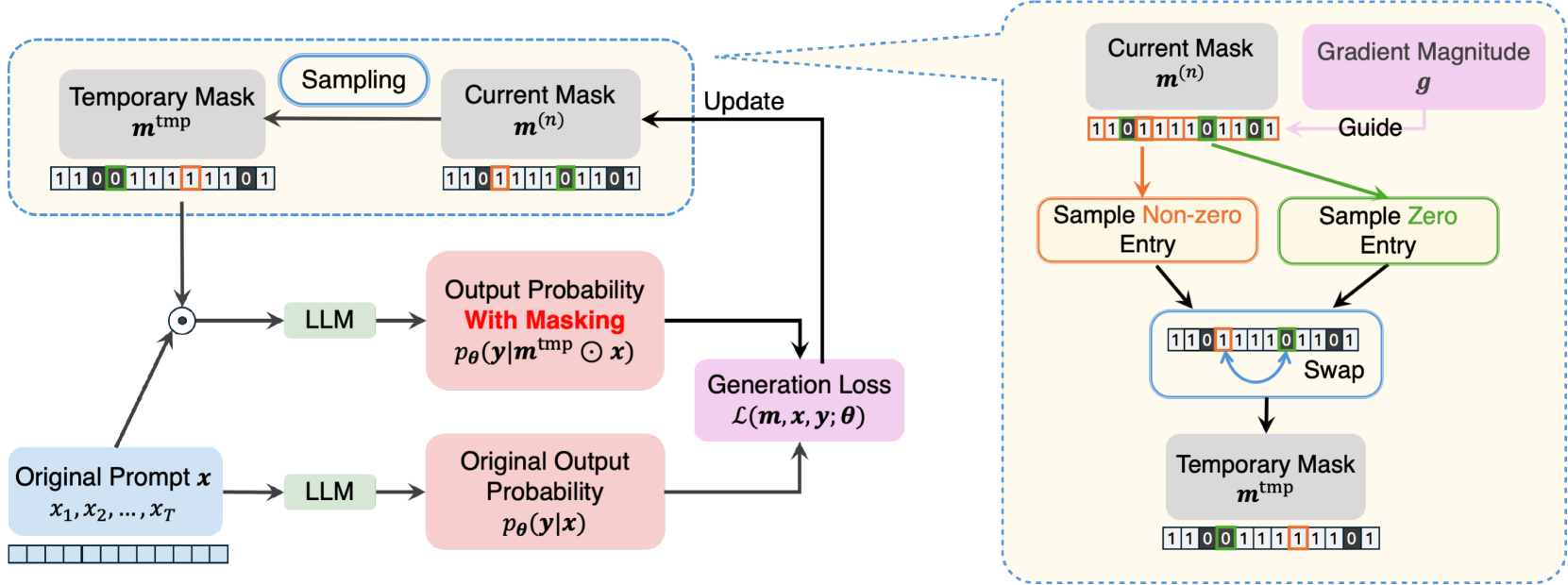
Large Language Models (LLMs) have demonstrated impressive performances in complex text generation tasks. However, the contribution of the input prompt to the generated content still remains obscure to humans, underscoring the necessity of elucidating and explaining the causality between input and output pairs. Existing works for providing prompt-specific explanation often confine model output to be classification or next-word prediction. Few initial attempts aiming to explain the entire language generation often treat input prompt texts independently, ignoring their combinatorial effects on the follow-up generation. In this study, we introduce a counterfactual explanation framework based on joint prompt attribution, XPrompt, which aims to explain how a few prompt texts collaboratively influences the LLM's complete generation. Particularly, we formulate the task of prompt attribution for generation interpretation as a combinatorial optimization problem, and introduce a probabilistic algorithm to search for the casual input combination in the discrete space. We define and utilize multiple metrics to evaluate the produced explanations, demonstrating both faithfulness and efficiency of our framework.
6/3/2024