A Better LLM Evaluator for Text Generation: The Impact of Prompt Output Sequencing and Optimization
2406.09972
0
0
Abstract
This research investigates prompt designs of evaluating generated texts using large language models (LLMs). While LLMs are increasingly used for scoring various inputs, creating effective prompts for open-ended text evaluation remains challenging due to model sensitivity and subjectivity in evaluation of text generation. Our study experimented with different prompt structures, altering the sequence of output instructions and including explanatory reasons. We found that the order of presenting reasons and scores significantly influences LLMs' scoring, with a different level of rule understanding in the prompt. An additional optimization may enhance scoring alignment if sufficient data is available. This insight is crucial for improving the accuracy and consistency of LLM-based evaluations.
Create account to get full access
Overview
- This paper explores the impact of prompt output sequencing and optimization on evaluating large language models (LLMs) for text generation tasks.
- The researchers propose a new evaluation framework that considers the order and optimization of prompts, arguing that this can provide a more accurate assessment of LLM performance.
- The paper examines the effects of prompt output sequencing and optimization on dialogue evaluation, a common application of LLMs.
Plain English Explanation
When evaluating how well large language models (LLMs) can generate text, the order and optimization of the prompts used in the evaluation process can have a significant impact on the results. This paper explores a new evaluation framework that takes these factors into account, with the goal of providing a more accurate assessment of LLM performance, particularly in the context of dialogue generation.
The researchers argue that the traditional approach to evaluating LLMs for text generation tasks, which often involves a single prompt, may not capture the full complexity of how these models perform. By considering the sequence of prompts and optimizing the prompt selection, the new evaluation framework can provide deeper insights into an LLM's capabilities and limitations.
Technical Explanation
The paper presents a novel evaluation framework that considers the impact of prompt output sequencing and optimization on assessing the performance of large language models (LLMs) for text generation tasks. The researchers argue that the order and selection of prompts can significantly affect the evaluation results, and that traditional single-prompt evaluations may not provide a comprehensive assessment of an LLM's capabilities.
The proposed framework involves generating a sequence of prompts and evaluating the LLM's responses, rather than relying on a single prompt. The researchers also explore techniques for optimizing the prompt selection, such as using a set of diverse prompts or leveraging prompts that target specific capabilities.
The paper examines the impact of this approach on dialogue evaluation, a common application of LLMs. The results suggest that the proposed framework can provide a more nuanced and accurate assessment of an LLM's performance in generating coherent and relevant dialogue responses, compared to traditional single-prompt evaluations.
Critical Analysis
The paper presents a compelling case for the need to consider prompt output sequencing and optimization when evaluating the performance of large language models (LLMs) for text generation tasks. The researchers' argument that traditional single-prompt evaluations may not capture the full complexity of LLM capabilities is well-supported by the experimental results.
However, the paper does not address several potential limitations and areas for further research. For example, the proposed framework may be computationally intensive and time-consuming, especially when evaluating LLMs with large model sizes or when considering a large number of prompts. Exploring more efficient multi-prompt evaluation strategies could help address this issue.
Additionally, the paper does not discuss the generalization of the proposed framework to other text generation tasks beyond dialogue evaluation. It would be interesting to see if the insights and findings from this research can be applied to a broader range of applications, such as generating introductory computer science explanations or explaining the reasoning behind LLM outputs.
Overall, the paper makes a valuable contribution to the field of LLM evaluation, but further research is needed to address the potential limitations and explore the broader applicability of the proposed framework.
Conclusion
This paper presents a new evaluation framework for large language models (LLMs) that considers the impact of prompt output sequencing and optimization on text generation performance, particularly in the context of dialogue evaluation. The researchers argue that traditional single-prompt evaluations may not provide a comprehensive assessment of LLM capabilities, and that the proposed framework can offer deeper insights into an LLM's strengths and weaknesses.
The findings have important implications for the development and deployment of LLMs in real-world applications, as they suggest that a more nuanced and targeted evaluation approach may be necessary to accurately measure and improve the performance of these powerful language models. Going forward, the principles and techniques introduced in this paper could be applied to a wider range of LLM applications and evaluation scenarios, further advancing the state of the art in language model assessment and optimization.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
LLM as a Scorer: The Impact of Output Order on Dialogue Evaluation
Yi-Pei Chen, KuanChao Chu, Hideki Nakayama
0
0
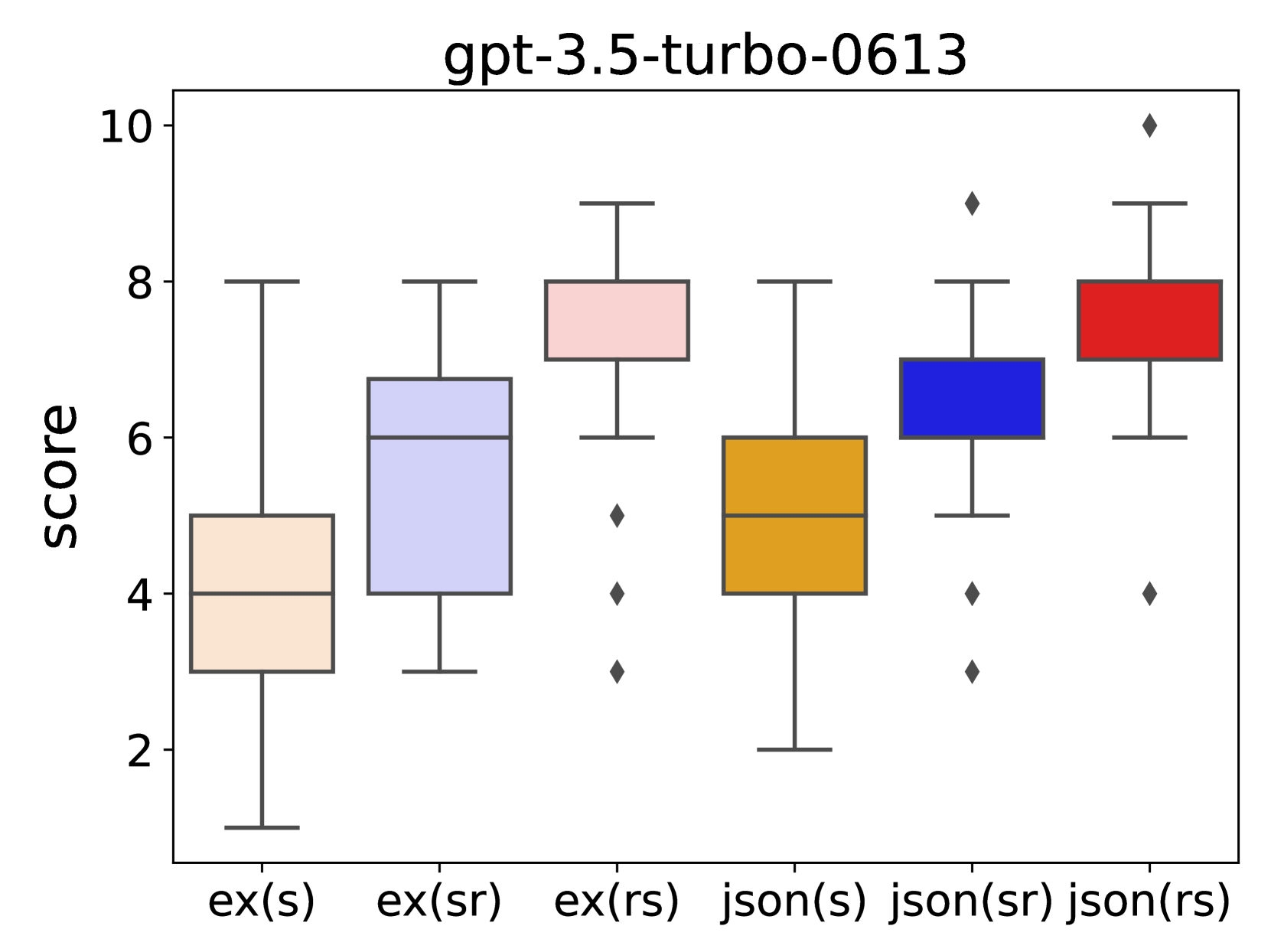
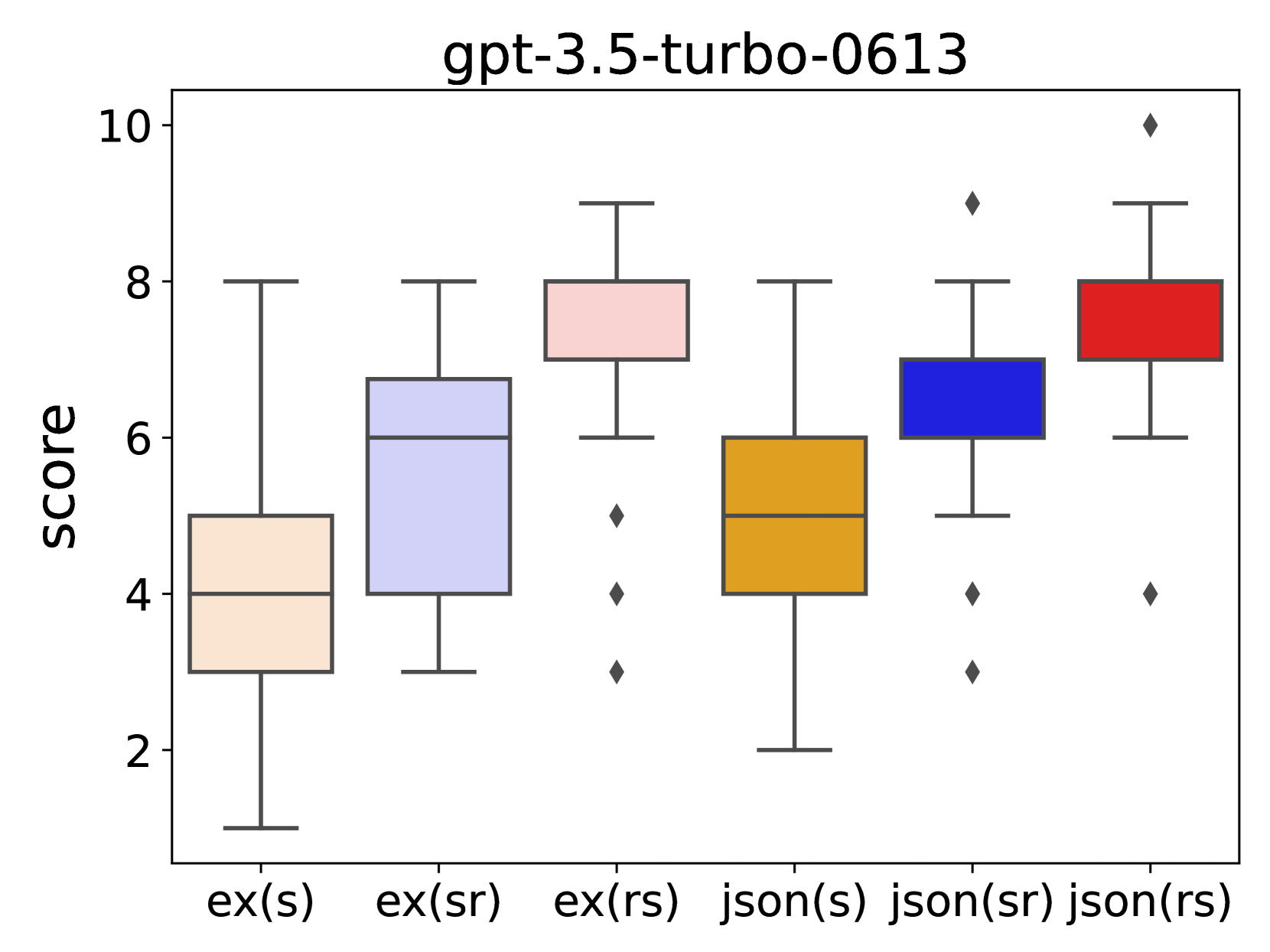
This research investigates the effect of prompt design on dialogue evaluation using large language models (LLMs). While LLMs are increasingly used for scoring various inputs, creating effective prompts for dialogue evaluation remains challenging due to model sensitivity and subjectivity in dialogue assessments. Our study experimented with different prompt structures, altering the sequence of output instructions and including explanatory reasons. We found that the order of presenting reasons and scores significantly influences LLMs' scoring, with a reason-first approach yielding more comprehensive evaluations. This insight is crucial for enhancing the accuracy and consistency of LLM-based evaluations.
6/6/2024
Prompt Design Matters for Computational Social Science Tasks but in Unpredictable Ways
Shubham Atreja, Joshua Ashkinaze, Lingyao Li, Julia Mendelsohn, Libby Hemphill
0
0
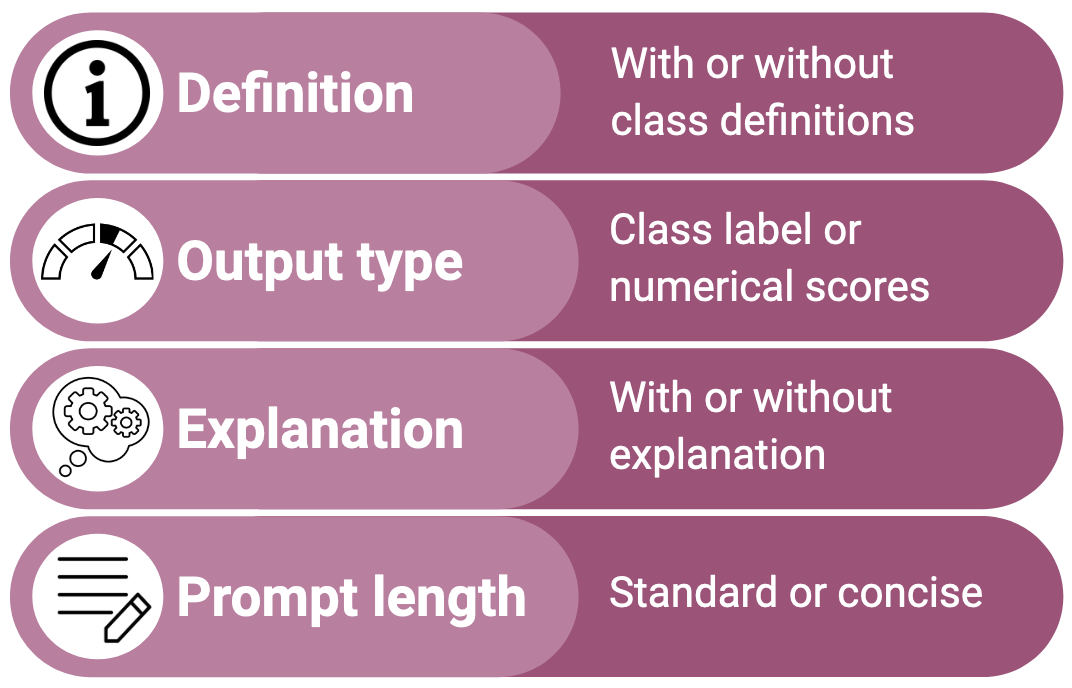
Manually annotating data for computational social science tasks can be costly, time-consuming, and emotionally draining. While recent work suggests that LLMs can perform such annotation tasks in zero-shot settings, little is known about how prompt design impacts LLMs' compliance and accuracy. We conduct a large-scale multi-prompt experiment to test how model selection (ChatGPT, PaLM2, and Falcon7b) and prompt design features (definition inclusion, output type, explanation, and prompt length) impact the compliance and accuracy of LLM-generated annotations on four CSS tasks (toxicity, sentiment, rumor stance, and news frames). Our results show that LLM compliance and accuracy are highly prompt-dependent. For instance, prompting for numerical scores instead of labels reduces all LLMs' compliance and accuracy. The overall best prompting setup is task-dependent, and minor prompt changes can cause large changes in the distribution of generated labels. By showing that prompt design significantly impacts the quality and distribution of LLM-generated annotations, this work serves as both a warning and practical guide for researchers and practitioners.
6/19/2024

Efficient multi-prompt evaluation of LLMs
Felipe Maia Polo, Ronald Xu, Lucas Weber, M'irian Silva, Onkar Bhardwaj, Leshem Choshen, Allysson Flavio Melo de Oliveira, Yuekai Sun, Mikhail Yurochkin
0
0
Most popular benchmarks for comparing LLMs rely on a limited set of prompt templates, which may not fully capture the LLMs' abilities and can affect the reproducibility of results on leaderboards. Many recent works empirically verify prompt sensitivity and advocate for changes in LLM evaluation. In this paper, we consider the problem of estimating the performance distribution across many prompt variants instead of finding a single prompt to evaluate with. We introduce PromptEval, a method for estimating performance across a large set of prompts borrowing strength across prompts and examples to produce accurate estimates under practical evaluation budgets. The resulting distribution can be used to obtain performance quantiles to construct various robust performance metrics (e.g., top 95% quantile or median). We prove that PromptEval consistently estimates the performance distribution and demonstrate its efficacy empirically on three prominent LLM benchmarks: MMLU, BIG-bench Hard, and LMentry. For example, PromptEval can accurately estimate performance quantiles across 100 prompt templates on MMLU with a budget equivalent to two single-prompt evaluations. Our code and data can be found at https://github.com/felipemaiapolo/prompt-eval.
6/11/2024
📉
CSEPrompts: A Benchmark of Introductory Computer Science Prompts
Nishat Raihan, Dhiman Goswami, Sadiya Sayara Chowdhury Puspo, Christian Newman, Tharindu Ranasinghe, Marcos Zampieri
0
0
Recent advances in AI, machine learning, and NLP have led to the development of a new generation of Large Language Models (LLMs) that are trained on massive amounts of data and often have trillions of parameters. Commercial applications (e.g., ChatGPT) have made this technology available to the general public, thus making it possible to use LLMs to produce high-quality texts for academic and professional purposes. Schools and universities are aware of the increasing use of AI-generated content by students and they have been researching the impact of this new technology and its potential misuse. Educational programs in Computer Science (CS) and related fields are particularly affected because LLMs are also capable of generating programming code in various programming languages. To help understand the potential impact of publicly available LLMs in CS education, we introduce CSEPrompts, a framework with hundreds of programming exercise prompts and multiple-choice questions retrieved from introductory CS and programming courses. We also provide experimental results on CSEPrompts to evaluate the performance of several LLMs with respect to generating Python code and answering basic computer science and programming questions.
4/5/2024