Extracting Prompts by Inverting LLM Outputs
2405.15012
2
0
👨🏫
Abstract
We consider the problem of language model inversion: given outputs of a language model, we seek to extract the prompt that generated these outputs. We develop a new black-box method, output2prompt, that learns to extract prompts without access to the model's logits and without adversarial or jailbreaking queries. In contrast to previous work, output2prompt only needs outputs of normal user queries. To improve memory efficiency, output2prompt employs a new sparse encoding techique. We measure the efficacy of output2prompt on a variety of user and system prompts and demonstrate zero-shot transferability across different LLMs.
Create account to get full access
Overview
- The research paper explores the problem of "language model inversion" - extracting the original prompt that generated the output of a language model.
- The authors develop a new method called "output2prompt" that can recover prompts from language model outputs, without access to the model's internal workings.
- This method only requires the language model's outputs, and not the logits or adversarial/jailbreaking queries used in previous work.
- To improve memory efficiency, output2prompt uses a new sparse encoding technique.
- The authors test output2prompt on a variety of user and system prompts, and demonstrate its ability to transfer across different large language models.
Plain English Explanation
The paper addresses the challenge of "language model inversion" - the task of figuring out the original prompt or input that a language model, like GPT-3, used to generate a given output. This is a bit like trying to reverse-engineer a recipe from tasting the final dish.
The researchers developed a new method called "output2prompt" that can recover the original prompts without needing access to the model's internal workings. Previous approaches, like AdvPromter and Prompt Exploration, required special queries or access to the model's internal "logits". In contrast, output2prompt only needs the normal outputs the language model produces.
To make this process more efficient, the researchers used a new technique to "encode" the prompts in a sparse, compressed way. This helps output2prompt run faster and use less memory.
The team tested output2prompt on a variety of different prompts, from user-generated to system-generated, and found that it could successfully recover the original prompts. Importantly, they also showed that output2prompt can "transfer" - it works well across different large language models, not just the one it was trained on.
Technical Explanation
The core idea behind the "output2prompt" method is to learn a mapping from the language model's outputs back to the original prompts, without needing access to the model's internal "logits" or scores.
To do this, the authors train a neural network model that takes in the language model's outputs and learns to generate the corresponding prompts. This is done using a dataset of prompt-output pairs, where the prompts are known.
A key innovation is the use of a "sparse encoding" technique to represent the prompts. This allows the model to learn a compact, efficient representation of the prompts, reducing the memory and compute required.
The authors evaluate output2prompt on a range of different prompts, from user-generated text to system-generated prompts used in tasks like summarization and translation. They find that output2prompt can successfully recover the original prompts in these diverse settings.
Importantly, the authors also demonstrate "zero-shot transferability" - output2prompt can be applied to language models it wasn't trained on, like GPT-3, and still recover the prompts accurately. This suggests the method has broad applicability beyond a single model.
Critical Analysis
The output2prompt method represents an interesting and useful advance in the field of language model inversion. By avoiding the need for access to model internals or adversarial queries, it makes the prompt recovery process more accessible and practical.
However, the paper does not address some potential limitations and areas for further research. For example, the method may struggle with longer or more complex prompts, where the mapping from output to prompt becomes more ambiguous. There are also open questions around the generalization of output2prompt to other types of language models beyond the ones tested.
Additionally, while the sparse encoding technique improves efficiency, there may still be concerns around the computational overhead and scalability of the approach, especially for deployment at scale.
It would be valuable for future work to further explore the robustness and limitations of output2prompt, as well as investigate potential applications beyond just prompt recovery, such as prompt tuning or private inference.
Conclusion
The output2prompt method developed in this paper represents a significant advancement in the field of language model inversion. By enabling prompt recovery without access to model internals, it opens up new possibilities for understanding, interpreting, and interacting with large language models.
While the method has some limitations and areas for further research, the core idea and the demonstrated zero-shot transferability are highly promising. As language models become more powerful and ubiquitous, tools like output2prompt will be increasingly important for transparency, interpretability, and responsible development of these technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Language Models as Black-Box Optimizers for Vision-Language Models
Shihong Liu, Zhiqiu Lin, Samuel Yu, Ryan Lee, Tiffany Ling, Deepak Pathak, Deva Ramanan
0
0
Vision-language models (VLMs) pre-trained on web-scale datasets have demonstrated remarkable capabilities on downstream tasks when fine-tuned with minimal data. However, many VLMs rely on proprietary data and are not open-source, which restricts the use of white-box approaches for fine-tuning. As such, we aim to develop a black-box approach to optimize VLMs through natural language prompts, thereby avoiding the need to access model parameters, feature embeddings, or even output logits. We propose employing chat-based LLMs to search for the best text prompt for VLMs. Specifically, we adopt an automatic hill-climbing procedure that converges to an effective prompt by evaluating the performance of current prompts and asking LLMs to refine them based on textual feedback, all within a conversational process without human-in-the-loop. In a challenging 1-shot image classification setup, our simple approach surpasses the white-box continuous prompting method (CoOp) by an average of 1.5% across 11 datasets including ImageNet. Our approach also outperforms both human-engineered and LLM-generated prompts. We highlight the advantage of conversational feedback that incorporates both positive and negative prompts, suggesting that LLMs can utilize the implicit gradient direction in textual feedback for a more efficient search. In addition, we find that the text prompts generated through our strategy are not only more interpretable but also transfer well across different VLM architectures in a black-box manner. Lastly, we apply our framework to optimize the state-of-the-art black-box VLM (DALL-E 3) for text-to-image generation, prompt inversion, and personalization.
5/15/2024
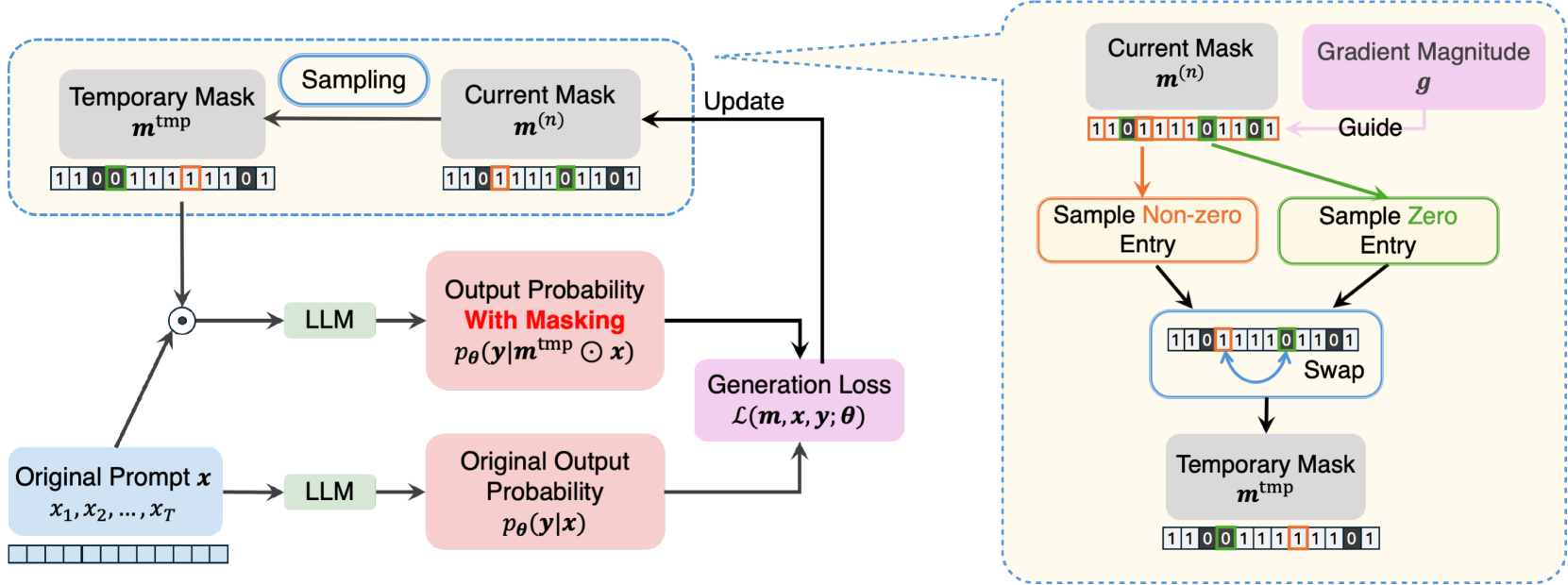
XPrompt:Explaining Large Language Model's Generation via Joint Prompt Attribution
Yurui Chang, Bochuan Cao, Yujia Wang, Jinghui Chen, Lu Lin
0
0
Large Language Models (LLMs) have demonstrated impressive performances in complex text generation tasks. However, the contribution of the input prompt to the generated content still remains obscure to humans, underscoring the necessity of elucidating and explaining the causality between input and output pairs. Existing works for providing prompt-specific explanation often confine model output to be classification or next-word prediction. Few initial attempts aiming to explain the entire language generation often treat input prompt texts independently, ignoring their combinatorial effects on the follow-up generation. In this study, we introduce a counterfactual explanation framework based on joint prompt attribution, XPrompt, which aims to explain how a few prompt texts collaboratively influences the LLM's complete generation. Particularly, we formulate the task of prompt attribution for generation interpretation as a combinatorial optimization problem, and introduce a probabilistic algorithm to search for the casual input combination in the discrete space. We define and utilize multiple metrics to evaluate the produced explanations, demonstrating both faithfulness and efficiency of our framework.
6/3/2024
A Better LLM Evaluator for Text Generation: The Impact of Prompt Output Sequencing and Optimization
KuanChao Chu, Yi-Pei Chen, Hideki Nakayama
0
0
This research investigates prompt designs of evaluating generated texts using large language models (LLMs). While LLMs are increasingly used for scoring various inputs, creating effective prompts for open-ended text evaluation remains challenging due to model sensitivity and subjectivity in evaluation of text generation. Our study experimented with different prompt structures, altering the sequence of output instructions and including explanatory reasons. We found that the order of presenting reasons and scores significantly influences LLMs' scoring, with a different level of rule understanding in the prompt. An additional optimization may enhance scoring alignment if sufficient data is available. This insight is crucial for improving the accuracy and consistency of LLM-based evaluations.
6/17/2024
🤔
AdvPrompter: Fast Adaptive Adversarial Prompting for LLMs
Anselm Paulus, Arman Zharmagambetov, Chuan Guo, Brandon Amos, Yuandong Tian
0
0
While recently Large Language Models (LLMs) have achieved remarkable successes, they are vulnerable to certain jailbreaking attacks that lead to generation of inappropriate or harmful content. Manual red-teaming requires finding adversarial prompts that cause such jailbreaking, e.g. by appending a suffix to a given instruction, which is inefficient and time-consuming. On the other hand, automatic adversarial prompt generation often leads to semantically meaningless attacks that can easily be detected by perplexity-based filters, may require gradient information from the TargetLLM, or do not scale well due to time-consuming discrete optimization processes over the token space. In this paper, we present a novel method that uses another LLM, called the AdvPrompter, to generate human-readable adversarial prompts in seconds, $sim800times$ faster than existing optimization-based approaches. We train the AdvPrompter using a novel algorithm that does not require access to the gradients of the TargetLLM. This process alternates between two steps: (1) generating high-quality target adversarial suffixes by optimizing the AdvPrompter predictions, and (2) low-rank fine-tuning of the AdvPrompter with the generated adversarial suffixes. The trained AdvPrompter generates suffixes that veil the input instruction without changing its meaning, such that the TargetLLM is lured to give a harmful response. Experimental results on popular open source TargetLLMs show state-of-the-art results on the AdvBench dataset, that also transfer to closed-source black-box LLM APIs. Further, we demonstrate that by fine-tuning on a synthetic dataset generated by AdvPrompter, LLMs can be made more robust against jailbreaking attacks while maintaining performance, i.e. high MMLU scores.
4/29/2024