XSub: Explanation-Driven Adversarial Attack against Blackbox Classifiers via Feature Substitution

0
Sign in to get full access
Overview
- The paper proposes a new explanation-driven adversarial attack, called XSub, against blackbox classifiers.
- XSub leverages feature substitution to generate adversarial examples that fool the target model while providing a plausible explanation for the model's prediction.
- The approach is designed to be effective against blackbox models, which are common in real-world AI applications but are vulnerable to adversarial attacks.
Plain English Explanation
In the world of artificial intelligence (AI), there are various types of machine learning models, some of which are like black boxes - you can't easily see how they make their decisions. These black-box models are widely used in many real-world applications, but they can be vulnerable to adversarial attacks.
The researchers in this paper have developed a new type of adversarial attack called XSub that can fool these black-box models. The key idea behind XSub is to use "feature substitution" - substituting certain features in the input data with similar-looking ones. This allows XSub to generate adversarial examples that can trick the model, while also providing a plausible explanation for why the model made that prediction.
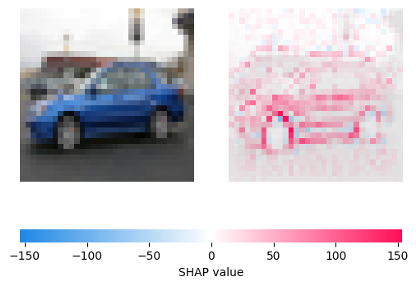
For example, imagine a model that's classifying images of dogs and cats. XSub might take an image of a cat and subtly change some of the features, like the texture of the fur, to make the model think it's a dog. But it would also provide an explanation, like "this looks like a dog because of the fur texture." This makes the attack more convincing and harder to detect.
The researchers tested XSub on several different black-box models and found that it was effective at fooling them, while also providing explanations that seemed reasonable. This is an important advance, as it shows how even advanced AI systems can be vulnerable to these kinds of attacks, and highlights the need for better defenses and more transparent, explainable AI systems.
Technical Explanation
The paper introduces a new explanation-driven adversarial attack called XSub that targets blackbox classifiers. The key idea behind XSub is to leverage feature substitution to generate adversarial examples that can fool the target model while also providing a plausible explanation for the model's prediction.
The XSub attack consists of two main steps:
-
Feature Substitution: XSub identifies a set of features in the input data that are important for the model's prediction, and then substitutes those features with similar-looking ones. This is done in a way that preserves the overall appearance of the input while subtly changing the features that the model relies on.
-
Explanation Generation: XSub generates an explanation for the model's prediction on the adversarial example. This explanation is designed to be plausible and consistent with the substituted features, making the attack more convincing.
The researchers evaluated XSub on several blackbox models, including image classifiers and text classifiers. They found that XSub was able to generate adversarial examples that successfully fooled the target models, while also providing explanations that seemed reasonable to human observers.
Importantly, the researchers also discussed the potential privacy implications of their approach, as the generated explanations could reveal sensitive information about the input data. They noted that further research is needed to address these concerns and ensure the responsible development of XAI-based attack detection systems.
Critical Analysis
The XSub attack proposed in this paper is a novel and interesting approach to generating adversarial examples against blackbox classifiers. By incorporating an explanation-driven component, the attack can be more convincing and harder to detect than traditional adversarial attacks.
However, the researchers acknowledge several limitations and areas for further research:
-
Privacy Concerns: As mentioned, the generated explanations could reveal sensitive information about the input data, raising privacy concerns. More work is needed to address this issue.
-
Transferability: The researchers note that the explanations generated by XSub may not transfer well to different models or domains. Improving the transferability of the attack would be an important next step.
-
Robustness: While XSub was effective against the tested blackbox models, it's unclear how robust the attack would be to more advanced defenses or changes in the target model's architecture.
-
Ethical Considerations: The development of effective adversarial attacks, even for research purposes, raises ethical concerns about the potential misuse of such techniques. The researchers should continue to carefully consider the societal implications of their work.
Overall, the XSub attack represents an interesting contribution to the field of adversarial machine learning. While the approach has promising capabilities, further research is needed to address the limitations and ensure the responsible development of such techniques.
Conclusion
The XSub attack proposed in this paper demonstrates a novel way to generate adversarial examples against blackbox classifiers. By leveraging feature substitution and explanation generation, XSub can fool target models while providing plausible justifications for the model's predictions.
This work highlights the continued vulnerability of blackbox AI systems to adversarial attacks, and the importance of developing more transparent and explainable AI systems that are more robust to such attacks. While the XSub approach has some limitations, it represents an important step forward in understanding the security challenges faced by modern AI applications.
As the field of explainable AI continues to evolve, it will be crucial to consider the potential misuse of such techniques and work towards developing AI systems that are both powerful and secure.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!XSub: Explanation-Driven Adversarial Attack against Blackbox Classifiers via Feature Substitution
Kiana Vu, Phung Lai, Truc Nguyen
Despite its significant benefits in enhancing the transparency and trustworthiness of artificial intelligence (AI) systems, explainable AI (XAI) has yet to reach its full potential in real-world applications. One key challenge is that XAI can unintentionally provide adversaries with insights into black-box models, inevitably increasing their vulnerability to various attacks. In this paper, we develop a novel explanation-driven adversarial attack against black-box classifiers based on feature substitution, called XSub. The key idea of XSub is to strategically replace important features (identified via XAI) in the original sample with corresponding important features from a golden sample of a different label, thereby increasing the likelihood of the model misclassifying the perturbed sample. The degree of feature substitution is adjustable, allowing us to control how much of the original samples information is replaced. This flexibility effectively balances a trade-off between the attacks effectiveness and its stealthiness. XSub is also highly cost-effective in that the number of required queries to the prediction model and the explanation model in conducting the attack is in O(1). In addition, XSub can be easily extended to launch backdoor attacks in case the attacker has access to the models training data. Our evaluation demonstrates that XSub is not only effective and stealthy but also cost-effective, enabling its application across a wide range of AI models.
Read more9/16/2024
0
XAI-Based Detection of Adversarial Attacks on Deepfake Detectors
Ben Pinhasov, Raz Lapid, Rony Ohayon, Moshe Sipper, Yehudit Aperstein
We introduce a novel methodology for identifying adversarial attacks on deepfake detectors using eXplainable Artificial Intelligence (XAI). In an era characterized by digital advancement, deepfakes have emerged as a potent tool, creating a demand for efficient detection systems. However, these systems are frequently targeted by adversarial attacks that inhibit their performance. We address this gap, developing a defensible deepfake detector by leveraging the power of XAI. The proposed methodology uses XAI to generate interpretability maps for a given method, providing explicit visualizations of decision-making factors within the AI models. We subsequently employ a pretrained feature extractor that processes both the input image and its corresponding XAI image. The feature embeddings extracted from this process are then used for training a simple yet effective classifier. Our approach contributes not only to the detection of deepfakes but also enhances the understanding of possible adversarial attacks, pinpointing potential vulnerabilities. Furthermore, this approach does not change the performance of the deepfake detector. The paper demonstrates promising results suggesting a potential pathway for future deepfake detection mechanisms. We believe this study will serve as a valuable contribution to the community, sparking much-needed discourse on safeguarding deepfake detectors.
Read more8/20/2024
🗣️
0
Causality-Aware Local Interpretable Model-Agnostic Explanations
Martina Cinquini, Riccardo Guidotti
A main drawback of eXplainable Artificial Intelligence (XAI) approaches is the feature independence assumption, hindering the study of potential variable dependencies. This leads to approximating black box behaviors by analyzing the effects on randomly generated feature values that may rarely occur in the original samples. This paper addresses this issue by integrating causal knowledge in an XAI method to enhance transparency and enable users to assess the quality of the generated explanations. Specifically, we propose a novel extension to a widely used local and model-agnostic explainer, which encodes explicit causal relationships within the data surrounding the instance being explained. Extensive experiments show that our approach overcomes the original method in terms of faithfully replicating the black-box model's mechanism and the consistency and reliability of the generated explanations.
Read more4/16/2024
0
Privacy Implications of Explainable AI in Data-Driven Systems
Fatima Ezzeddine
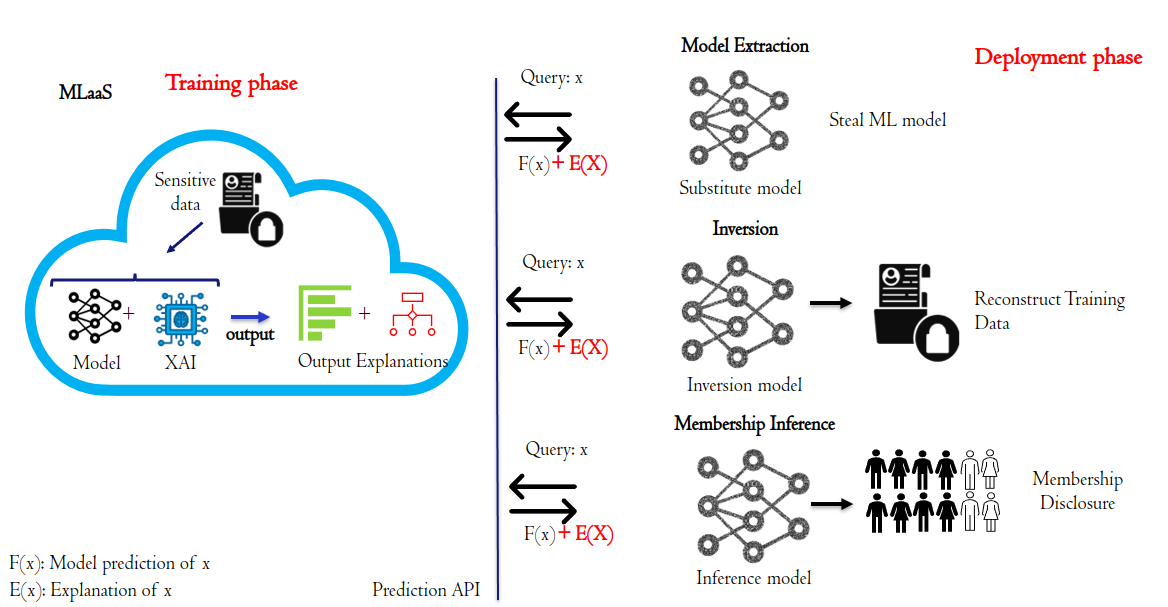
Machine learning (ML) models, demonstrably powerful, suffer from a lack of interpretability. The absence of transparency, often referred to as the black box nature of ML models, undermines trust and urges the need for efforts to enhance their explainability. Explainable AI (XAI) techniques address this challenge by providing frameworks and methods to explain the internal decision-making processes of these complex models. Techniques like Counterfactual Explanations (CF) and Feature Importance play a crucial role in achieving this goal. Furthermore, high-quality and diverse data remains the foundational element for robust and trustworthy ML applications. In many applications, the data used to train ML and XAI explainers contain sensitive information. In this context, numerous privacy-preserving techniques can be employed to safeguard sensitive information in the data, such as differential privacy. Subsequently, a conflict between XAI and privacy solutions emerges due to their opposing goals. Since XAI techniques provide reasoning for the model behavior, they reveal information relative to ML models, such as their decision boundaries, the values of features, or the gradients of deep learning models when explanations are exposed to a third entity. Attackers can initiate privacy breaching attacks using these explanations, to perform model extraction, inference, and membership attacks. This dilemma underscores the challenge of finding the right equilibrium between understanding ML decision-making and safeguarding privacy.
Read more6/26/2024