You Only Cache Once: Decoder-Decoder Architectures for Language Models
Overview
- This paper introduces a new language model architecture called "You Only Cache Once" (YOCO), which aims to improve the efficiency and performance of language models by using a decoder-only architecture.
- The key idea behind YOCO is to cache the output of the encoder and reuse it during decoding, rather than recomputing the encoder outputs for each target token.
- This approach is designed to reduce the computational cost and memory footprint of language models, making them more efficient and scalable.
Decoder-decoder architecture reduces cache memory and prefilling time.
1/3
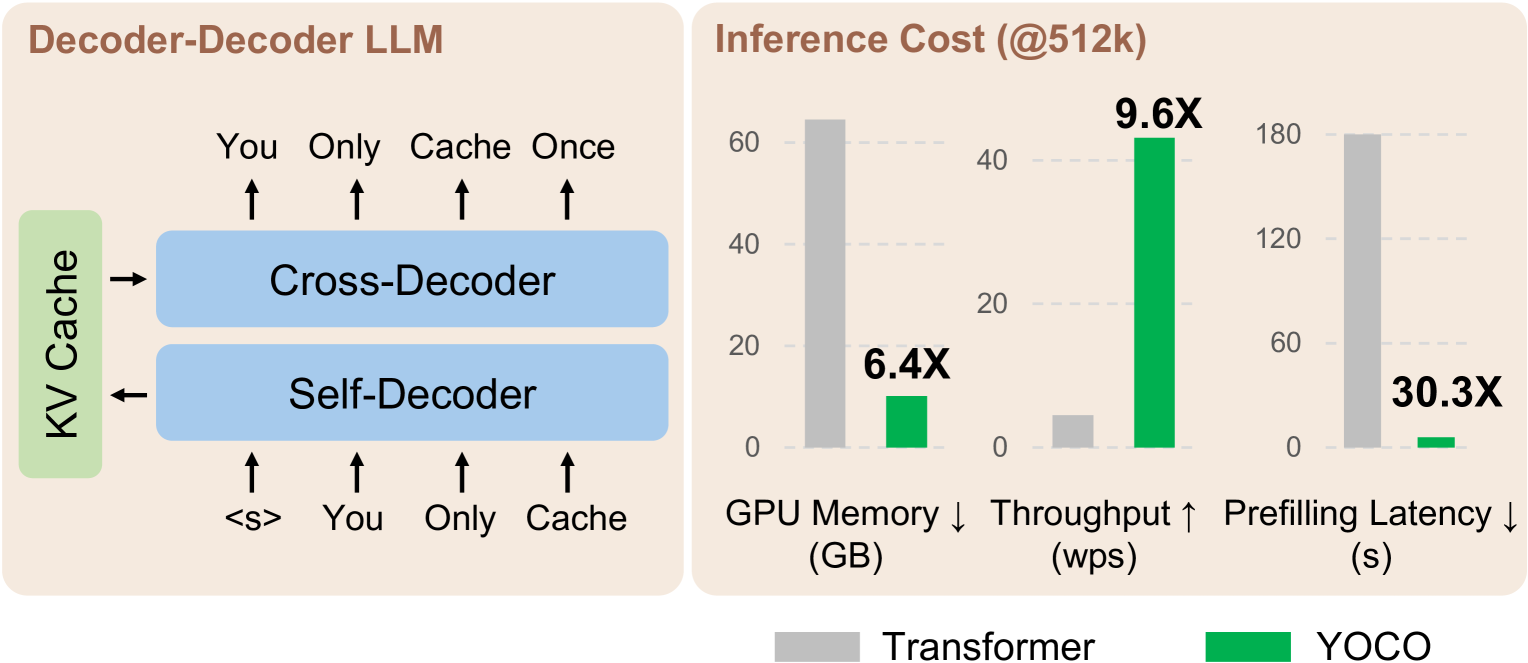
Original caption: Figure 1: We propose a decoder-decoder architecture, YOCO, for large language model, which only caches key/value once. YOCO markedly reduces the KV cache memory and the prefilling time, while being scalable in terms of training tokens, model size, and context length. The inference cost is reported to be 512K as the context length, and Figures 6, 7, 8 and 9 present more results for different lengths.


Plain English Explanation
The paper presents a new way to design language models, which are artificial intelligence systems that can understand and generate human language. The traditional approach to building language models involves an "encoder-decoder" architecture, where the encoder processes the input text and the decoder generates the output text.
The researchers behind this paper, however, have come up with a different approach called "You Only Cache Once" (YOCO). The key idea is to store, or "cache," the output of the encoder and reuse it during the decoding process, rather than recomputing the encoder outputs for each target token. This helps to reduce the computational cost and memory requirements of the language model, making it more efficient and scalable.
By caching the encoder outputs, the YOCO architecture can avoid the need to repeatedly process the same information, which can be a significant bottleneck in traditional language models. This approach is particularly useful for tasks like text generation, where the model needs to generate long sequences of text.
Technical Explanation
The YOCO architecture is a decoder-only model that builds upon the successes of
and . The key innovation of YOCO is the introduction of a caching mechanism that stores the output of the encoder and reuses it during the decoding process.The YOCO model consists of a shared encoder network, a decoder network, and a caching mechanism. The encoder network processes the input text and produces a sequence of hidden states, which are then cached and reused by the decoder network during text generation. This caching approach allows the decoder to avoid the need to recompute the encoder outputs, which can be a significant source of computational overhead in traditional language models.
The researchers evaluate the YOCO architecture on a range of language modeling tasks, including machine translation and text generation. Their results show that YOCO can achieve comparable or better performance than traditional encoder-decoder models, while also reducing the computational cost and memory requirements of the model.
Critical Analysis
The YOCO architecture represents an interesting approach to improving the efficiency of language models, and the researchers' results suggest that it can be a viable alternative to traditional encoder-decoder architectures. However, there are a few potential limitations and areas for further research that could be explored:
-
The caching mechanism introduced in YOCO may not be effective for all types of language modeling tasks, particularly those that require more complex interactions between the input and output sequences.
and have explored alternative approaches to handling long-range dependencies in language models. -
The YOCO architecture may also be less effective for tasks that require more dynamic or flexible processing of the input, such as
detection or other multi-task learning scenarios. -
It would be interesting to see how the YOCO architecture compares to other decoder-only models, such as the ones explored in
, in terms of performance, efficiency, and scalability.
Overall, the YOCO architecture represents a promising approach to improving the efficiency of language models, and the researchers' work provides valuable insights into the design and optimization of these important AI systems.
Conclusion
The YOCO architecture introduced in this paper represents a novel approach to improving the efficiency and performance of language models. By caching the encoder outputs and reusing them during the decoding process, YOCO can reduce the computational cost and memory footprint of language models, making them more scalable and practical for real-world applications.
While the YOCO architecture may not be a perfect solution for all language modeling tasks, the researchers' work highlights the importance of continued innovation in this field. As AI systems become more powerful and ubiquitous, it is crucial that we find ways to make them more efficient and sustainable, without sacrificing their performance or capabilities. The YOCO architecture is a promising step in this direction, and it will be interesting to see how it evolves and is applied in future language modeling research and applications.
Inference method using parallel prefill and sequential generation. Early exit possible without output change.
1/2
0