A decoder-only foundation model for time-series forecasting
2310.10688
0
13
📈
Abstract
Motivated by recent advances in large language models for Natural Language Processing (NLP), we design a time-series foundation model for forecasting whose out-of-the-box zero-shot performance on a variety of public datasets comes close to the accuracy of state-of-the-art supervised forecasting models for each individual dataset. Our model is based on pretraining a patched-decoder style attention model on a large time-series corpus, and can work well across different forecasting history lengths, prediction lengths and temporal granularities.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Presents a "decoder-only" transformer model for time-series forecasting
- Aims to address limitations of existing sequence-to-sequence models
- Demonstrates strong performance on several benchmark datasets
Plain English Explanation
This paper introduces a new type of machine learning model called a "decoder-only" transformer for forecasting future values in time-series data. Time-series forecasting is the task of predicting what will happen next in a sequence of data points collected over time, such as stock prices or weather measurements.
Existing models for this task often use a "sequence-to-sequence" approach, where the model first encodes the input data into a compressed representation, and then decodes that representation to generate the forecast. The authors argue that this encoding step can limit the model's ability to capture long-range dependencies in the data.
In contrast, the "decoder-only" model presented in this paper is able to directly generate forecasts by attending to relevant parts of the input sequence, without first encoding it. This allows the model to better understand the underlying patterns and relationships in the data, leading to more accurate predictions.
The researchers evaluated their model on several standard time-series forecasting benchmarks and found that it outperformed other state-of-the-art approaches. This suggests that the "decoder-only" architecture could be a promising alternative to traditional sequence-to-sequence models for this type of task.
Technical Explanation
The key innovation of this work is the use of a decoder-only transformer architecture for time-series forecasting. Unlike typical sequence-to-sequence models, which first encode the input data and then decode the output, this model directly generates the forecast by attending to relevant parts of the input sequence.
The model consists of multiple transformer decoder layers, which use self-attention mechanisms to capture long-range dependencies in the data. The input to the model is a sequence of past observations, and the output is a sequence of predicted future values. The authors also incorporate various positional encoding schemes to capture the temporal structure of the data.
The researchers evaluated their model on several standard time-series forecasting benchmarks, including ETTH1, M4, and TA-MSTANL. They found that the decoder-only transformer outperformed other state-of-the-art models, such as LFTSformer and Informer, in terms of forecasting accuracy.
Critical Analysis
The authors acknowledge that their decoder-only transformer model may have limitations in handling complex, high-dimensional time-series data, as it relies solely on self-attention mechanisms without any explicit encoding step. This could potentially make the model less robust to noisy or irrelevant inputs.
Additionally, the paper does not provide a detailed analysis of the model's performance on different types of time-series data, such as those with strong seasonality or non-stationarity. It would be valuable to see how the decoder-only approach compares to other models in these more challenging scenarios.
Furthermore, the authors do not discuss the computational efficiency of their model, which is an important consideration for real-world deployment, especially in applications with strict latency requirements. A comparison to more lightweight time-series models, such as Tiny Time Mixers (TTMs), would help contextualize the tradeoffs between model complexity and forecasting performance.
Overall, the paper presents a promising new direction for time-series forecasting, but further research is needed to fully understand the strengths, weaknesses, and practical implications of the decoder-only transformer approach.
Conclusion
This paper introduces a novel "decoder-only" transformer model for time-series forecasting, which aims to address the limitations of traditional sequence-to-sequence architectures. The key idea is to directly generate forecasts by attending to relevant parts of the input sequence, without first encoding it into a compressed representation.
The authors demonstrate that this approach can outperform other state-of-the-art models on several benchmark datasets, suggesting that the decoder-only transformer could be a valuable tool for a wide range of time-series forecasting applications. However, the paper also highlights areas for further research, such as exploring the model's performance on more challenging data types and assessing its computational efficiency.
As the field of time-series forecasting continues to evolve, innovative architecture designs like the one presented in this paper will play an important role in pushing the boundaries of what's possible and helping to unlock new opportunities for practical applications.
Related Papers

A Survey of Time Series Foundation Models: Generalizing Time Series Representation with Large Language Mode
Jiexia Ye, Weiqi Zhang, Ke Yi, Yongzi Yu, Ziyue Li, Jia Li, Fugee Tsung
0
0
Time series data are ubiquitous across various domains, making time series analysis critically important. Traditional time series models are task-specific, featuring singular functionality and limited generalization capacity. Recently, large language foundation models have unveiled their remarkable capabilities for cross-task transferability, zero-shot/few-shot learning, and decision-making explainability. This success has sparked interest in the exploration of foundation models to solve multiple time series challenges simultaneously. There are two main research lines, namely pre-training foundation models from scratch for time series and adapting large language foundation models for time series. They both contribute to the development of a unified model that is highly generalizable, versatile, and comprehensible for time series analysis. This survey offers a 3E analytical framework for comprehensive examination of related research. Specifically, we examine existing works from three dimensions, namely Effectiveness, Efficiency and Explainability. In each dimension, we focus on discussing how related works devise tailored solution by considering unique challenges in the realm of time series. Furthermore, we provide a domain taxonomy to help followers keep up with the domain-specific advancements. In addition, we introduce extensive resources to facilitate the field's development, including datasets, open-source, time series libraries. A GitHub repository is also maintained for resource updates (https://github.com/start2020/Awesome-TimeSeries-LLM-FM).
5/8/2024
🧠
Time Series Continuous Modeling for Imputation and Forecasting with Implicit Neural Representations
Etienne Le Naour, Louis Serrano, L'eon Migus, Yuan Yin, Ghislain Agoua, Nicolas Baskiotis, Patrick Gallinari, Vincent Guigue
0
0
We introduce a novel modeling approach for time series imputation and forecasting, tailored to address the challenges often encountered in real-world data, such as irregular samples, missing data, or unaligned measurements from multiple sensors. Our method relies on a continuous-time-dependent model of the series' evolution dynamics. It leverages adaptations of conditional, implicit neural representations for sequential data. A modulation mechanism, driven by a meta-learning algorithm, allows adaptation to unseen samples and extrapolation beyond observed time-windows for long-term predictions. The model provides a highly flexible and unified framework for imputation and forecasting tasks across a wide range of challenging scenarios. It achieves state-of-the-art performance on classical benchmarks and outperforms alternative time-continuous models.
4/23/2024
Language Models Still Struggle to Zero-shot Reason about Time Series
Mike A. Merrill, Mingtian Tan, Vinayak Gupta, Tom Hartvigsen, Tim Althoff
0
0
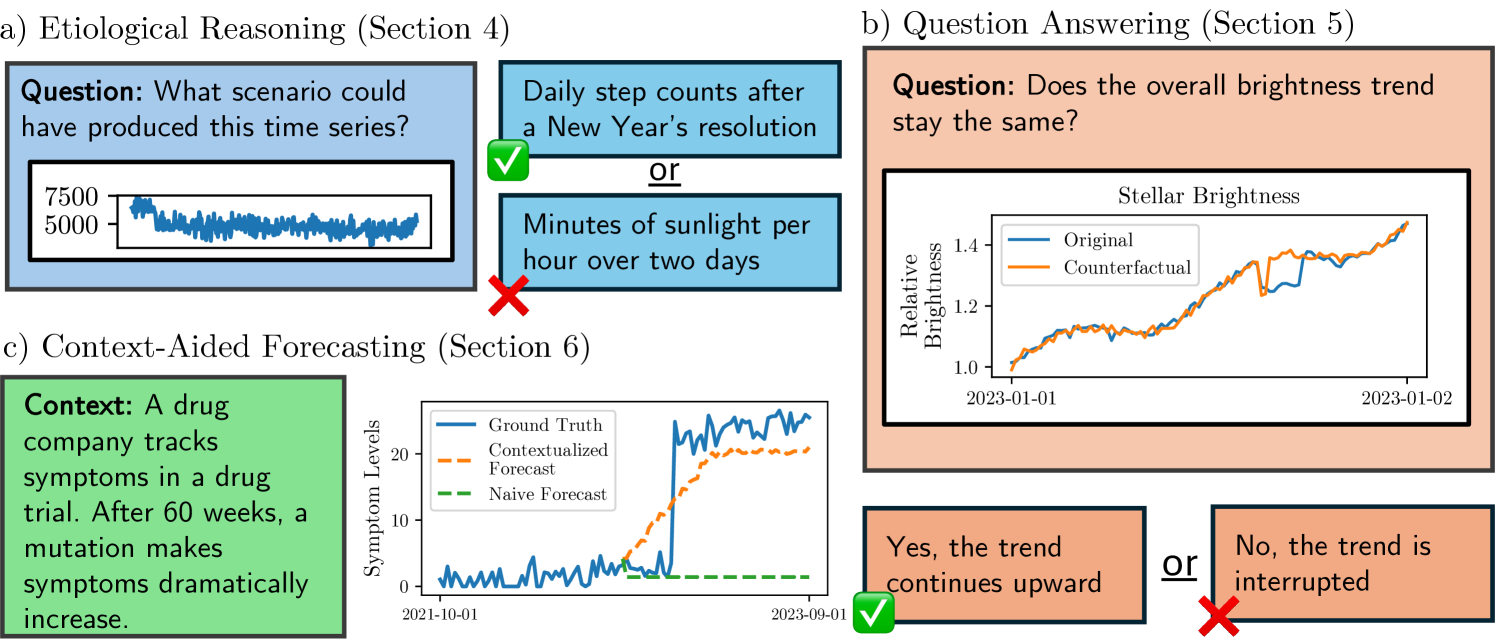
Time series are critical for decision-making in fields like finance and healthcare. Their importance has driven a recent influx of works passing time series into language models, leading to non-trivial forecasting on some datasets. But it remains unknown whether non-trivial forecasting implies that language models can reason about time series. To address this gap, we generate a first-of-its-kind evaluation framework for time series reasoning, including formal tasks and a corresponding dataset of multi-scale time series paired with text captions across ten domains. Using these data, we probe whether language models achieve three forms of reasoning: (1) Etiological Reasoning - given an input time series, can the language model identify the scenario that most likely created it? (2) Question Answering - can a language model answer factual questions about time series? (3) Context-Aided Forecasting - does highly relevant textual context improve a language model's time series forecasts? We find that otherwise highly-capable language models demonstrate surprisingly limited time series reasoning: they score marginally above random on etiological and question answering tasks (up to 30 percentage points worse than humans) and show modest success in using context to improve forecasting. These weakness showcase that time series reasoning is an impactful, yet deeply underdeveloped direction for language model research. We also make our datasets and code public at to support further research in this direction at https://github.com/behavioral-data/TSandLanguage
4/19/2024
🛸
TEMPO: Prompt-based Generative Pre-trained Transformer for Time Series Forecasting
Defu Cao, Furong Jia, Sercan O Arik, Tomas Pfister, Yixiang Zheng, Wen Ye, Yan Liu
0
0
The past decade has witnessed significant advances in time series modeling with deep learning. While achieving state-of-the-art results, the best-performing architectures vary highly across applications and domains. Meanwhile, for natural language processing, the Generative Pre-trained Transformer (GPT) has demonstrated impressive performance via training one general-purpose model across various textual datasets. It is intriguing to explore whether GPT-type architectures can be effective for time series, capturing the intrinsic dynamic attributes and leading to significant accuracy improvements. In this paper, we propose a novel framework, TEMPO, that can effectively learn time series representations. We focus on utilizing two essential inductive biases of the time series task for pre-trained models: (i) decomposition of the complex interaction between trend, seasonal and residual components; and (ii) introducing the design of prompts to facilitate distribution adaptation in different types of time series. TEMPO expands the capability for dynamically modeling real-world temporal phenomena from data within diverse domains. Our experiments demonstrate the superior performance of TEMPO over state-of-the-art methods on zero shot setting for a number of time series benchmark datasets. This performance gain is observed not only in scenarios involving previously unseen datasets but also in scenarios with multi-modal inputs. This compelling finding highlights TEMPO's potential to constitute a foundational model-building framework.
4/3/2024