Your Context Is Not an Array: Unveiling Random Access Limitations in Transformers

0
Sign in to get full access
Overview
- The paper explores the limitations of Transformer models in accessing long-term context during inference.
- It investigates the inability of Transformers to randomly access past information, which is crucial for tasks requiring long-range dependencies.
- The paper provides insights into the challenges Transformers face when dealing with long input sequences and proposes potential solutions.
Plain English Explanation
Transformer models, which have revolutionized many Natural Language Processing (NLP) tasks, have a fundamental limitation when it comes to accessing long-term context. These models, which are based on the Transformer architecture, struggle to randomly access information from earlier parts of the input sequence, a crucial capability for tasks that require understanding long-range dependencies.
The paper argues that the Transformer's reliance on self-attention, a mechanism that allows the model to focus on relevant parts of the input, is not sufficient for efficiently accessing and integrating information from distant locations in the input. This limitation becomes especially problematic when dealing with long input sequences, where the model's ability to maintain and utilize relevant context is crucial for accurate predictions.
To illustrate this issue, the authors provide a thought-provoking analogy. Imagine you're trying to remember a specific word or fact from a long book you read last year. The Transformer model is akin to a reader who can only access the book's pages in a fixed, sequential order, rather than being able to randomly flip to the relevant section. This restriction severely limits the model's ability to quickly and efficiently retrieve the necessary information.
The paper delves into the technical details of why Transformers struggle with long-term context, exploring the underlying architecture and the challenges posed by the self-attention mechanism. It also highlights the implications of this limitation for various NLP tasks, such as long-form question answering, language modeling, and document-level understanding.
By uncovering these limitations, the paper paves the way for future research and development of Transformer-based models that can more effectively handle long-range dependencies and overcome the context access challenges. This work is a crucial step in advancing the capabilities of these powerful language models and expanding their applicability to real-world scenarios that demand a deep understanding of long-form, contextual information.
Technical Explanation
The paper begins by highlighting the importance of long-term context in various natural language processing tasks, such as long-form question answering, language modeling, and document-level understanding. It then delves into the limitations of Transformer models in efficiently accessing and utilizing this long-term context during inference.
The authors argue that the Transformer's reliance on self-attention, a key component of the model, is not sufficient for effectively accessing and integrating information from distant locations in the input sequence. This inability to randomly access past information is a fundamental limitation of the Transformer architecture, which the paper aims to unveil and explore.
To further understand this issue, the authors provide a theoretical analysis of the asymptotic behavior of context learning in Transformer-based models. They demonstrate that the model's ability to access long-term context decays exponentially with the distance from the current position, making it challenging to effectively utilize relevant information from earlier parts of the input.
The paper also discusses the challenges Transformers face when dealing with long input sequences and the implications of this limitation for various NLP tasks. It highlights the need for Transformer-based models that can more efficiently handle long-range dependencies and maintain relevant contextual information throughout the input.
Finally, the paper explores potential solutions and approaches to overcome the limitations of Transformers in accessing long-term context, paving the way for future research and development in this area.
Critical Analysis
The paper provides a thorough and insightful analysis of the limitations of Transformer models in accessing long-term context during inference. The authors make a compelling case for the fundamental nature of this issue, rooted in the Transformer's self-attention mechanism and the asymptotic behavior of context learning.
One potential caveat mentioned in the paper is the possibility of context-dependent tasks, where the model's ability to randomly access past information may not be as crucial. The authors acknowledge that in certain scenarios, the Transformer's sequential processing may still be effective, and the limitations may not be as pronounced.
Additionally, the paper does not delve deeply into potential solutions or alternative architectural approaches that could address the identified limitations. While it suggests possible directions for future research, a more comprehensive exploration of remedies or novel model designs would have further strengthened the paper's impact.
Nevertheless, the paper's rigorous analysis and the clear articulation of the Transformer's context access challenges make it a valuable contribution to the field of language modeling and natural language processing. It encourages the research community to think critically about the limitations of current Transformer-based models and to explore innovative ways to enhance their ability to effectively utilize long-term contextual information.
Conclusion
This paper unveils a fundamental limitation of Transformer models: their inability to efficiently access and integrate long-term context during inference. By highlighting the challenges posed by the Transformer's self-attention mechanism and the asymptotic decay of context learning, the authors bring to light a crucial issue that has significant implications for various NLP tasks.
The insights provided in this paper pave the way for further research and development of Transformer-based models that can more effectively handle long-range dependencies and maintain relevant contextual information throughout the input. Addressing these limitations is crucial for advancing the capabilities of these powerful language models and expanding their applicability to real-world scenarios that demand a deep understanding of long-form, contextual information.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Your Context Is Not an Array: Unveiling Random Access Limitations in Transformers
MohammadReza Ebrahimi, Sunny Panchal, Roland Memisevic
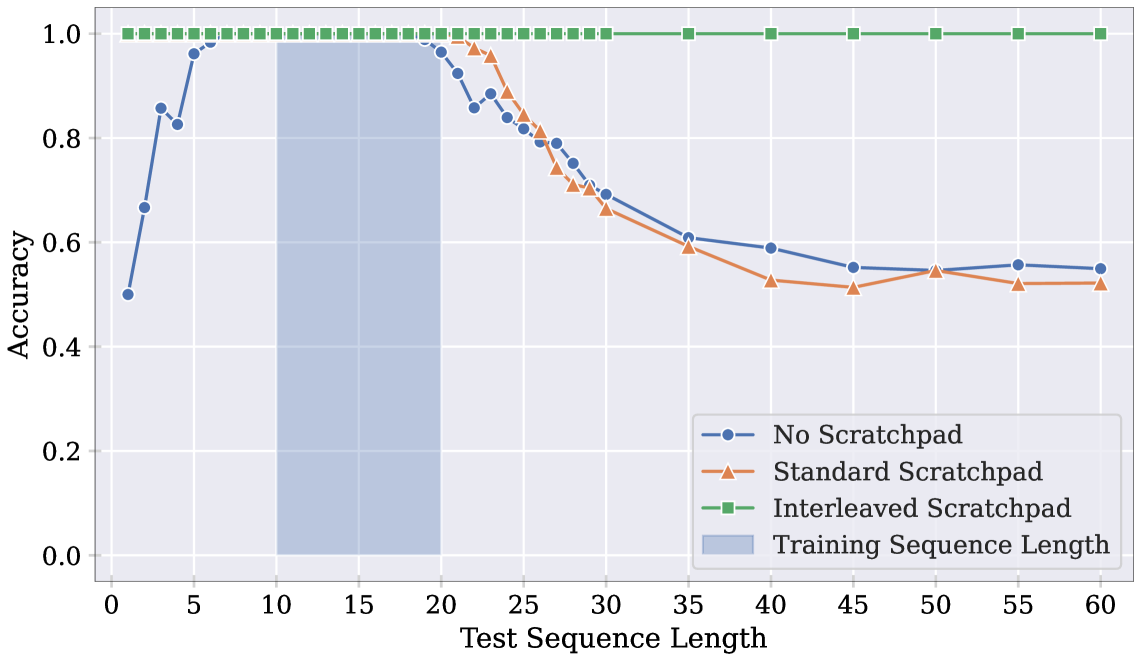
Despite their recent successes, Transformer-based large language models show surprising failure modes. A well-known example of such failure modes is their inability to length-generalize: solving problem instances at inference time that are longer than those seen during training. In this work, we further explore the root cause of this failure by performing a detailed analysis of model behaviors on the simple parity task. Our analysis suggests that length generalization failures are intricately related to a model's inability to perform random memory accesses within its context window. We present supporting evidence for this hypothesis by demonstrating the effectiveness of methodologies that circumvent the need for indexing or that enable random token access indirectly, through content-based addressing. We further show where and how the failure to perform random memory access manifests through attention map visualizations.
Read more8/13/2024
🤔
0
Equipping Transformer with Random-Access Reading for Long-Context Understanding
Chenghao Yang, Zi Yang, Nan Hua
Long-context modeling presents a significant challenge for transformer-based large language models (LLMs) due to the quadratic complexity of the self-attention mechanism and issues with length extrapolation caused by pretraining exclusively on short inputs. Existing methods address computational complexity through techniques such as text chunking, the kernel approach, and structured attention, and tackle length extrapolation problems through positional encoding, continued pretraining, and data engineering. These approaches typically require $textbf{sequential access}$ to the document, necessitating reading from the first to the last token. We contend that for goal-oriented reading of long documents, such sequential access is not necessary, and a proficiently trained model can learn to omit hundreds of less pertinent tokens. Inspired by human reading behaviors and existing empirical observations, we propose $textbf{random access}$, a novel reading strategy that enables transformers to efficiently process long documents without examining every token. Experimental results from pretraining, fine-tuning, and inference phases validate the efficacy of our method.
Read more5/24/2024
2
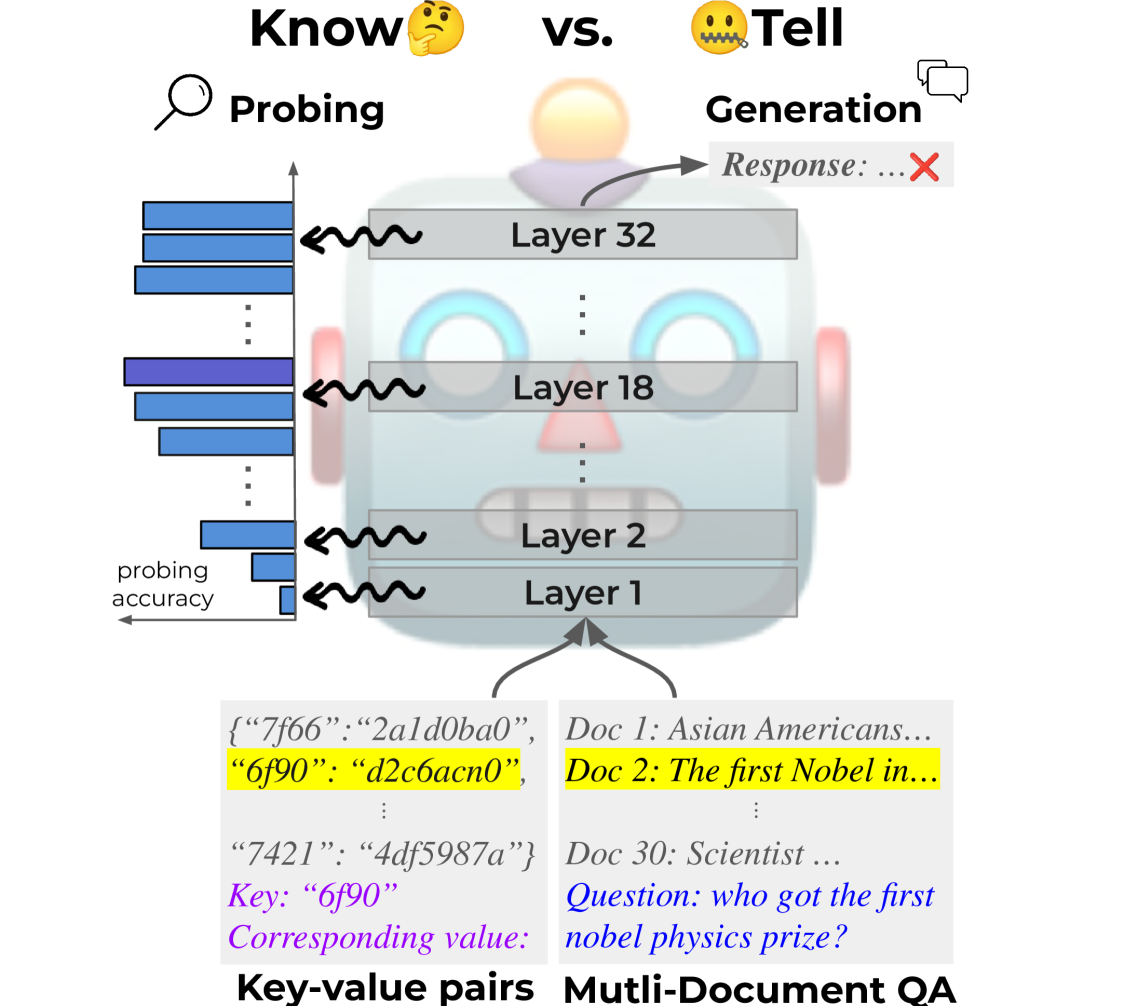
Insights into LLM Long-Context Failures: When Transformers Know but Don't Tell
Taiming Lu, Muhan Gao, Kuai Yu, Adam Byerly, Daniel Khashabi
Large Language Models (LLMs) exhibit positional bias, struggling to utilize information from the middle or end of long contexts. Our study explores LLMs' long-context reasoning by probing their hidden representations. We find that while LLMs encode the position of target information, they often fail to leverage this in generating accurate responses. This reveals a disconnect between information retrieval and utilization, a know but don't tell phenomenon. We further analyze the relationship between extraction time and final accuracy, offering insights into the underlying mechanics of transformer models.
Read more6/24/2024

0
Asymptotic theory of in-context learning by linear attention
Yue M. Lu, Mary I. Letey, Jacob A. Zavatone-Veth, Anindita Maiti, Cengiz Pehlevan
Transformers have a remarkable ability to learn and execute tasks based on examples provided within the input itself, without explicit prior training. It has been argued that this capability, known as in-context learning (ICL), is a cornerstone of Transformers' success, yet questions about the necessary sample complexity, pretraining task diversity, and context length for successful ICL remain unresolved. Here, we provide a precise answer to these questions in an exactly solvable model of ICL of a linear regression task by linear attention. We derive sharp asymptotics for the learning curve in a phenomenologically-rich scaling regime where the token dimension is taken to infinity; the context length and pretraining task diversity scale proportionally with the token dimension; and the number of pretraining examples scales quadratically. We demonstrate a double-descent learning curve with increasing pretraining examples, and uncover a phase transition in the model's behavior between low and high task diversity regimes: In the low diversity regime, the model tends toward memorization of training tasks, whereas in the high diversity regime, it achieves genuine in-context learning and generalization beyond the scope of pretrained tasks. These theoretical insights are empirically validated through experiments with both linear attention and full nonlinear Transformer architectures.
Read more5/21/2024