Equipping Transformer with Random-Access Reading for Long-Context Understanding

0
🤔
Sign in to get full access
Overview
- Transformers, a type of large language model (LLM), face challenges in processing long-context documents due to the computational complexity of the self-attention mechanism and issues with length extrapolation.
- Existing methods address these challenges through techniques like text chunking, kernel approaches, and structured attention, but these typically require sequential access to the document.
- This paper proposes a novel "random access" reading strategy that enables transformers to efficiently process long documents without examining every token.
Plain English Explanation
Transformers are a type of AI model that are very good at understanding and generating human language. However, when it comes to processing long documents, transformers face some challenges. The way they work, called the "self-attention mechanism," becomes very computationally complex as the document gets longer. There are also issues with the model's ability to properly handle documents that are longer than what it was trained on.
Researchers have come up with some solutions to these problems, like breaking documents into smaller chunks or using specialized attention mechanisms. But these approaches still require the model to read through the document sequentially, from the first word to the last. The key insight of this paper is that for many practical tasks, like answering questions about a long document, the model doesn't actually need to read every single word. Humans don't do that either - we skim and skip over less important parts.
The paper proposes a new "random access" reading strategy, inspired by how humans read. Instead of going through the document linearly, the model can learn to focus on the most relevant parts and skip over less important sections. The researchers show that this approach is effective, allowing the model to process long documents efficiently without sacrificing performance.
Technical Explanation
The authors identify two key challenges in applying transformers to long-context modeling: the quadratic complexity of the self-attention mechanism and issues with length extrapolation caused by pretraining exclusively on short inputs.
Existing methods to address these challenges include text chunking, the kernel approach, and structured attention. However, these techniques typically require sequential access to the document, reading from the first to the last token.
The authors propose a novel "random access" reading strategy, inspired by human reading behaviors and empirical observations. This approach enables transformers to efficiently process long documents without examining every token. The key idea is that a well-trained model can learn to selectively focus on the most pertinent parts of the document and skip over less relevant sections.
Experimental results from pretraining, fine-tuning, and inference phases validate the efficacy of the random access method, demonstrating its ability to maintain performance while significantly reducing the number of tokens processed.
Critical Analysis
The paper presents a compelling approach to address the challenges of long-context modeling with transformers. The random access strategy is an innovative solution that is well-grounded in observations of human reading behavior.
One potential limitation is that the effectiveness of the approach may depend on the specific task and domain. For some applications, skipping over certain parts of the document could lead to a loss of important information. Further research is needed to understand the generalizability of the random access method across different use cases.
Additionally, the computational benefits of the random access strategy are not quantified in detail. While the paper demonstrates the method's efficacy, a more thorough analysis of the efficiency gains, in terms of both time and memory requirements, would strengthen the case for its practical adoption.
Overall, the paper offers a promising direction for improving the performance of transformers on long-context tasks. The random access approach is a creative and well-executed solution that merits further exploration and refinement.
Conclusion
This paper presents a novel "random access" reading strategy that enables transformers to efficiently process long documents without examining every token. By selectively focusing on the most pertinent parts of the document and skipping over less relevant sections, the method addresses the key challenges of computational complexity and length extrapolation faced by transformer-based LLMs.
The experimental results validate the effectiveness of the random access approach, suggesting its potential to enhance the performance of transformers on a variety of long-context tasks. This work represents an important step towards developing more efficient and capable language models that can better handle the demands of real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤔
0
Equipping Transformer with Random-Access Reading for Long-Context Understanding
Chenghao Yang, Zi Yang, Nan Hua
Long-context modeling presents a significant challenge for transformer-based large language models (LLMs) due to the quadratic complexity of the self-attention mechanism and issues with length extrapolation caused by pretraining exclusively on short inputs. Existing methods address computational complexity through techniques such as text chunking, the kernel approach, and structured attention, and tackle length extrapolation problems through positional encoding, continued pretraining, and data engineering. These approaches typically require $textbf{sequential access}$ to the document, necessitating reading from the first to the last token. We contend that for goal-oriented reading of long documents, such sequential access is not necessary, and a proficiently trained model can learn to omit hundreds of less pertinent tokens. Inspired by human reading behaviors and existing empirical observations, we propose $textbf{random access}$, a novel reading strategy that enables transformers to efficiently process long documents without examining every token. Experimental results from pretraining, fine-tuning, and inference phases validate the efficacy of our method.
Read more5/24/2024
0
Your Context Is Not an Array: Unveiling Random Access Limitations in Transformers
MohammadReza Ebrahimi, Sunny Panchal, Roland Memisevic
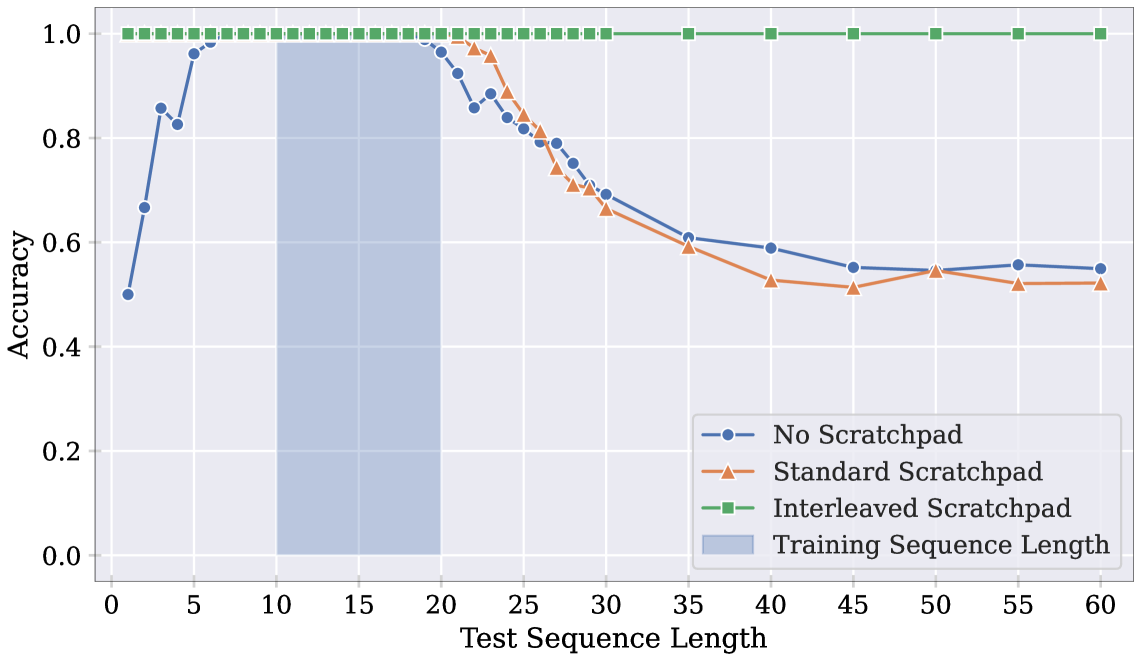
Despite their recent successes, Transformer-based large language models show surprising failure modes. A well-known example of such failure modes is their inability to length-generalize: solving problem instances at inference time that are longer than those seen during training. In this work, we further explore the root cause of this failure by performing a detailed analysis of model behaviors on the simple parity task. Our analysis suggests that length generalization failures are intricately related to a model's inability to perform random memory accesses within its context window. We present supporting evidence for this hypothesis by demonstrating the effectiveness of methodologies that circumvent the need for indexing or that enable random token access indirectly, through content-based addressing. We further show where and how the failure to perform random memory access manifests through attention map visualizations.
Read more8/13/2024
27
Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention
Tsendsuren Munkhdalai, Manaal Faruqui, Siddharth Gopal
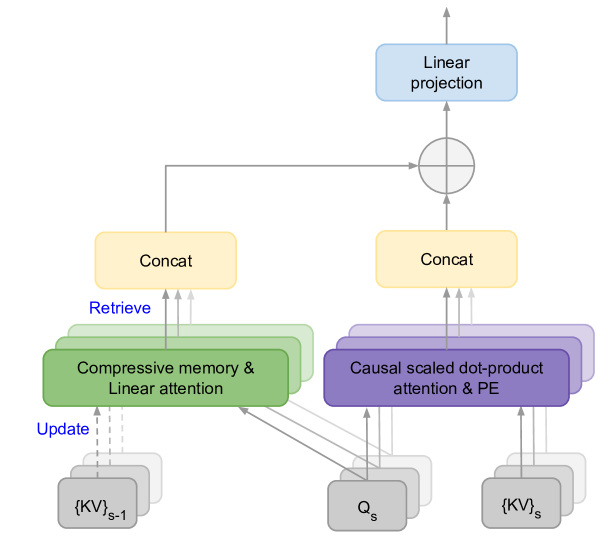
This work introduces an efficient method to scale Transformer-based Large Language Models (LLMs) to infinitely long inputs with bounded memory and computation. A key component in our proposed approach is a new attention technique dubbed Infini-attention. The Infini-attention incorporates a compressive memory into the vanilla attention mechanism and builds in both masked local attention and long-term linear attention mechanisms in a single Transformer block. We demonstrate the effectiveness of our approach on long-context language modeling benchmarks, 1M sequence length passkey context block retrieval and 500K length book summarization tasks with 1B and 8B LLMs. Our approach introduces minimal bounded memory parameters and enables fast streaming inference for LLMs.
Read more8/13/2024
⚙️
0
Chunk, Align, Select: A Simple Long-sequence Processing Method for Transformers
Jiawen Xie, Pengyu Cheng, Xiao Liang, Yong Dai, Nan Du
Although dominant in natural language processing, transformer-based models remain challenged by the task of long-sequence processing, because the computational cost of self-attention operations in transformers swells quadratically with the input sequence length. To alleviate the complexity of long-sequence processing, we propose a simple framework to enable the offthe-shelf pre-trained transformers to process much longer sequences, while the computation and memory costs remain growing linearly with the input sequence lengths. More specifically, our method divides each long-sequence input into a batch of chunks, then aligns the interchunk information during the encoding steps, and finally selects the most representative hidden states from the encoder for the decoding process. To extract inter-chunk semantic information, we align the start and end token embeddings among chunks in each encoding transformer block. To learn an effective hidden selection policy, we design a dual updating scheme inspired by reinforcement learning, which regards the decoders of transformers as environments, and the downstream performance metrics as the rewards to evaluate the hidden selection actions. Our empirical results on real-world long-text summarization and reading comprehension tasks demonstrate effective improvements compared to prior longsequence processing baselines.
Read more7/8/2024