Zero-shot prompt-based classification: topic labeling in times of foundation models in German Tweets
2406.18239
0
0
Abstract
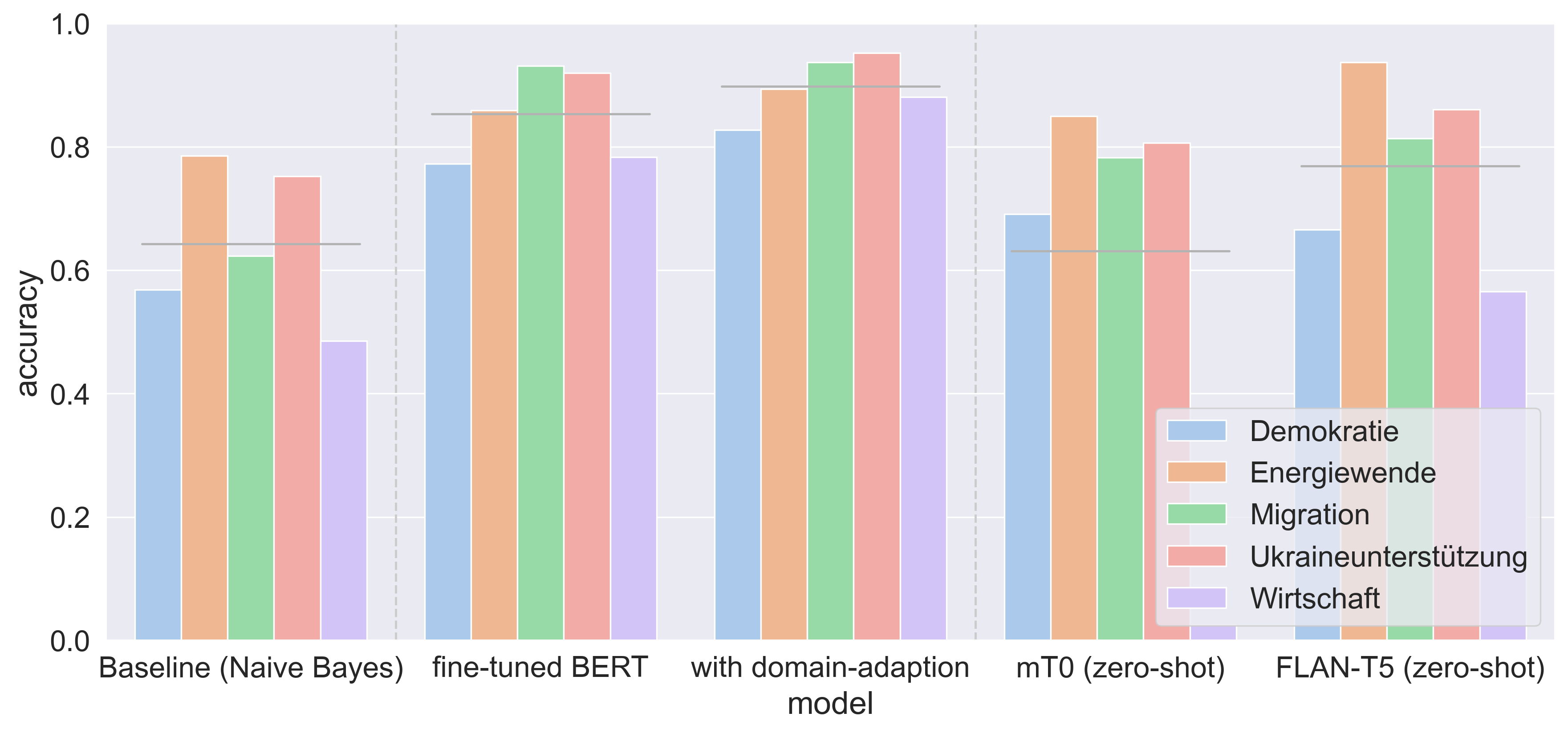
Filtering and annotating textual data are routine tasks in many areas, like social media or news analytics. Automating these tasks allows to scale the analyses wrt. speed and breadth of content covered and decreases the manual effort required. Due to technical advancements in Natural Language Processing, specifically the success of large foundation models, a new tool for automating such annotation processes by using a text-to-text interface given written guidelines without providing training samples has become available. In this work, we assess these advancements in-the-wild by empirically testing them in an annotation task on German Twitter data about social and political European crises. We compare the prompt-based results with our human annotation and preceding classification approaches, including Naive Bayes and a BERT-based fine-tuning/domain adaptation pipeline. Our results show that the prompt-based approach - despite being limited by local computation resources during the model selection - is comparable with the fine-tuned BERT but without any annotated training data. Our findings emphasize the ongoing paradigm shift in the NLP landscape, i.e., the unification of downstream tasks and elimination of the need for pre-labeled training data.
Create account to get full access
Overview
• This paper explores the use of zero-shot prompt-based classification for topic labeling of German tweets, leveraging the capabilities of foundation models in a time when they are becoming increasingly prominent.
Plain English Explanation
• The researchers wanted to see if they could use language models, which have been trained on a vast amount of text data, to automatically classify the topics of tweets written in German without having to provide the models with labeled examples of each topic.
• This "zero-shot" approach means the models have to figure out the topics just based on the language prompts provided, without any prior training on the specific tweet data.
• The researchers tested this approach on a dataset of German tweets and found that the language models were able to reasonably classify the tweets into different topics, even without being explicitly trained on that data.
• This suggests that these powerful language models can be applied to new tasks and datasets in a flexible way, without requiring extensive additional training. This could be very useful for tasks like automatically categorizing large volumes of online text.
Technical Explanation
• The researchers evaluated several different language models, including BERT and GPT-2 variants, for their ability to perform zero-shot topic classification on a dataset of German tweets.
• They provided the models with prompts that described the different topic categories, and had the models predict the most relevant topic for each tweet based on the language used.
• The models were tested on a held-out set of tweets to measure their classification accuracy, and the researchers also explored strategies for improving performance such as using ensemble methods.
• The results showed that the language models were able to achieve reasonably strong topic classification, with the best models reaching up to 70% accuracy on the test set.
Critical Analysis
• The paper acknowledges that the zero-shot performance, while promising, is not yet at the level that would be required for many real-world applications. Further research and refinement of the prompting strategies may be needed.
• Additionally, the dataset used is relatively small, and topic classification may be easier on shorter social media text compared to longer, more complex documents. Expanding the evaluation to a wider range of text types could provide a more comprehensive assessment.
• There is also the open question of how well these language models would generalize to less common or emerging topics, beyond the predefined categories used in this study. Robust zero-shot classification in the face of shifting trends and conversations remains an area for further investigation.
Conclusion
• This paper demonstrates the potential for using powerful language models in a zero-shot, prompt-based approach to automatically classify the topics of German tweets.
• While not yet at the level of human-level performance, the results suggest that foundation models can be leveraged for flexible, data-efficient classification tasks, which could have significant implications for a wide range of text-based applications.
• As language models continue to advance, further research on prompt engineering, model robustness, and real-world deployments will be crucial for unlocking the full potential of these techniques.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Prompt Design Matters for Computational Social Science Tasks but in Unpredictable Ways
Shubham Atreja, Joshua Ashkinaze, Lingyao Li, Julia Mendelsohn, Libby Hemphill
0
0
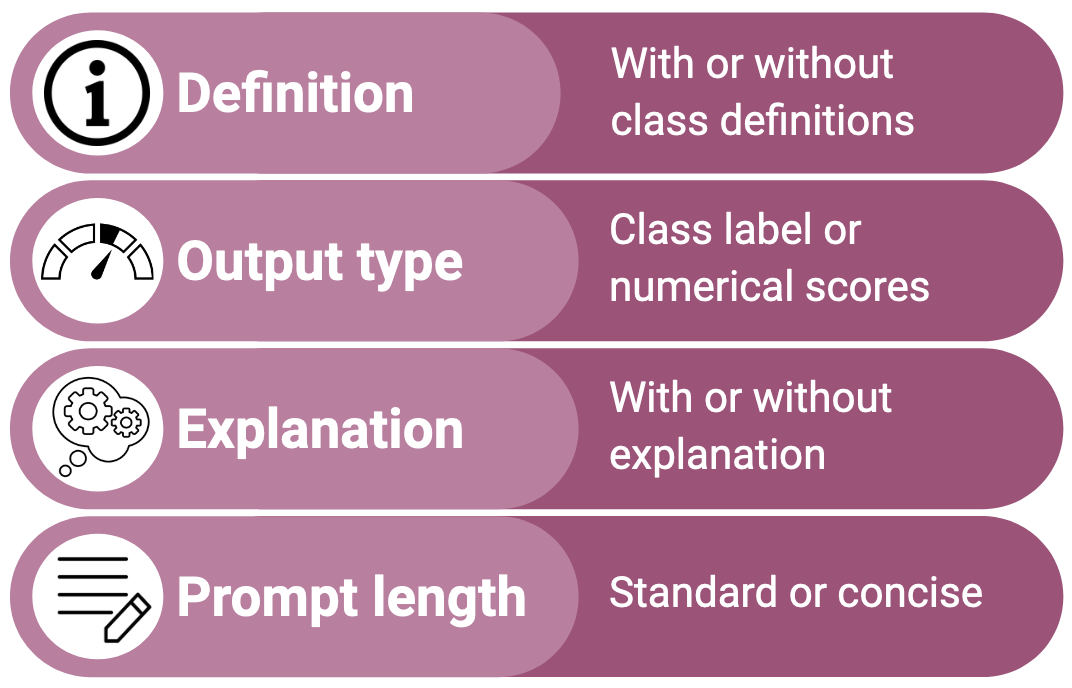
Manually annotating data for computational social science tasks can be costly, time-consuming, and emotionally draining. While recent work suggests that LLMs can perform such annotation tasks in zero-shot settings, little is known about how prompt design impacts LLMs' compliance and accuracy. We conduct a large-scale multi-prompt experiment to test how model selection (ChatGPT, PaLM2, and Falcon7b) and prompt design features (definition inclusion, output type, explanation, and prompt length) impact the compliance and accuracy of LLM-generated annotations on four CSS tasks (toxicity, sentiment, rumor stance, and news frames). Our results show that LLM compliance and accuracy are highly prompt-dependent. For instance, prompting for numerical scores instead of labels reduces all LLMs' compliance and accuracy. The overall best prompting setup is task-dependent, and minor prompt changes can cause large changes in the distribution of generated labels. By showing that prompt design significantly impacts the quality and distribution of LLM-generated annotations, this work serves as both a warning and practical guide for researchers and practitioners.
6/19/2024
Language Models for Text Classification: Is In-Context Learning Enough?
Aleksandra Edwards, Jose Camacho-Collados
0
0
Recent foundational language models have shown state-of-the-art performance in many NLP tasks in zero- and few-shot settings. An advantage of these models over more standard approaches based on fine-tuning is the ability to understand instructions written in natural language (prompts), which helps them generalise better to different tasks and domains without the need for specific training data. This makes them suitable for addressing text classification problems for domains with limited amounts of annotated instances. However, existing research is limited in scale and lacks understanding of how text generation models combined with prompting techniques compare to more established methods for text classification such as fine-tuning masked language models. In this paper, we address this research gap by performing a large-scale evaluation study for 16 text classification datasets covering binary, multiclass, and multilabel problems. In particular, we compare zero- and few-shot approaches of large language models to fine-tuning smaller language models. We also analyse the results by prompt, classification type, domain, and number of labels. In general, the results show how fine-tuning smaller and more efficient language models can still outperform few-shot approaches of larger language models, which have room for improvement when it comes to text classification.
4/16/2024
Prompting-based Synthetic Data Generation for Few-Shot Question Answering
Maximilian Schmidt, Andrea Bartezzaghi, Ngoc Thang Vu
0
0
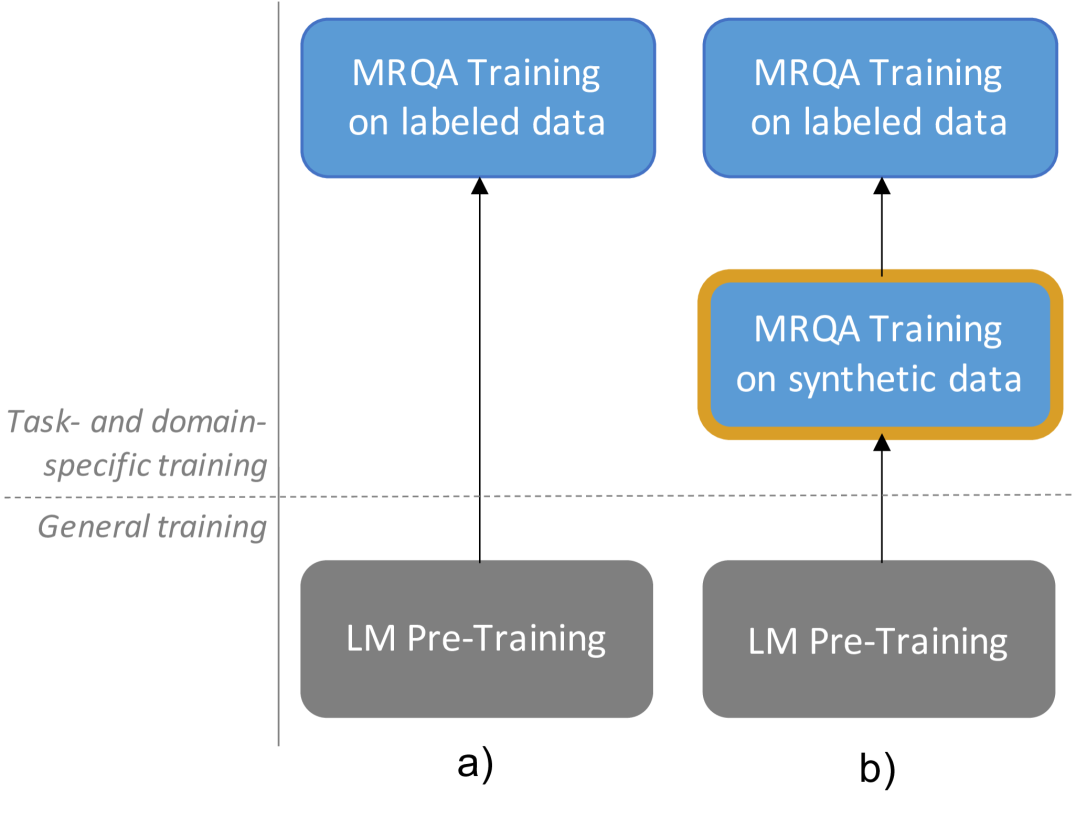
Although language models (LMs) have boosted the performance of Question Answering, they still need plenty of data. Data annotation, in contrast, is a time-consuming process. This especially applies to Question Answering, where possibly large documents have to be parsed and annotated with questions and their corresponding answers. Furthermore, Question Answering models often only work well for the domain they were trained on. Since annotation is costly, we argue that domain-agnostic knowledge from LMs, such as linguistic understanding, is sufficient to create a well-curated dataset. With this motivation, we show that using large language models can improve Question Answering performance on various datasets in the few-shot setting compared to state-of-the-art approaches. For this, we perform data generation leveraging the Prompting framework, suggesting that language models contain valuable task-agnostic knowledge that can be used beyond the common pre-training/fine-tuning scheme. As a result, we consistently outperform previous approaches on few-shot Question Answering.
5/16/2024

Detecting Statements in Text: A Domain-Agnostic Few-Shot Solution
Sandrine Chausson, Bjorn Ross
0
0
Many tasks related to Computational Social Science and Web Content Analysis involve classifying pieces of text based on the claims they contain. State-of-the-art approaches usually involve fine-tuning models on large annotated datasets, which are costly to produce. In light of this, we propose and release a qualitative and versatile few-shot learning methodology as a common paradigm for any claim-based textual classification task. This methodology involves defining the classes as arbitrarily sophisticated taxonomies of claims, and using Natural Language Inference models to obtain the textual entailment between these and a corpus of interest. The performance of these models is then boosted by annotating a minimal sample of data points, dynamically sampled using the well-established statistical heuristic of Probabilistic Bisection. We illustrate this methodology in the context of three tasks: climate change contrarianism detection, topic/stance classification and depression-relates symptoms detection. This approach rivals traditional pre-train/fine-tune approaches while drastically reducing the need for data annotation.
5/10/2024