Zero-shot Text-guided Infinite Image Synthesis with LLM guidance

0

Sign in to get full access
Overview
- This paper introduces a novel approach for zero-shot text-guided infinite image synthesis, leveraging the guidance of large language models (LLMs).
- The proposed method allows users to generate high-quality, context-aware images that seamlessly extend beyond the initial canvas, all without the need for any image-specific training.
- The authors demonstrate the versatility of their approach across a range of subject domains, from landscapes and cityscapes to product designs and abstract art.
Plain English Explanation
The researchers have developed a new way to create images that can continue endlessly beyond the original canvas, just by providing a text description. This is done without the need for any specific training on images - the system can generate these extended images from scratch, guided only by the language model.
This means you could start with a simple sketch or initial image, and then use text to describe what you want to see next, and the system will continue generating more of the image to match your description. For example, you could start with a city scene and then describe adding a park, some skyscrapers, and a river, and the system will seamlessly expand the image to include those new elements.
The key innovation is using a large language model, which is trained on vast amounts of text data, to guide the image generation process. This allows the system to understand the semantic meaning and contextual relationships in the text prompt, and then generate visuals that coherently match that description, even if it goes beyond the original starting point.
The researchers show this system works well across a wide range of subjects, from landscapes and architecture to abstract art and product designs. This could be very useful for artists, designers, and even everyday users who want to easily create expansive, imaginative images from simple starting points.
Technical Explanation
The core of this approach is the integration of a large language model (LLM) to guide the text-to-image generation process. Unlike previous methods that relied on image-specific training, this system can generate high-quality, context-aware images in a zero-shot setting - where no image-level data is required.
The authors leverage the rich semantic and world knowledge encoded within the LLM to translate the input text prompts into meaningful visual representations. This is accomplished through a two-stage process:
- Text Encoding: The input text is encoded using the LLM, capturing the semantic and contextual meaning of the prompt.
- Diffusion-based Image Generation: A diffusion model is then used to generate the output image, with the LLM encoding serving as guidance to ensure the generated content aligns with the textual description.
This guidance-based approach allows the system to seamlessly extend the initial image canvas, producing coherent and visually compelling outputs that match the user's text prompt.
The authors demonstrate the versatility of their method by evaluating it on a diverse set of subject domains, including landscape generation, cityscapes, product designs, and abstract art. The results show that the system can generate high-quality, contextually relevant images that maintain visual coherence and consistency, even when expanding far beyond the initial canvas.
Critical Analysis
One key strength of this approach is its ability to perform zero-shot text-guided image synthesis, eliminating the need for image-specific training data. This makes the system more flexible and scalable, as it can be readily applied to a wide range of subject domains without the need for laborious data collection and model retraining.
However, the authors acknowledge some limitations in their work. For example, the system may struggle with generating highly detailed or photorealistic images, as the diffusion model used is primarily focused on producing visually coherent and semantically aligned outputs. Additionally, the authors note that the system's performance can be sensitive to the specific language model used, and further research may be needed to explore more robust LLM architectures and fine-tuning strategies.
Another potential area of concern is the potential for biases or errors in the LLM's knowledge, which could be propagated to the generated images. The authors suggest exploring methods to mitigate such biases, such as prompt engineering or the incorporation of additional safety constraints.
Overall, this work represents an exciting advancement in the field of text-guided image generation, showcasing the potential for LLMs to enable powerful and flexible image synthesis capabilities. As the research in this area continues to evolve, it will be important to address the remaining challenges and ensure the responsible development of these technologies.
Conclusion
The proposed approach for zero-shot text-guided infinite image synthesis demonstrates the power of leveraging large language models to guide the generation of visually coherent and semantically aligned images. By translating text prompts into meaningful visual representations, the system can seamlessly extend the initial image canvas, producing compelling outputs across a wide range of subject domains.
This work opens up new possibilities for creative expression, design, and even everyday image manipulation tasks, where users can easily generate and explore expansive visual narratives based on their textual descriptions. As the field of text-guided image generation continues to advance, the insights gained from this research will likely have far-reaching implications for the development of more intuitive and powerful visual creation tools.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Zero-shot Text-guided Infinite Image Synthesis with LLM guidance
Soyeong Kwon, Taegyeong Lee, Taehwan Kim
Text-guided image editing and generation methods have diverse real-world applications. However, text-guided infinite image synthesis faces several challenges. First, there is a lack of text-image paired datasets with high-resolution and contextual diversity. Second, expanding images based on text requires global coherence and rich local context understanding. Previous studies have mainly focused on limited categories, such as natural landscapes, and also required to train on high-resolution images with paired text. To address these challenges, we propose a novel approach utilizing Large Language Models (LLMs) for both global coherence and local context understanding, without any high-resolution text-image paired training dataset. We train the diffusion model to expand an image conditioned on global and local captions generated from the LLM and visual feature. At the inference stage, given an image and a global caption, we use the LLM to generate a next local caption to expand the input image. Then, we expand the image using the global caption, generated local caption and the visual feature to consider global consistency and spatial local context. In experiments, our model outperforms the baselines both quantitatively and qualitatively. Furthermore, our model demonstrates the capability of text-guided arbitrary-sized image generation in zero-shot manner with LLM guidance.
Read more7/18/2024
0
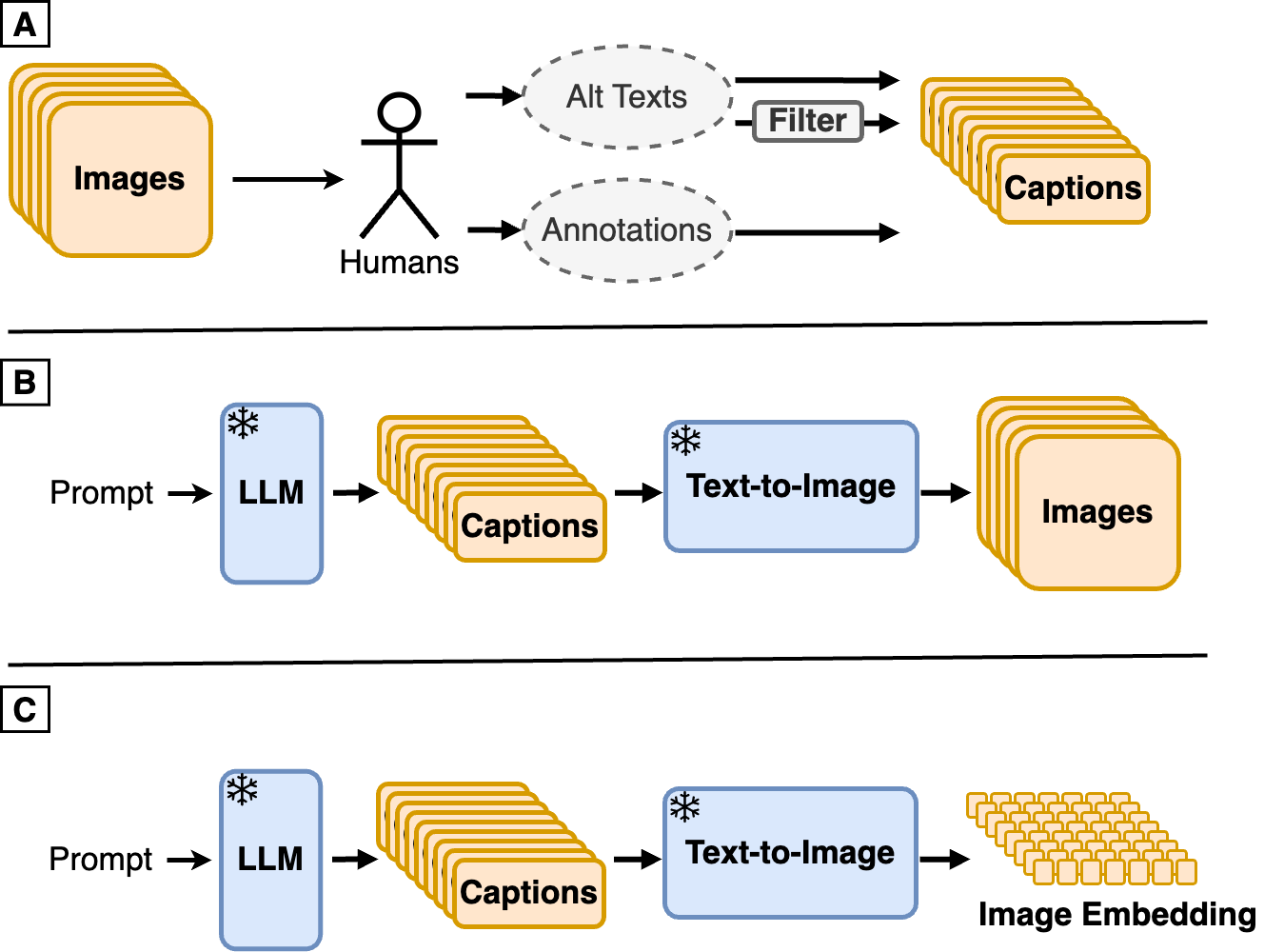
Synth$^2$: Boosting Visual-Language Models with Synthetic Captions and Image Embeddings
Sahand Sharifzadeh, Christos Kaplanis, Shreya Pathak, Dharshan Kumaran, Anastasija Ilic, Jovana Mitrovic, Charles Blundell, Andrea Banino
The creation of high-quality human-labeled image-caption datasets presents a significant bottleneck in the development of Visual-Language Models (VLMs). In this work, we investigate an approach that leverages the strengths of Large Language Models (LLMs) and image generation models to create synthetic image-text pairs for efficient and effective VLM training. Our method employs a pretrained text-to-image model to synthesize image embeddings from captions generated by an LLM. Despite the text-to-image model and VLM initially being trained on the same data, our approach leverages the image generator's ability to create novel compositions, resulting in synthetic image embeddings that expand beyond the limitations of the original dataset. Extensive experiments demonstrate that our VLM, finetuned on synthetic data achieves comparable performance to models trained solely on human-annotated data, while requiring significantly less data. Furthermore, we perform a set of analyses on captions which reveals that semantic diversity and balance are key aspects for better downstream performance. Finally, we show that synthesizing images in the image embedding space is 25% faster than in the pixel space. We believe our work not only addresses a significant challenge in VLM training but also opens up promising avenues for the development of self-improving multi-modal models.
Read more6/10/2024
🛸
0
An Empirical Study and Analysis of Text-to-Image Generation Using Large Language Model-Powered Textual Representation
Zhiyu Tan, Mengping Yang, Luozheng Qin, Hao Yang, Ye Qian, Qiang Zhou, Cheng Zhang, Hao Li
One critical prerequisite for faithful text-to-image generation is the accurate understanding of text inputs. Existing methods leverage the text encoder of the CLIP model to represent input prompts. However, the pre-trained CLIP model can merely encode English with a maximum token length of 77. Moreover, the model capacity of the text encoder from CLIP is relatively limited compared to Large Language Models (LLMs), which offer multilingual input, accommodate longer context, and achieve superior text representation. In this paper, we investigate LLMs as the text encoder to improve the language understanding in text-to-image generation. Unfortunately, training text-to-image generative model with LLMs from scratch demands significant computational resources and data. To this end, we introduce a three-stage training pipeline that effectively and efficiently integrates the existing text-to-image model with LLMs. Specifically, we propose a lightweight adapter that enables fast training of the text-to-image model using the textual representations from LLMs. Extensive experiments demonstrate that our model supports not only multilingual but also longer input context with superior image generation quality.
Read more7/19/2024
🏷️
0
Generation-driven Contrastive Self-training for Zero-shot Text Classification with Instruction-following LLM
Ruohong Zhang, Yau-Shian Wang, Yiming Yang
The remarkable performance of large language models (LLMs) in zero-shot language understanding has garnered significant attention. However, employing LLMs for large-scale inference or domain-specific fine-tuning requires immense computational resources due to their substantial model size. To overcome these limitations, we introduce a novel method, namely GenCo, which leverages the strong generative power of LLMs to assist in training a smaller and more adaptable language model. In our method, an LLM plays an important role in the self-training loop of a smaller model in two important ways. Firstly, the LLM is used to augment each input instance with a variety of possible continuations, enriching its semantic context for better understanding. Secondly, it helps crafting additional high-quality training pairs, by rewriting input texts conditioned on predicted labels. This ensures the generated texts are highly relevant to the predicted labels, alleviating the prediction error during pseudo-labeling, while reducing the dependency on large volumes of unlabeled text. In our experiments, GenCo outperforms previous state-of-the-art methods when only limited ($<5%$ of original) in-domain text data is available. Notably, our approach surpasses the performance of Alpaca-7B with human prompts, highlighting the potential of leveraging LLM for self-training.
Read more4/16/2024