Zero-Shot Tokenizer Transfer
2405.07883
2
0
🔄
Abstract
Language models (LMs) are bound to their tokenizer, which maps raw text to a sequence of vocabulary items (tokens). This restricts their flexibility: for example, LMs trained primarily on English may still perform well in other natural and programming languages, but have vastly decreased efficiency due to their English-centric tokenizer. To mitigate this, we should be able to swap the original LM tokenizer with an arbitrary one, on the fly, without degrading performance. Hence, in this work we define a new problem: Zero-Shot Tokenizer Transfer (ZeTT). The challenge at the core of ZeTT is finding embeddings for the tokens in the vocabulary of the new tokenizer. Since prior heuristics for initializing embeddings often perform at chance level in a ZeTT setting, we propose a new solution: we train a hypernetwork taking a tokenizer as input and predicting the corresponding embeddings. We empirically demonstrate that the hypernetwork generalizes to new tokenizers both with encoder (e.g., XLM-R) and decoder LLMs (e.g., Mistral-7B). Our method comes close to the original models' performance in cross-lingual and coding tasks while markedly reducing the length of the tokenized sequence. We also find that the remaining gap can be quickly closed by continued training on less than 1B tokens. Finally, we show that a ZeTT hypernetwork trained for a base (L)LM can also be applied to fine-tuned variants without extra training. Overall, our results make substantial strides toward detaching LMs from their tokenizer.
Create account to get full access
Overview
- Language models (LMs) are constrained by their tokenizers, which convert raw text into a sequence of vocabulary items (tokens).
- This tokenizer-dependence limits the flexibility of LMs, as they may perform poorly when used with tokenizers not aligned with their training data (e.g., an English-trained LM using a non-English tokenizer).
- The paper introduces a new problem called Zero-Shot Tokenizer Transfer (ZeTT), which aims to enable swapping an LM's tokenizer with an arbitrary one without degrading performance.
- The key challenge in ZeTT is finding embeddings for the tokens in the new tokenizer's vocabulary, as prior methods often perform poorly in this setting.
Plain English Explanation
Language models are powerful AI systems that can understand and generate human language. However, these models are tightly coupled with the specific set of words (called a "vocabulary") that they were trained on. This vocabulary is determined by a component called a "tokenizer," which converts raw text into a sequence of vocabulary items that the language model can process.
The problem with this tokenizer-dependence is that it limits the flexibility of language models. For example, a language model trained primarily on English text may still work reasonably well on other languages or even programming code, but its performance will be much worse because its tokenizer is optimized for English.
To address this issue, the researchers introduce a new concept called "Zero-Shot Tokenizer Transfer" (ZeTT). The idea behind ZeTT is to enable swapping out the original tokenizer of a language model with a completely different one, without degrading the model's performance. The key challenge is to find good "embeddings" - numerical representations of the words - for the new tokenizer's vocabulary, as existing methods often fail in this scenario.
To solve this problem, the researchers propose training a "hypernetwork" - a neural network that can take a tokenizer as input and generate the corresponding word embeddings. This hypernetwork can then be used to quickly adapt a language model to work with a new tokenizer, without needing to retrain the entire model from scratch.
Technical Explanation
The paper addresses the problem of Zero-Shot Tokenizer Transfer (ZeTT), which aims to enable swapping the tokenizer of a language model (LM) with an arbitrary new tokenizer without degrading the model's performance.
The core challenge in ZeTT is finding good embeddings for the tokens in the new tokenizer's vocabulary, as prior heuristic methods often perform poorly in this setting. To solve this, the researchers propose training a hypernetwork that takes a tokenizer as input and predicts the corresponding token embeddings.
The hypernetwork is trained on a diverse set of tokenizers and is then evaluated on its ability to transfer to new, unseen tokenizers. The researchers demonstrate that their hypernetwork-based approach can effectively adapt both encoder (e.g., XLM-R) and decoder language models to new tokenizers, achieving performance close to the original models while significantly reducing the length of the tokenized sequence.
Additionally, the researchers find that the remaining performance gap can be quickly closed by continued training on a small amount of data (less than 1 billion tokens). They also show that a ZeTT hypernetwork trained for a base (L)LM can be applied to fine-tuned variants without additional training.
Critical Analysis
The paper presents a promising approach to addressing the fundamental challenge of tokenizer-dependence in language models. By introducing the concept of Zero-Shot Tokenizer Transfer and proposing a hypernetwork-based solution, the researchers have made substantial progress towards detaching LMs from their tokenizers.
One potential limitation of the approach is that it may not fully capture the nuanced relationships between tokens and their embeddings, which can be crucial for certain tasks. Additionally, the performance of the hypernetwork could be sensitive to the diversity and quality of the training tokenizers, and the researchers do not explore the limits of this in the paper.
It would be interesting to see further research on the theoretical underpinnings of tokenization in LLMs and how the proposed hypernetwork-based approach can be extended or generalized to other aspects of language model adaptability and cross-lingual transfer.
Conclusion
The paper introduces a novel approach to the problem of tokenizer-dependence in language models, which has been a long-standing challenge in the field. By training a hypernetwork to generate token embeddings for arbitrary tokenizers, the researchers have demonstrated a practical solution to Zero-Shot Tokenizer Transfer that can be applied to a wide range of LMs and tasks.
This work represents an important step towards more flexible and adaptable language models, which could have far-reaching implications for natural language processing and its applications across various domains. The findings of this paper pave the way for further research into language-independent representations and the theoretical underpinnings of tokenization in LLMs, ultimately leading to more powerful and versatile AI language technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔄
Key ingredients for effective zero-shot cross-lingual knowledge transfer in generative tasks
Nadezhda Chirkova, Vassilina Nikoulina
0
0
Zero-shot cross-lingual knowledge transfer enables a multilingual pretrained language model, finetuned on a task in one language, make predictions for this task in other languages. While being broadly studied for natural language understanding tasks, the described setting is understudied for generation. Previous works notice a frequent problem of generation in a wrong language and propose approaches to address it, usually using mT5 as a backbone model. In this work we compare various approaches proposed from the literature in unified settings, also including alternative backbone models, namely mBART and NLLB-200. We first underline the importance of tuning learning rate used for finetuning, which helps to substantially alleviate the problem of generation in the wrong language. Then, we show that with careful learning rate tuning, the simple full finetuning of the model acts as a very strong baseline and alternative approaches bring only marginal improvements. Finally, we find that mBART performs similarly to mT5 of the same size, and NLLB-200 can be competitive in some cases. Our final zero-shot models reach the performance of the approach based on data translation which is usually considered as an upper baseline for zero-shot cross-lingual transfer in generation.
4/23/2024
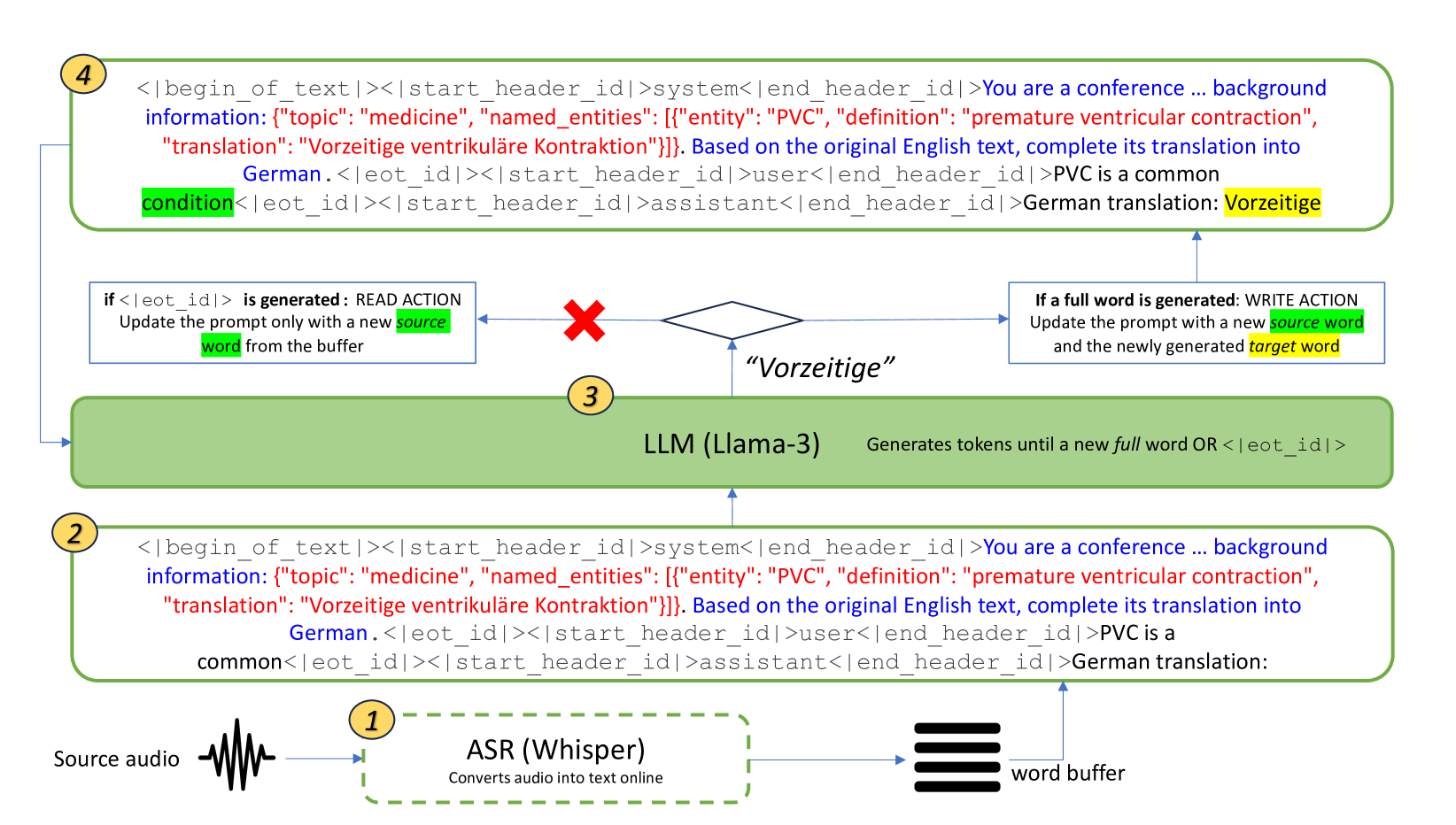
LLMs Are Zero-Shot Context-Aware Simultaneous Translators
Roman Koshkin, Katsuhito Sudoh, Satoshi Nakamura
0
0
The advent of transformers has fueled progress in machine translation. More recently large language models (LLMs) have come to the spotlight thanks to their generality and strong performance in a wide range of language tasks, including translation. Here we show that open-source LLMs perform on par with or better than some state-of-the-art baselines in simultaneous machine translation (SiMT) tasks, zero-shot. We also demonstrate that injection of minimal background information, which is easy with an LLM, brings further performance gains, especially on challenging technical subject-matter. This highlights LLMs' potential for building next generation of massively multilingual, context-aware and terminologically accurate SiMT systems that require no resource-intensive training or fine-tuning.
6/24/2024

Languages Transferred Within the Encoder: On Representation Transfer in Zero-Shot Multilingual Translation
Zhi Qu, Chenchen Ding, Taro Watanabe
0
0
Understanding representation transfer in multilingual neural machine translation can reveal the representational issue causing the zero-shot translation deficiency. In this work, we introduce the identity pair, a sentence translated into itself, to address the lack of the base measure in multilingual investigations, as the identity pair represents the optimal state of representation among any language transfers. In our analysis, we demonstrate that the encoder transfers the source language to the representational subspace of the target language instead of the language-agnostic state. Thus, the zero-shot translation deficiency arises because representations are entangled with other languages and are not transferred effectively to the target language. Based on our findings, we propose two methods: 1) low-rank language-specific embedding at the encoder, and 2) language-specific contrastive learning of the representation at the decoder. The experimental results on Europarl-15, TED-19, and OPUS-100 datasets show that our methods substantially enhance the performance of zero-shot translations by improving language transfer capacity, thereby providing practical evidence to support our conclusions.
6/13/2024
💬
Empirical study of pretrained multilingual language models for zero-shot cross-lingual knowledge transfer in generation
Nadezhda Chirkova, Sheng Liang, Vassilina Nikoulina
0
0
Zero-shot cross-lingual knowledge transfer enables the multilingual pretrained language model (mPLM), finetuned on a task in one language, make predictions for this task in other languages. While being broadly studied for natural language understanding tasks, the described setting is understudied for generation. Previous works notice a frequent problem of generation in a wrong language and propose approaches to address it, usually using mT5 as a backbone model. In this work, we test alternative mPLMs, such as mBART and NLLB-200, considering full finetuning and parameter-efficient finetuning with adapters. We find that mBART with adapters performs similarly to mT5 of the same size, and NLLB-200 can be competitive in some cases. We also underline the importance of tuning learning rate used for finetuning, which helps to alleviate the problem of generation in the wrong language.
4/23/2024