Zero123-6D: Zero-shot Novel View Synthesis for RGB Category-level 6D Pose Estimation

0

Sign in to get full access
Overview
- This paper presents "Zero123-6D", a novel approach for zero-shot 6D pose estimation of RGB category-level objects.
- The key idea is to use novel view synthesis to generate diverse training data for efficient 6D pose estimation without CAD models.
- The method achieves state-of-the-art results on the Pix3D and ObjectNet3D benchmarks for category-level 6D pose estimation.
Plain English Explanation
The researchers have developed a new method called "Zero123-6D" that can estimate the 6D internal link pose (position and orientation) of objects from RGB images, without needing 3D CAD models of the objects.
Traditionally, 6D pose estimation requires having detailed 3D models of the objects. This new approach instead uses internal link novel view synthesis to generate diverse training images from limited real data. This allows the pose estimation model to learn effectively without access to 3D CAD models.
The key innovation is generating these novel views in a way that is internal link consistent with the underlying 3D structure of the objects. This ensures the pose estimation model learns robust features that generalize well to new object instances and views.
The researchers show their Zero123-6D method achieves state-of-the-art results on standard benchmarks for internal link category-level 6D pose estimation. This is an important capability for applications like robotic manipulation and augmented reality, where we want systems to understand the 3D poses of general object categories, not just specific instances.
Technical Explanation
The core of the Zero123-6D approach is a internal link novel view synthesis module that can generate diverse training views of objects from limited real data. This is coupled with a 6D pose estimation network that learns robust features from these generated views.
The novel view synthesis is made internal link consistent by modeling the underlying 3D structure of the object categories. This is achieved using a internal link multi-view diffusion model that can generate coherent novel views from a single input image.
The 6D pose estimation network is trained end-to-end on the synthetically generated views, along with any available real training data. This allows the model to learn effective features for estimating the 6D pose without access to 3D CAD models.
Extensive experiments on the Pix3D and ObjectNet3D benchmarks demonstrate the effectiveness of the Zero123-6D approach, achieving state-of-the-art results for internal link category-level 6D pose estimation.
Critical Analysis
The key limitation of the Zero123-6D approach is that it relies on the quality and diversity of the novel views generated by the synthesis module. If the generated views do not accurately capture the true 3D structure and appearance variations of the object categories, the pose estimation model may struggle to generalize.
Additionally, the paper does not explore the robustness of the method to occlusions, clutter, or other real-world challenges that may arise in practical applications. Further research is needed to assess the method's performance in more complex and realistic scenarios.
That said, the consistent novel view synthesis approach is a promising direction for internal link zero-shot learning problems like category-level 6D pose estimation. By leveraging the underlying 3D structure of object categories, the method can generate diverse training data without access to 3D CAD models.
Conclusion
The Zero123-6D method presents an effective solution for zero-shot 6D pose estimation of RGB category-level objects. By using novel view synthesis to generate diverse training data, the approach can learn robust pose estimation models without relying on 3D CAD models.
This is an important advancement for applications like robotic manipulation and augmented reality, where we want systems to understand the 3D poses of general object categories, not just specific instances. The consistent novel view synthesis technique is a valuable contribution that could have broader impacts on internal link zero-shot learning problems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Zero123-6D: Zero-shot Novel View Synthesis for RGB Category-level 6D Pose Estimation
Francesco Di Felice, Alberto Remus, Stefano Gasperini, Benjamin Busam, Lionel Ott, Federico Tombari, Roland Siegwart, Carlo Alberto Avizzano
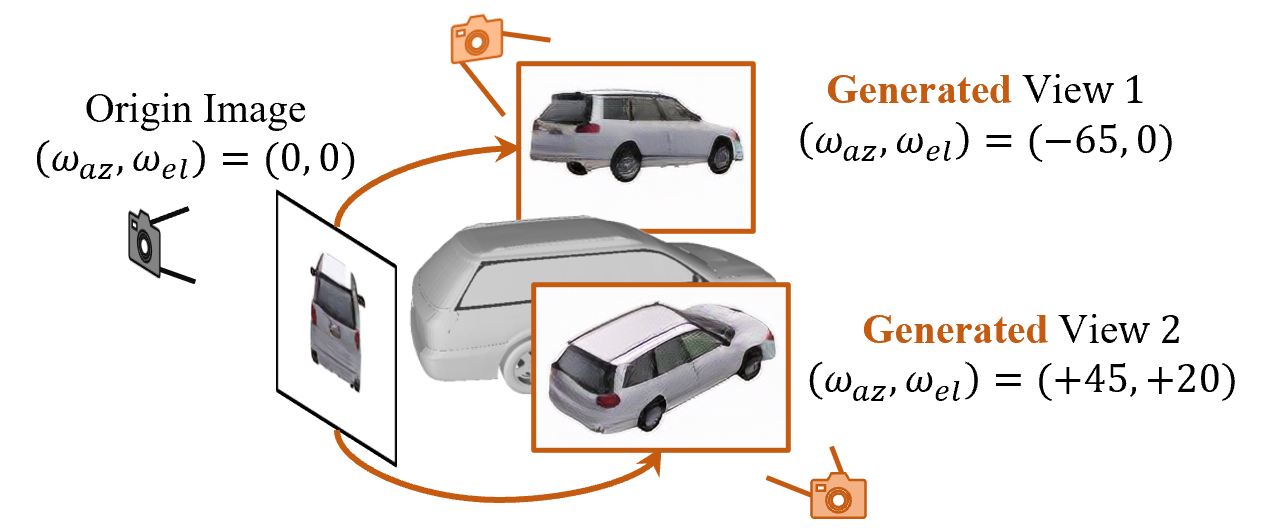
Estimating the pose of objects through vision is essential to make robotic platforms interact with the environment. Yet, it presents many challenges, often related to the lack of flexibility and generalizability of state-of-the-art solutions. Diffusion models are a cutting-edge neural architecture transforming 2D and 3D computer vision, outlining remarkable performances in zero-shot novel-view synthesis. Such a use case is particularly intriguing for reconstructing 3D objects. However, localizing objects in unstructured environments is rather unexplored. To this end, this work presents Zero123-6D, the first work to demonstrate the utility of Diffusion Model-based novel-view-synthesizers in enhancing RGB 6D pose estimation at category-level, by integrating them with feature extraction techniques. Novel View Synthesis allows to obtain a coarse pose that is refined through an online optimization method introduced in this work to deal with intra-category geometric differences. In such a way, the outlined method shows reduction in data requirements, removal of the necessity of depth information in zero-shot category-level 6D pose estimation task, and increased performance, quantitatively demonstrated through experiments on the CO3D dataset.
Read more7/31/2024
0
Learning a Category-level Object Pose Estimator without Pose Annotations
Fengrui Tian, Yaoyao Liu, Adam Kortylewski, Yueqi Duan, Shaoyi Du, Alan Yuille, Angtian Wang
3D object pose estimation is a challenging task. Previous works always require thousands of object images with annotated poses for learning the 3D pose correspondence, which is laborious and time-consuming for labeling. In this paper, we propose to learn a category-level 3D object pose estimator without pose annotations. Instead of using manually annotated images, we leverage diffusion models (e.g., Zero-1-to-3) to generate a set of images under controlled pose differences and propose to learn our object pose estimator with those images. Directly using the original diffusion model leads to images with noisy poses and artifacts. To tackle this issue, firstly, we exploit an image encoder, which is learned from a specially designed contrastive pose learning, to filter the unreasonable details and extract image feature maps. Additionally, we propose a novel learning strategy that allows the model to learn object poses from those generated image sets without knowing the alignment of their canonical poses. Experimental results show that our method has the capability of category-level object pose estimation from a single shot setting (as pose definition), while significantly outperforming other state-of-the-art methods on the few-shot category-level object pose estimation benchmarks.
Read more4/9/2024

0
Ctrl123: Consistent Novel View Synthesis via Closed-Loop Transcription
Hongxiang Zhao, Xili Dai, Jianan Wang, Shengbang Tong, Jingyuan Zhang, Weida Wang, Lei Zhang, Yi Ma
Large image diffusion models have demonstrated zero-shot capability in novel view synthesis (NVS). However, existing diffusion-based NVS methods struggle to generate novel views that are accurately consistent with the corresponding ground truth poses and appearances, even on the training set. This consequently limits the performance of downstream tasks, such as image-to-multiview generation and 3D reconstruction. We realize that such inconsistency is largely due to the fact that it is difficult to enforce accurate pose and appearance alignment directly in the diffusion training, as mostly done by existing methods such as Zero123. To remedy this problem, we propose Ctrl123, a closed-loop transcription-based NVS diffusion method that enforces alignment between the generated view and ground truth in a pose-sensitive feature space. Our extensive experiments demonstrate the effectiveness of Ctrl123 on the tasks of NVS and 3D reconstruction, achieving significant improvements in both multiview-consistency and pose-consistency over existing methods.
Read more6/26/2024

0
MultiDiff: Consistent Novel View Synthesis from a Single Image
Norman Muller, Katja Schwarz, Barbara Roessle, Lorenzo Porzi, Samuel Rota Bul`o, Matthias Nie{ss}ner, Peter Kontschieder
We introduce MultiDiff, a novel approach for consistent novel view synthesis of scenes from a single RGB image. The task of synthesizing novel views from a single reference image is highly ill-posed by nature, as there exist multiple, plausible explanations for unobserved areas. To address this issue, we incorporate strong priors in form of monocular depth predictors and video-diffusion models. Monocular depth enables us to condition our model on warped reference images for the target views, increasing geometric stability. The video-diffusion prior provides a strong proxy for 3D scenes, allowing the model to learn continuous and pixel-accurate correspondences across generated images. In contrast to approaches relying on autoregressive image generation that are prone to drifts and error accumulation, MultiDiff jointly synthesizes a sequence of frames yielding high-quality and multi-view consistent results -- even for long-term scene generation with large camera movements, while reducing inference time by an order of magnitude. For additional consistency and image quality improvements, we introduce a novel, structured noise distribution. Our experimental results demonstrate that MultiDiff outperforms state-of-the-art methods on the challenging, real-world datasets RealEstate10K and ScanNet. Finally, our model naturally supports multi-view consistent editing without the need for further tuning.
Read more6/27/2024