ZeroG: Investigating Cross-dataset Zero-shot Transferability in Graphs
2402.11235
0
0
Abstract
With the development of foundation models such as large language models, zero-shot transfer learning has become increasingly significant. This is highlighted by the generative capabilities of NLP models like GPT-4, and the retrieval-based approaches of CV models like CLIP, both of which effectively bridge the gap between seen and unseen data. In the realm of graph learning, the continuous emergence of new graphs and the challenges of human labeling also amplify the necessity for zero-shot transfer learning, driving the exploration of approaches that can generalize across diverse graph data without necessitating dataset-specific and label-specific fine-tuning. In this study, we extend such paradigms to zero-shot transferability in graphs by introducing ZeroG, a new framework tailored to enable cross-dataset generalization. Addressing the inherent challenges such as feature misalignment, mismatched label spaces, and negative transfer, we leverage a language model to encode both node attributes and class semantics, ensuring consistent feature dimensions across datasets. We also propose a prompt-based subgraph sampling module that enriches the semantic information and structure information of extracted subgraphs using prompting nodes and neighborhood aggregation, respectively. We further adopt a lightweight fine-tuning strategy that reduces the risk of overfitting and maintains the zero-shot learning efficacy of the language model. The results underscore the effectiveness of our model in achieving significant cross-dataset zero-shot transferability, opening pathways for the development of graph foundation models. Codes and data are available at https://github.com/NineAbyss/ZeroG.
Create account to get full access
Overview
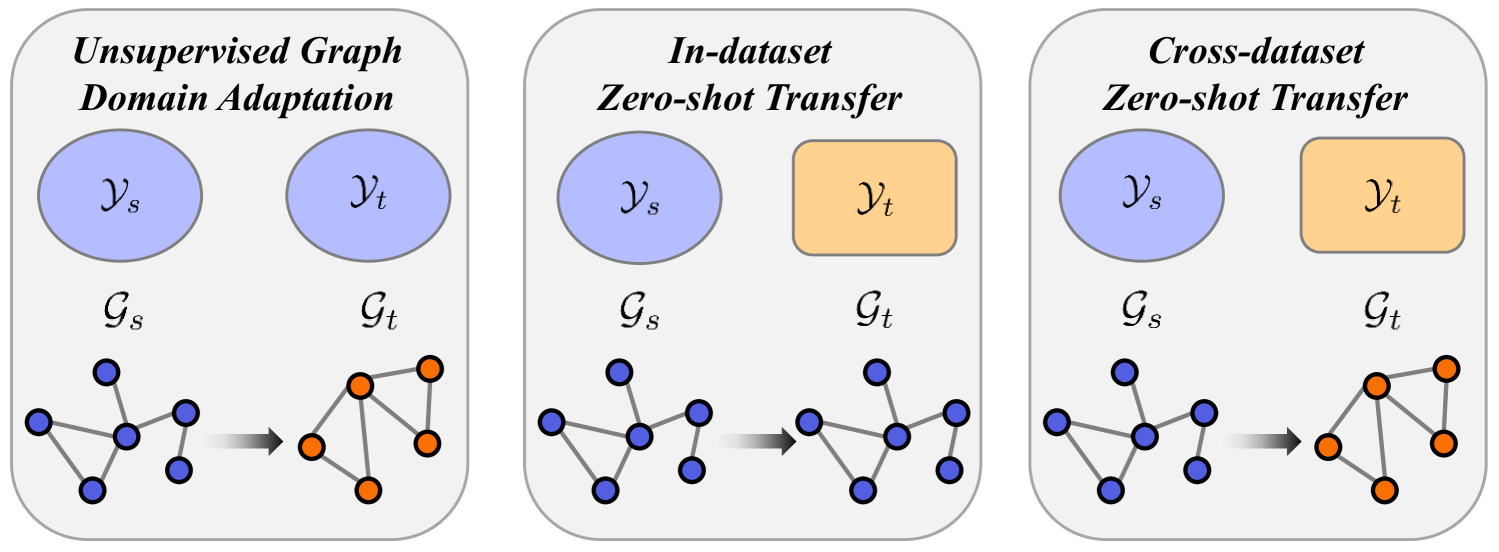
- This paper investigates the ability of graph neural networks to transfer knowledge across different graph datasets, a process known as cross-dataset zero-shot transferability.
- The authors propose a novel framework called ZeroG that aims to improve the performance of graph neural networks in this zero-shot setting.
- The paper explores the challenges of cross-dataset transfer learning in graphs and introduces techniques to address these challenges, such as pre-training on diverse datasets and leveraging structural similarity between graphs.
Plain English Explanation
Graph neural networks are a powerful type of machine learning model that can analyze and make predictions on data structured as graphs, where entities are represented as nodes and the relationships between them as edges. These models have shown great success in a variety of applications, from recommender systems to drug discovery.
However, one limitation of graph neural networks is that they often struggle to perform well when applied to a new graph dataset that is significantly different from the one they were trained on. This is known as the cross-dataset zero-shot transferability problem. The ZeroG: Investigating Cross-dataset Zero-shot Transferability in Graphs paper aims to address this challenge.
The key idea behind the ZeroG framework is to develop techniques that allow graph neural networks to better transfer their knowledge from one dataset to another, even when the datasets have very different characteristics. This could involve pre-training the model on a diverse set of graph datasets to build up a more general understanding of graph structures, or finding ways to leverage the structural similarities between the source and target datasets.
By improving cross-dataset zero-shot transferability, the ZeroG approach could make graph neural networks more versatile and applicable to a wider range of real-world problems, where the available data may not perfectly match the training data used to develop the model. This could lead to more robust and generalizable graph-based solutions in areas like drug discovery, recommender systems, and natural language processing.
Technical Explanation
The ZeroG: Investigating Cross-dataset Zero-shot Transferability in Graphs paper starts by defining the problem of cross-dataset zero-shot transferability in the context of graph neural networks. The authors explain that while graph neural networks have achieved state-of-the-art performance on many graph-related tasks, their performance often deteriorates significantly when applied to a new dataset that differs substantially from the one used for training.
To address this challenge, the authors propose the ZeroG framework, which consists of several key components:
- Pre-training on diverse datasets: The paper explores the idea of pre-training the graph neural network on a wide range of graph datasets, with the goal of building up a more general understanding of graph structures that can be transferred to new domains.
- Leveraging structural similarity: The authors investigate methods for identifying and exploiting the structural similarities between the source and target graph datasets, which can help the model better adapt to the new data.
- Dataset-agnostic representation learning: The paper introduces techniques to learn dataset-agnostic node representations, which can facilitate the transfer of knowledge across different graph datasets.
The authors conduct extensive experiments on a variety of real-world graph datasets, evaluating the performance of ZeroG against several baseline approaches. The results demonstrate that the ZeroG framework can significantly improve the cross-dataset zero-shot transferability of graph neural networks, outperforming other state-of-the-art methods.
Critical Analysis
The ZeroG: Investigating Cross-dataset Zero-shot Transferability in Graphs paper makes a valuable contribution to the field of graph neural networks by addressing an important practical challenge: the inability of these models to perform well on graph datasets that differ significantly from their training data.
One potential limitation of the research, as acknowledged by the authors, is that the proposed techniques may not be effective in scenarios where the structural differences between the source and target datasets are too large. In such cases, further research may be needed to develop more robust and adaptable transfer learning mechanisms.
Additionally, the paper could have provided more discussion on the potential biases or limitations of the datasets used in the experiments, as well as the broader societal implications of improved cross-dataset zero-shot transferability in graph neural networks. Exploring the data efficiency and zero-shot learning capabilities of diffusion models could also provide relevant insights to consider.
Overall, the ZeroG: Investigating Cross-dataset Zero-shot Transferability in Graphs paper presents a valuable contribution to the field and offers promising directions for further research on improving the generalization and transferability of graph neural networks.
Conclusion
The ZeroG: Investigating Cross-dataset Zero-shot Transferability in Graphs paper addresses an important challenge in the field of graph neural networks: the difficulty of transferring knowledge from one graph dataset to another, even when the datasets have very different characteristics.
By introducing the ZeroG framework, which combines techniques like pre-training on diverse datasets and leveraging structural similarity, the authors demonstrate significant improvements in cross-dataset zero-shot transferability. This research has the potential to make graph neural networks more versatile and applicable to a wider range of real-world problems, where the available data may not perfectly match the training data used to develop the model.
As the use of graph-based models continues to grow in areas like drug discovery, recommender systems, and natural language processing, the insights and techniques presented in this paper could have far-reaching implications for the development of more robust and generalizable graph-based solutions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

GraphGPT: Graph Instruction Tuning for Large Language Models
Jiabin Tang, Yuhao Yang, Wei Wei, Lei Shi, Lixin Su, Suqi Cheng, Dawei Yin, Chao Huang
0
0
Graph Neural Networks (GNNs) have evolved to understand graph structures through recursive exchanges and aggregations among nodes. To enhance robustness, self-supervised learning (SSL) has become a vital tool for data augmentation. Traditional methods often depend on fine-tuning with task-specific labels, limiting their effectiveness when labeled data is scarce. Our research tackles this by advancing graph model generalization in zero-shot learning environments. Inspired by the success of large language models (LLMs), we aim to create a graph-oriented LLM capable of exceptional generalization across various datasets and tasks without relying on downstream graph data. We introduce the GraphGPT framework, which integrates LLMs with graph structural knowledge through graph instruction tuning. This framework includes a text-graph grounding component to link textual and graph structures and a dual-stage instruction tuning approach with a lightweight graph-text alignment projector. These innovations allow LLMs to comprehend complex graph structures and enhance adaptability across diverse datasets and tasks. Our framework demonstrates superior generalization in both supervised and zero-shot graph learning tasks, surpassing existing benchmarks. The open-sourced model implementation of our GraphGPT is available at https://github.com/HKUDS/GraphGPT.
5/8/2024

Large Generative Graph Models
Yu Wang, Ryan A. Rossi, Namyong Park, Huiyuan Chen, Nesreen K. Ahmed, Puja Trivedi, Franck Dernoncourt, Danai Koutra, Tyler Derr
0
0
Large Generative Models (LGMs) such as GPT, Stable Diffusion, Sora, and Suno are trained on a huge amount of language corpus, images, videos, and audio that are extremely diverse from numerous domains. This training paradigm over diverse well-curated data lies at the heart of generating creative and sensible content. However, all previous graph generative models (e.g., GraphRNN, MDVAE, MoFlow, GDSS, and DiGress) have been trained only on one dataset each time, which cannot replicate the revolutionary success achieved by LGMs in other fields. To remedy this crucial gap, we propose a new class of graph generative model called Large Graph Generative Model (LGGM) that is trained on a large corpus of graphs (over 5000 graphs) from 13 different domains. We empirically demonstrate that the pre-trained LGGM has superior zero-shot generative capability to existing graph generative models. Furthermore, our pre-trained LGGM can be easily fine-tuned with graphs from target domains and demonstrate even better performance than those directly trained from scratch, behaving as a solid starting point for real-world customization. Inspired by Stable Diffusion, we further equip LGGM with the capability to generate graphs given text prompts (Text-to-Graph), such as the description of the network name and domain (i.e., The power-1138-bus graph represents a network of buses in a power distribution system.), and network statistics (i.e., The graph has a low average degree, suitable for modeling social media interactions.). This Text-to-Graph capability integrates the extensive world knowledge in the underlying language model, offering users fine-grained control of the generated graphs. We release the code, the model checkpoint, and the datasets at https://lggm-lg.github.io/.
6/10/2024

HiGPT: Heterogeneous Graph Language Model
Jiabin Tang, Yuhao Yang, Wei Wei, Lei Shi, Long Xia, Dawei Yin, Chao Huang
0
0
Heterogeneous graph learning aims to capture complex relationships and diverse relational semantics among entities in a heterogeneous graph to obtain meaningful representations for nodes and edges. Recent advancements in heterogeneous graph neural networks (HGNNs) have achieved state-of-the-art performance by considering relation heterogeneity and using specialized message functions and aggregation rules. However, existing frameworks for heterogeneous graph learning have limitations in generalizing across diverse heterogeneous graph datasets. Most of these frameworks follow the pre-train and fine-tune paradigm on the same dataset, which restricts their capacity to adapt to new and unseen data. This raises the question: Can we generalize heterogeneous graph models to be well-adapted to diverse downstream learning tasks with distribution shifts in both node token sets and relation type heterogeneity?'' To tackle those challenges, we propose HiGPT, a general large graph model with Heterogeneous graph instruction-tuning paradigm. Our framework enables learning from arbitrary heterogeneous graphs without the need for any fine-tuning process from downstream datasets. To handle distribution shifts in heterogeneity, we introduce an in-context heterogeneous graph tokenizer that captures semantic relationships in different heterogeneous graphs, facilitating model adaptation. We incorporate a large corpus of heterogeneity-aware graph instructions into our HiGPT, enabling the model to effectively comprehend complex relation heterogeneity and distinguish between various types of graph tokens. Furthermore, we introduce the Mixture-of-Thought (MoT) instruction augmentation paradigm to mitigate data scarcity by generating diverse and informative instructions. Through comprehensive evaluations, our proposed framework demonstrates exceptional performance in terms of generalization performance.
5/21/2024
🔄
Key ingredients for effective zero-shot cross-lingual knowledge transfer in generative tasks
Nadezhda Chirkova, Vassilina Nikoulina
0
0
Zero-shot cross-lingual knowledge transfer enables a multilingual pretrained language model, finetuned on a task in one language, make predictions for this task in other languages. While being broadly studied for natural language understanding tasks, the described setting is understudied for generation. Previous works notice a frequent problem of generation in a wrong language and propose approaches to address it, usually using mT5 as a backbone model. In this work we compare various approaches proposed from the literature in unified settings, also including alternative backbone models, namely mBART and NLLB-200. We first underline the importance of tuning learning rate used for finetuning, which helps to substantially alleviate the problem of generation in the wrong language. Then, we show that with careful learning rate tuning, the simple full finetuning of the model acts as a very strong baseline and alternative approaches bring only marginal improvements. Finally, we find that mBART performs similarly to mT5 of the same size, and NLLB-200 can be competitive in some cases. Our final zero-shot models reach the performance of the approach based on data translation which is usually considered as an upper baseline for zero-shot cross-lingual transfer in generation.
4/23/2024