ZeroI2V: Zero-Cost Adaptation of Pre-trained Transformers from Image to Video

0
🖼️
Sign in to get full access
Overview
- This paper presents a new paradigm called "ZeroI2V" for efficiently adapting image models to video recognition tasks.
- The key ideas are:
- Using spatial-temporal dual-headed attention to give image transformers the ability to model temporal dynamics in videos without extra parameters or compute.
- A linear adaptation strategy that uses lightweight adapters to transfer frozen image models to videos, with the adapters merged back into the original model for zero extra cost during inference.
Plain English Explanation
The paper focuses on the challenge of taking image recognition models and adapting them to work well for video recognition tasks. Image-to-video adaptation is an efficient approach, as image models have a lot of parameters and can learn useful features that transfer to video. However, directly fine-tuning these models on video data can be inefficient and unnecessary.
To address this, the authors propose a new "ZeroI2V" paradigm. The core ideas are:
-
Capturing video dynamics: The model uses a special type of self-attention called "spatial-temporal dual-headed attention" to let the image transformer efficiently learn to model the temporal aspects of videos, without needing any extra parameters or compute.
-
Bridging the image-video gap: The model uses lightweight "linear adapters" that are trained to transfer the frozen image model to work well on video data. Importantly, these adapters can then be merged back into the original model, so there is zero extra cost during final inference.
By combining these two key ideas, the ZeroI2V model can match or outperform previous state-of-the-art methods for video recognition, while being much more efficient in terms of parameters and inference time.
Technical Explanation
The paper begins by noting the efficiency of adapting powerful image recognition models, like transformers, to video tasks through image-to-video adaptation. However, directly fine-tuning these models on video data can be wasteful.
To overcome this, the authors propose the "ZeroI2V" paradigm, with two key technical contributions:
-
Spatial-Temporal Dual-Headed Attention (STDHA): The core idea is to extend the self-attention mechanism of the image transformer to efficiently model temporal dynamics in videos. This is done by having two separate attention heads - one for spatial attention and one for temporal attention. This STDHA module can be added to the image transformer with zero extra parameters or computation.
-
Linear Adaptation: To bridge the domain gap between images and videos, the authors propose a lightweight "linear adapter" module. These adapters are densely placed and trained to transfer the frozen image model to work well on video data. Importantly, after training, these adapters can be structurally reparameterized and merged back into the original model, resulting in zero extra cost during final inference.
Experiments on various video recognition benchmarks show that ZeroI2V can match or exceed previous state-of-the-art methods, while being significantly more parameter and compute efficient.
Critical Analysis
The paper presents a clever and efficient approach to adapting powerful image models to video recognition tasks. The core ideas of STDHA and linear adaptation are well-motivated and show strong empirical results.
However, one potential limitation is that the approach may struggle to capture more complex temporal dynamics that require deeper reasoning about the video content. The authors acknowledge this, suggesting that the linear adapters may have limited expressivity for certain video tasks.
Additionally, while the zero-cost inference is a major advantage, the training process does involve some overhead with the adapter modules. It would be interesting to see how this compares to alternative approaches like object-centric image-to-video adaptation or instruction-guided diffusion model adaptation.
Overall, the ZeroI2V paradigm represents an important step forward in efficient video recognition, and the authors' insights around spatial-temporal attention and linear adaptation could inspire further research in this direction.
Conclusion
This paper introduces the ZeroI2V paradigm, a new approach for efficiently adapting powerful image recognition models to video tasks. The key ideas are using spatial-temporal attention to capture video dynamics, and lightweight linear adapters to bridge the image-video domain gap, all while maintaining zero extra cost during final inference.
The results show that ZeroI2V can match or outperform previous state-of-the-art video recognition methods, while being significantly more parameter and compute efficient. This work represents an important advance in the field of multimodal video transfer learning, opening up new possibilities for deploying high-performance video models in resource-constrained settings.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
0
ZeroI2V: Zero-Cost Adaptation of Pre-trained Transformers from Image to Video
Xinhao Li, Yuhan Zhu, Limin Wang
Adapting image models to the video domain has emerged as an efficient paradigm for solving video recognition tasks. Due to the huge number of parameters and effective transferability of image models, performing full fine-tuning is less efficient and even unnecessary. Thus, recent research is shifting its focus toward parameter-efficient image-to-video adaptation. However, these adaptation strategies inevitably introduce extra computational costs to deal with the domain gap and temporal modeling in videos. In this paper, we present a new adaptation paradigm (ZeroI2V) to transfer the image transformers to video recognition tasks (i.e., introduce zero extra cost to the original models during inference). To achieve this goal, we present two core designs. First, to capture the dynamics in videos and reduce the difficulty of image-to-video adaptation, we exploit the flexibility of self-attention and introduce spatial-temporal dual-headed attention (STDHA). This approach efficiently endows the image transformers with temporal modeling capability at zero extra parameters and computation. Second, to handle the domain gap between images and videos, we propose a linear adaption strategy that utilizes lightweight densely placed linear adapters to fully transfer the frozen image models to video recognition. Thanks to the customized linear design, all newly added adapters could be easily merged with the original modules through structural reparameterization after training, enabling zero extra cost during inference. Extensive experiments on representative fully-supervised and few-shot video recognition benchmarks showcase that ZeroI2V can match or even outperform previous state-of-the-art methods while enjoying superior parameter and inference efficiency.
Read more7/12/2024
0
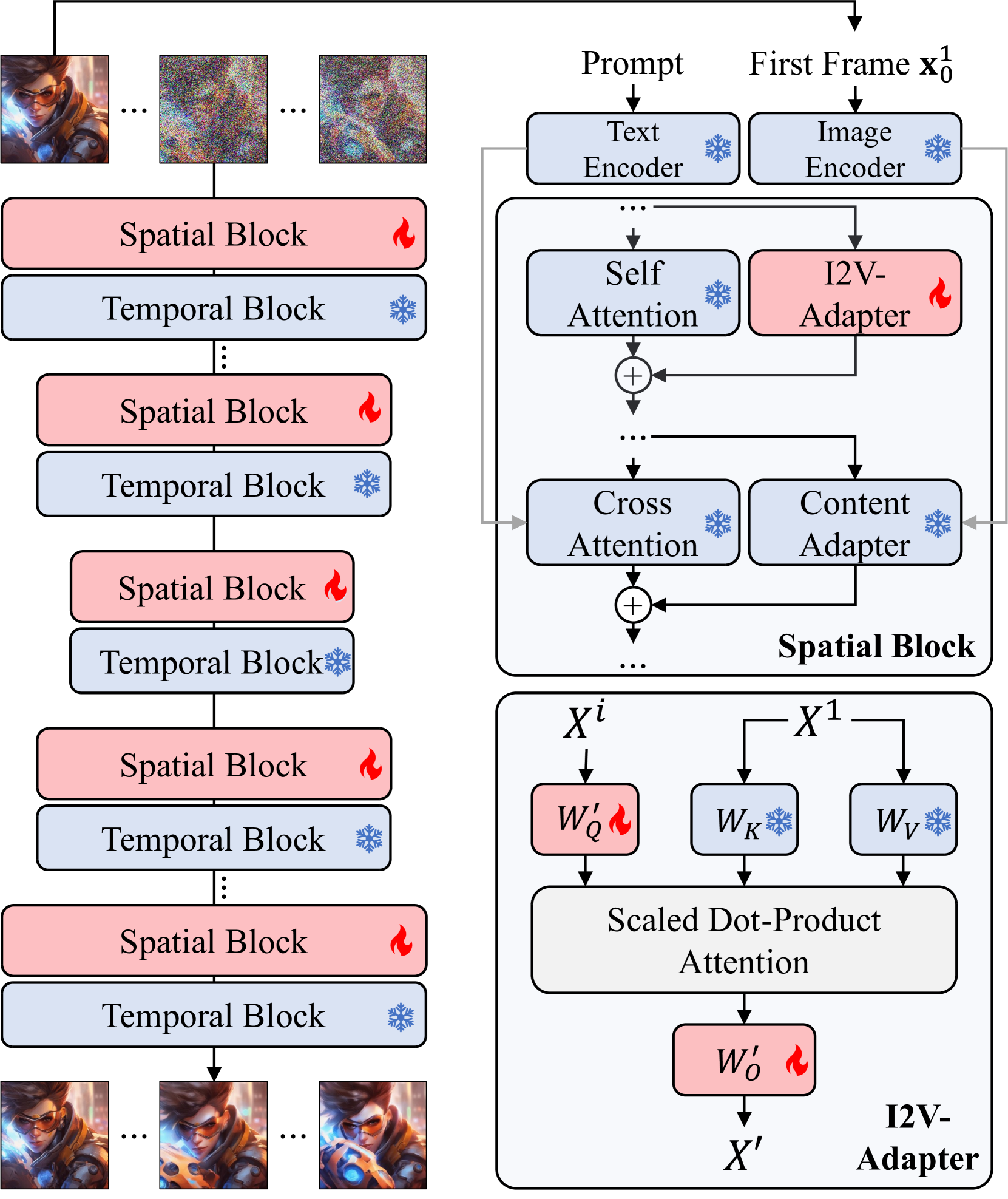
I2V-Adapter: A General Image-to-Video Adapter for Diffusion Models
Xun Guo, Mingwu Zheng, Liang Hou, Yuan Gao, Yufan Deng, Pengfei Wan, Di Zhang, Yufan Liu, Weiming Hu, Zhengjun Zha, Haibin Huang, Chongyang Ma
Text-guided image-to-video (I2V) generation aims to generate a coherent video that preserves the identity of the input image and semantically aligns with the input prompt. Existing methods typically augment pretrained text-to-video (T2V) models by either concatenating the image with noised video frames channel-wise before being fed into the model or injecting the image embedding produced by pretrained image encoders in cross-attention modules. However, the former approach often necessitates altering the fundamental weights of pretrained T2V models, thus restricting the model's compatibility within the open-source communities and disrupting the model's prior knowledge. Meanwhile, the latter typically fails to preserve the identity of the input image. We present I2V-Adapter to overcome such limitations. I2V-Adapter adeptly propagates the unnoised input image to subsequent noised frames through a cross-frame attention mechanism, maintaining the identity of the input image without any changes to the pretrained T2V model. Notably, I2V-Adapter only introduces a few trainable parameters, significantly alleviating the training cost and also ensures compatibility with existing community-driven personalized models and control tools. Moreover, we propose a novel Frame Similarity Prior to balance the motion amplitude and the stability of generated videos through two adjustable control coefficients. Our experimental results demonstrate that I2V-Adapter is capable of producing high-quality videos. This performance, coupled with its agility and adaptability, represents a substantial advancement in the field of I2V, particularly for personalized and controllable applications.
Read more6/28/2024
🖼️
0
TI2V-Zero: Zero-Shot Image Conditioning for Text-to-Video Diffusion Models
Haomiao Ni, Bernhard Egger, Suhas Lohit, Anoop Cherian, Ye Wang, Toshiaki Koike-Akino, Sharon X. Huang, Tim K. Marks
Text-conditioned image-to-video generation (TI2V) aims to synthesize a realistic video starting from a given image (e.g., a woman's photo) and a text description (e.g., a woman is drinking water.). Existing TI2V frameworks often require costly training on video-text datasets and specific model designs for text and image conditioning. In this paper, we propose TI2V-Zero, a zero-shot, tuning-free method that empowers a pretrained text-to-video (T2V) diffusion model to be conditioned on a provided image, enabling TI2V generation without any optimization, fine-tuning, or introducing external modules. Our approach leverages a pretrained T2V diffusion foundation model as the generative prior. To guide video generation with the additional image input, we propose a repeat-and-slide strategy that modulates the reverse denoising process, allowing the frozen diffusion model to synthesize a video frame-by-frame starting from the provided image. To ensure temporal continuity, we employ a DDPM inversion strategy to initialize Gaussian noise for each newly synthesized frame and a resampling technique to help preserve visual details. We conduct comprehensive experiments on both domain-specific and open-domain datasets, where TI2V-Zero consistently outperforms a recent open-domain TI2V model. Furthermore, we show that TI2V-Zero can seamlessly extend to other tasks such as video infilling and prediction when provided with more images. Its autoregressive design also supports long video generation.
Read more4/26/2024
0
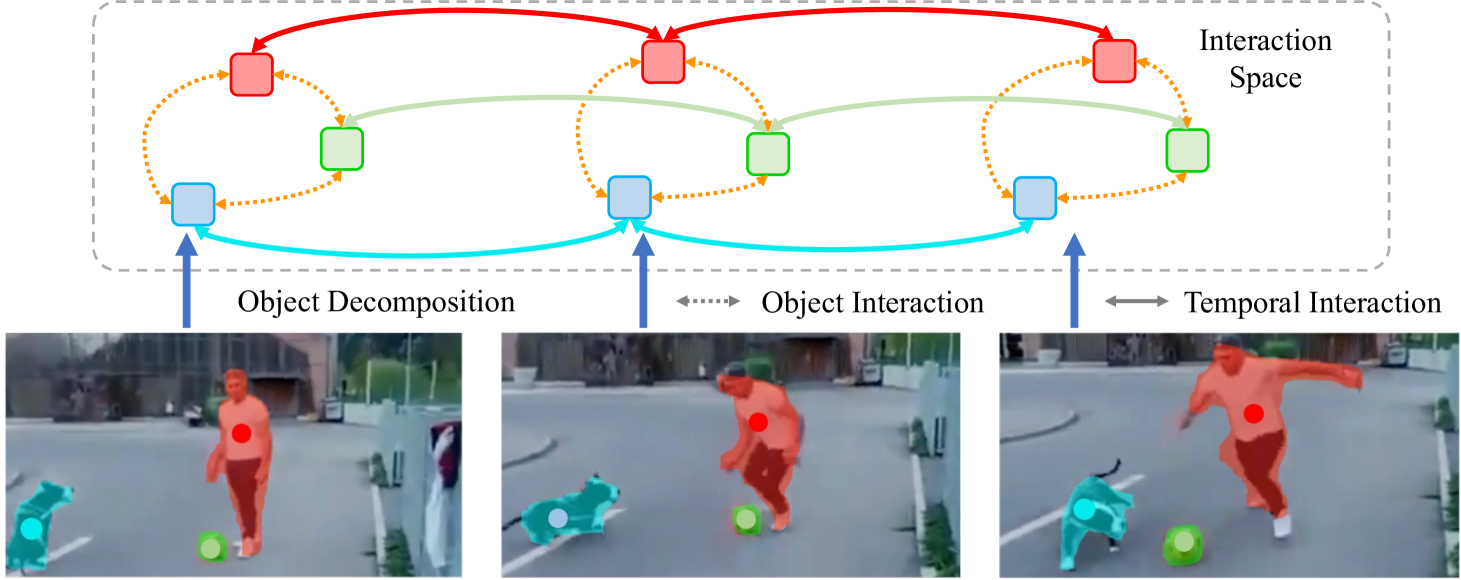
Rethinking Image-to-Video Adaptation: An Object-centric Perspective
Rui Qian, Shuangrui Ding, Dahua Lin
Image-to-video adaptation seeks to efficiently adapt image models for use in the video domain. Instead of finetuning the entire image backbone, many image-to-video adaptation paradigms use lightweight adapters for temporal modeling on top of the spatial module. However, these attempts are subject to limitations in efficiency and interpretability. In this paper, we propose a novel and efficient image-to-video adaptation strategy from the object-centric perspective. Inspired by human perception, which identifies objects as key components for video understanding, we integrate a proxy task of object discovery into image-to-video transfer learning. Specifically, we adopt slot attention with learnable queries to distill each frame into a compact set of object tokens. These object-centric tokens are then processed through object-time interaction layers to model object state changes across time. Integrated with two novel object-level losses, we demonstrate the feasibility of performing efficient temporal reasoning solely on the compressed object-centric representations for video downstream tasks. Our method achieves state-of-the-art performance with fewer tunable parameters, only 5% of fully finetuned models and 50% of efficient tuning methods, on action recognition benchmarks. In addition, our model performs favorably in zero-shot video object segmentation without further retraining or object annotations, proving the effectiveness of object-centric video understanding.
Read more7/10/2024