TI2V-Zero: Zero-Shot Image Conditioning for Text-to-Video Diffusion Models
2404.16306
0
1
🖼️
Abstract
Text-conditioned image-to-video generation (TI2V) aims to synthesize a realistic video starting from a given image (e.g., a woman's photo) and a text description (e.g., a woman is drinking water.). Existing TI2V frameworks often require costly training on video-text datasets and specific model designs for text and image conditioning. In this paper, we propose TI2V-Zero, a zero-shot, tuning-free method that empowers a pretrained text-to-video (T2V) diffusion model to be conditioned on a provided image, enabling TI2V generation without any optimization, fine-tuning, or introducing external modules. Our approach leverages a pretrained T2V diffusion foundation model as the generative prior. To guide video generation with the additional image input, we propose a repeat-and-slide strategy that modulates the reverse denoising process, allowing the frozen diffusion model to synthesize a video frame-by-frame starting from the provided image. To ensure temporal continuity, we employ a DDPM inversion strategy to initialize Gaussian noise for each newly synthesized frame and a resampling technique to help preserve visual details. We conduct comprehensive experiments on both domain-specific and open-domain datasets, where TI2V-Zero consistently outperforms a recent open-domain TI2V model. Furthermore, we show that TI2V-Zero can seamlessly extend to other tasks such as video infilling and prediction when provided with more images. Its autoregressive design also supports long video generation.
Create account to get full access
Overview
- This paper proposes a novel method called TI2V-Zero for text-conditioned image-to-video generation.
- TI2V-Zero leverages a pre-trained text-to-video (T2V) diffusion model as a generative foundation, allowing it to generate videos from an image and text description without any additional training or fine-tuning.
- The key innovations include a "repeat-and-slide" strategy to condition the diffusion model on the input image, and techniques to ensure temporal continuity and preserve visual details in the generated videos.
Plain English Explanation
TI2V-Zero is a new way to create videos from a single image and a text description. Rather than training a complex model from scratch, TI2V-Zero uses an existing text-to-video model as a starting point. This allows it to generate videos without any additional training or fine-tuning.
The core idea is to "guide" the pre-trained text-to-video model using the input image. The researchers developed a "repeat-and-slide" strategy that modifies how the model generates each video frame, allowing it to start from the provided image and then continue the video generation. To make the video look smooth and consistent, they also use techniques to initialize each new frame and preserve important visual details.
By leveraging an existing model, TI2V-Zero can generate videos from image-text pairs without the need for costly training on video datasets or complex model architectures. This makes it a more practical and accessible approach compared to previous text-conditioned image-to-video generation methods.
Technical Explanation
The key technical contributions of TI2V-Zero are:
-
Leveraging a Pre-trained T2V Diffusion Model: The researchers use a pre-trained text-to-video diffusion model as the generative foundation for their TI2V framework. This allows them to generate videos without the need for costly training on video-text datasets.
-
Repeat-and-Slide Strategy: To condition the pre-trained diffusion model on the input image, the researchers propose a "repeat-and-slide" strategy. This modulates the reverse denoising process of the diffusion model, enabling it to synthesize video frames frame-by-frame starting from the provided image.
-
Ensuring Temporal Continuity: To maintain temporal continuity in the generated videos, the researchers employ a DDPM inversion strategy to initialize the Gaussian noise for each newly synthesized frame. They also use a resampling technique to help preserve important visual details.
The researchers demonstrate the effectiveness of TI2V-Zero on both domain-specific and open-domain datasets, showing that it outperforms a recent open-domain TI2V model. They also showcase TI2V-Zero's versatility by extending it to other tasks like video infilling and prediction when provided with additional input images.
Critical Analysis
The researchers acknowledge several limitations of their approach:
- TI2V-Zero's performance is still dependent on the quality of the pre-trained T2V diffusion model, which may not always be readily available.
- The method relies on the input image and text being well-aligned, and its performance may degrade if the provided information is not coherent.
- The generated videos can sometimes exhibit minor visual artifacts or inconsistencies, which the researchers attribute to the challenges of preserving detailed visual information in a generative process.
Additionally, while TI2V-Zero represents a significant advancement in text-conditioned image-to-video generation, there may be opportunities for further improvements, such as exploring more advanced conditioning strategies or incorporating additional techniques to enhance the temporal and visual quality of the generated videos.
Conclusion
In summary, the TI2V-Zero method provides a compelling zero-shot approach to text-conditioned image-to-video generation by leveraging a pre-trained text-to-video diffusion model. This innovative approach eliminates the need for costly training on video-text datasets and complex model designs, making it a more accessible and practical solution compared to previous methods. The researchers' contributions in the areas of image conditioning, temporal continuity, and visual detail preservation demonstrate the potential of TI2V-Zero to unlock new possibilities in generative video synthesis from text and image inputs.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Slicedit: Zero-Shot Video Editing With Text-to-Image Diffusion Models Using Spatio-Temporal Slices
Nathaniel Cohen, Vladimir Kulikov, Matan Kleiner, Inbar Huberman-Spiegelglas, Tomer Michaeli
0
0
Text-to-image (T2I) diffusion models achieve state-of-the-art results in image synthesis and editing. However, leveraging such pretrained models for video editing is considered a major challenge. Many existing works attempt to enforce temporal consistency in the edited video through explicit correspondence mechanisms, either in pixel space or between deep features. These methods, however, struggle with strong nonrigid motion. In this paper, we introduce a fundamentally different approach, which is based on the observation that spatiotemporal slices of natural videos exhibit similar characteristics to natural images. Thus, the same T2I diffusion model that is normally used only as a prior on video frames, can also serve as a strong prior for enhancing temporal consistency by applying it on spatiotemporal slices. Based on this observation, we present Slicedit, a method for text-based video editing that utilizes a pretrained T2I diffusion model to process both spatial and spatiotemporal slices. Our method generates videos that retain the structure and motion of the original video while adhering to the target text. Through extensive experiments, we demonstrate Slicedit's ability to edit a wide range of real-world videos, confirming its clear advantages compared to existing competing methods. Webpage: https://matankleiner.github.io/slicedit/
5/21/2024
🛸
ConditionVideo: Training-Free Condition-Guided Text-to-Video Generation
Bo Peng, Xinyuan Chen, Yaohui Wang, Chaochao Lu, Yu Qiao
0
0
Recent works have successfully extended large-scale text-to-image models to the video domain, producing promising results but at a high computational cost and requiring a large amount of video data. In this work, we introduce ConditionVideo, a training-free approach to text-to-video generation based on the provided condition, video, and input text, by leveraging the power of off-the-shelf text-to-image generation methods (e.g., Stable Diffusion). ConditionVideo generates realistic dynamic videos from random noise or given scene videos. Our method explicitly disentangles the motion representation into condition-guided and scenery motion components. To this end, the ConditionVideo model is designed with a UNet branch and a control branch. To improve temporal coherence, we introduce sparse bi-directional spatial-temporal attention (sBiST-Attn). The 3D control network extends the conventional 2D controlnet model, aiming to strengthen conditional generation accuracy by additionally leveraging the bi-directional frames in the temporal domain. Our method exhibits superior performance in terms of frame consistency, clip score, and conditional accuracy, outperforming other compared methods.
5/24/2024
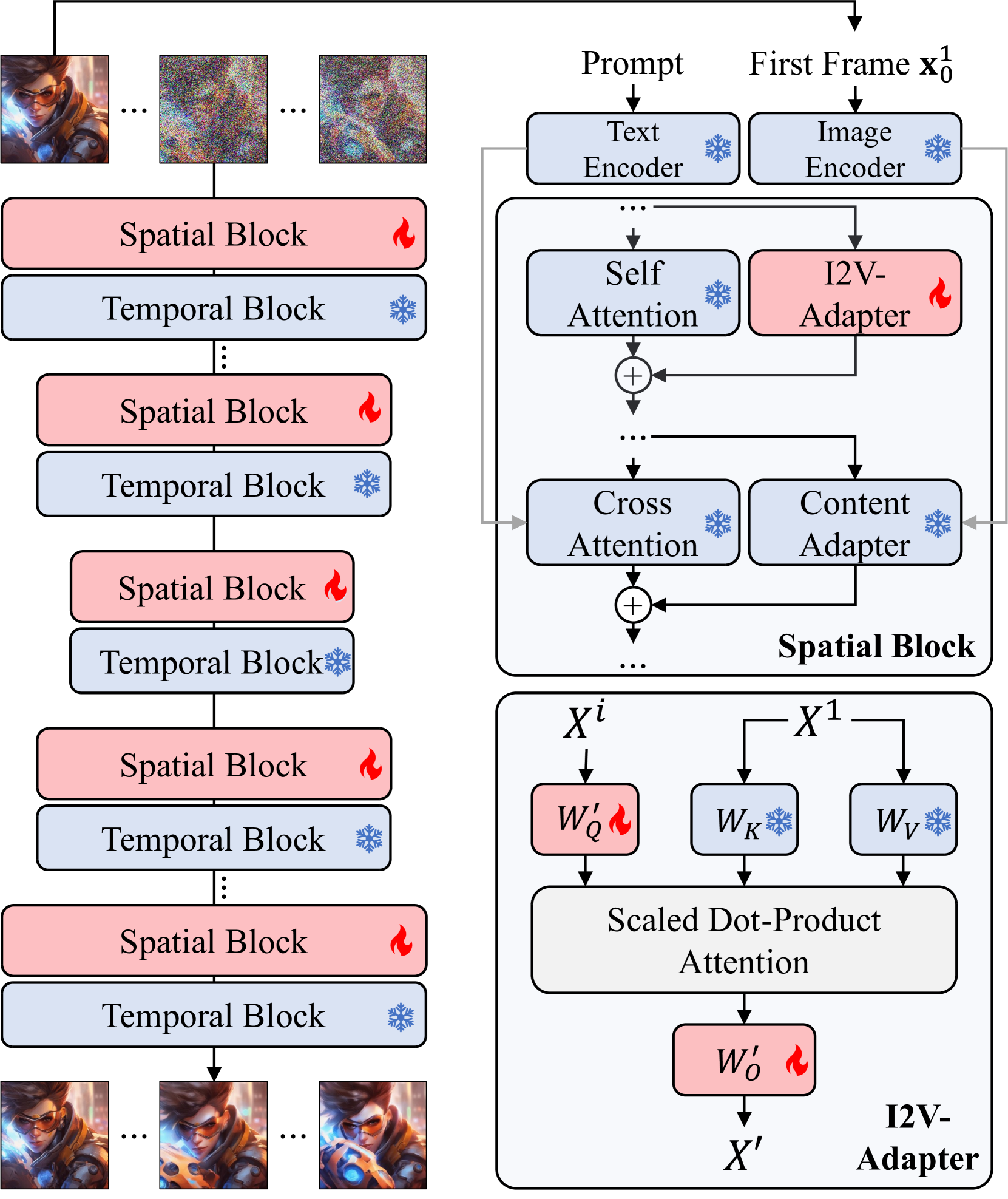
I2V-Adapter: A General Image-to-Video Adapter for Diffusion Models
Xun Guo, Mingwu Zheng, Liang Hou, Yuan Gao, Yufan Deng, Pengfei Wan, Di Zhang, Yufan Liu, Weiming Hu, Zhengjun Zha, Haibin Huang, Chongyang Ma
0
0
Text-guided image-to-video (I2V) generation aims to generate a coherent video that preserves the identity of the input image and semantically aligns with the input prompt. Existing methods typically augment pretrained text-to-video (T2V) models by either concatenating the image with noised video frames channel-wise before being fed into the model or injecting the image embedding produced by pretrained image encoders in cross-attention modules. However, the former approach often necessitates altering the fundamental weights of pretrained T2V models, thus restricting the model's compatibility within the open-source communities and disrupting the model's prior knowledge. Meanwhile, the latter typically fails to preserve the identity of the input image. We present I2V-Adapter to overcome such limitations. I2V-Adapter adeptly propagates the unnoised input image to subsequent noised frames through a cross-frame attention mechanism, maintaining the identity of the input image without any changes to the pretrained T2V model. Notably, I2V-Adapter only introduces a few trainable parameters, significantly alleviating the training cost and also ensures compatibility with existing community-driven personalized models and control tools. Moreover, we propose a novel Frame Similarity Prior to balance the motion amplitude and the stability of generated videos through two adjustable control coefficients. Our experimental results demonstrate that I2V-Adapter is capable of producing high-quality videos. This performance, coupled with its agility and adaptability, represents a substantial advancement in the field of I2V, particularly for personalized and controllable applications.
6/28/2024

Vivid-ZOO: Multi-View Video Generation with Diffusion Model
Bing Li, Cheng Zheng, Wenxuan Zhu, Jinjie Mai, Biao Zhang, Peter Wonka, Bernard Ghanem
0
0
While diffusion models have shown impressive performance in 2D image/video generation, diffusion-based Text-to-Multi-view-Video (T2MVid) generation remains underexplored. The new challenges posed by T2MVid generation lie in the lack of massive captioned multi-view videos and the complexity of modeling such multi-dimensional distribution. To this end, we propose a novel diffusion-based pipeline that generates high-quality multi-view videos centered around a dynamic 3D object from text. Specifically, we factor the T2MVid problem into viewpoint-space and time components. Such factorization allows us to combine and reuse layers of advanced pre-trained multi-view image and 2D video diffusion models to ensure multi-view consistency as well as temporal coherence for the generated multi-view videos, largely reducing the training cost. We further introduce alignment modules to align the latent spaces of layers from the pre-trained multi-view and the 2D video diffusion models, addressing the reused layers' incompatibility that arises from the domain gap between 2D and multi-view data. In support of this and future research, we further contribute a captioned multi-view video dataset. Experimental results demonstrate that our method generates high-quality multi-view videos, exhibiting vivid motions, temporal coherence, and multi-view consistency, given a variety of text prompts.
6/14/2024