ZeroMamba: Exploring Visual State Space Model for Zero-Shot Learning

0

Sign in to get full access
Overview
- Explores a novel Visual State Space Model (VSSM) called "ZeroMamba" for zero-shot learning
- Aims to learn a shared representation between visual features and semantic attributes
- Leverages state space modeling to capture complex visual-semantic relationships
- Introduces a novel regularization technique to improve model generalization
- Demonstrates state-of-the-art performance on several zero-shot learning benchmarks
Plain English Explanation
The research paper introduces a new approach called "ZeroMamba" that uses [object Object] to tackle the challenge of [object Object]. Zero-shot learning is the ability to recognize and classify objects that the model has never seen before during training.
The key idea behind ZeroMamba is to learn a shared representation that can capture the complex relationships between visual features (what an object looks like) and semantic attributes (what properties or characteristics define the object). This is done using a [object Object], which is a mathematical framework that can model dynamic systems and their evolution over time.
By modeling the visual-semantic relationships in this way, ZeroMamba is able to generalize and recognize new objects that it hasn't seen before, but which share semantic similarities with objects it has been trained on. The researchers also introduce a novel regularization technique to improve the model's ability to generalize.
The paper demonstrates that ZeroMamba achieves state-of-the-art performance on several standard zero-shot learning benchmarks, outperforming other approaches. This suggests that the Visual State Space Modeling framework is a promising direction for advancing zero-shot learning capabilities.
Technical Explanation
The [object Object] model proposed in this paper is based on the [object Object] framework, which aims to learn a shared representation between visual features and semantic attributes.
The core idea is to model the complex relationships between visual inputs and semantic information using a state space model. Specifically, ZeroMamba consists of:
- Visual Encoder: An encoder network that maps visual inputs (e.g., images) to a latent visual representation.
- Semantic Encoder: An encoder network that maps semantic attributes (e.g., class labels) to a latent semantic representation.
- State Space Model: A state space model that learns to capture the dynamic relationships between the visual and semantic latent representations.
During training, the model is optimized to minimize the reconstruction error between the original visual and semantic inputs and their reconstructions from the learned state space representation.
Additionally, the authors introduce a novel Semantic Regularization technique, which encourages the visual encoder to learn representations that are more semantically meaningful and aligned with the semantic attributes.
The paper evaluates ZeroMamba on several standard zero-shot learning benchmarks, including [object Object], [object Object], and [object Object]. The results demonstrate that ZeroMamba outperforms state-of-the-art methods, highlighting the effectiveness of the Visual State Space Modeling approach for zero-shot learning.
Critical Analysis
The paper presents a compelling approach to zero-shot learning by leveraging the Visual State Space Modeling framework. The key strengths of the ZeroMamba model include:
-
Principled Modeling of Visual-Semantic Relationships: The state space model provides a principled way to capture the complex and dynamic relationships between visual features and semantic attributes, which is crucial for zero-shot generalization.
-
Semantic Regularization: The novel regularization technique helps to align the visual representations with the semantic information, further improving the model's ability to generalize to unseen classes.
However, the paper also acknowledges some limitations and potential areas for future research:
-
Computational Complexity: The state space model can be computationally expensive, especially as the number of classes and attributes increases. Exploring ways to improve the efficiency of the model is an important future direction.
-
Interpretability: The state space model can be challenging to interpret, as the learned representations and dynamics may not be easily explainable. Developing methods to improve the interpretability of the model could be valuable.
-
Generalization to Other Domains: While the paper demonstrates strong performance on standard zero-shot learning benchmarks, it would be interesting to see how the ZeroMamba model would perform on other types of zero-shot learning tasks, such as in natural language processing or robotics.
Overall, the ZeroMamba model represents an exciting advancement in the field of zero-shot learning, and the Visual State Space Modeling approach holds promise for further developments in this area.
Conclusion
The ZeroMamba paper introduces a novel Visual State Space Model for zero-shot learning, which aims to learn a shared representation between visual features and semantic attributes. By leveraging the state space modeling framework, the model is able to capture the complex relationships between visual and semantic information, enabling it to generalize to unseen classes.
The key contributions of this work include the ZeroMamba architecture, the Semantic Regularization technique, and the state-of-the-art performance on several zero-shot learning benchmarks. While the model has some computational and interpretability challenges, the overall approach represents an exciting advance in the field of zero-shot learning and suggests that further developments in Visual State Space Modeling could lead to significant improvements in the ability of AI systems to recognize and classify novel objects and concepts.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ZeroMamba: Exploring Visual State Space Model for Zero-Shot Learning
Wenjin Hou, Dingjie Fu, Kun Li, Shiming Chen, Hehe Fan, Yi Yang
Zero-shot learning (ZSL) aims to recognize unseen classes by transferring semantic knowledge from seen classes to unseen ones, guided by semantic information. To this end, existing works have demonstrated remarkable performance by utilizing global visual features from Convolutional Neural Networks (CNNs) or Vision Transformers (ViTs) for visual-semantic interactions. Due to the limited receptive fields of CNNs and the quadratic complexity of ViTs, however, these visual backbones achieve suboptimal visual-semantic interactions. In this paper, motivated by the visual state space model (i.e., Vision Mamba), which is capable of capturing long-range dependencies and modeling complex visual dynamics, we propose a parameter-efficient ZSL framework called ZeroMamba to advance ZSL. Our ZeroMamba comprises three key components: Semantic-aware Local Projection (SLP), Global Representation Learning (GRL), and Semantic Fusion (SeF). Specifically, SLP integrates semantic embeddings to map visual features to local semantic-related representations, while GRL encourages the model to learn global semantic representations. SeF combines these two semantic representations to enhance the discriminability of semantic features. We incorporate these designs into Vision Mamba, forming an end-to-end ZSL framework. As a result, the learned semantic representations are better suited for classification. Through extensive experiments on four prominent ZSL benchmarks, ZeroMamba demonstrates superior performance, significantly outperforming the state-of-the-art (i.e., CNN-based and ViT-based) methods under both conventional ZSL (CZSL) and generalized ZSL (GZSL) settings. Code is available at: https://anonymous.4open.science/r/ZeroMamba.
Read more8/28/2024

0
Progressive Semantic-Guided Vision Transformer for Zero-Shot Learning
Shiming Chen, Wenjin Hou, Salman Khan, Fahad Shahbaz Khan
Zero-shot learning (ZSL) recognizes the unseen classes by conducting visual-semantic interactions to transfer semantic knowledge from seen classes to unseen ones, supported by semantic information (e.g., attributes). However, existing ZSL methods simply extract visual features using a pre-trained network backbone (i.e., CNN or ViT), which fail to learn matched visual-semantic correspondences for representing semantic-related visual features as lacking of the guidance of semantic information, resulting in undesirable visual-semantic interactions. To tackle this issue, we propose a progressive semantic-guided vision transformer for zero-shot learning (dubbed ZSLViT). ZSLViT mainly considers two properties in the whole network: i) discover the semantic-related visual representations explicitly, and ii) discard the semantic-unrelated visual information. Specifically, we first introduce semantic-embedded token learning to improve the visual-semantic correspondences via semantic enhancement and discover the semantic-related visual tokens explicitly with semantic-guided token attention. Then, we fuse low semantic-visual correspondence visual tokens to discard the semantic-unrelated visual information for visual enhancement. These two operations are integrated into various encoders to progressively learn semantic-related visual representations for accurate visual-semantic interactions in ZSL. The extensive experiments show that our ZSLViT achieves significant performance gains on three popular benchmark datasets, i.e., CUB, SUN, and AWA2. Codes are available at: https://github.com/shiming-chen/ZSLViT .
Read more7/23/2024

0
Epsilon: Exploring Comprehensive Visual-Semantic Projection for Multi-Label Zero-Shot Learning
Ziming Liu, Jingcai Guo, Song Guo, Xiaocheng Lu
This paper investigates a challenging problem of zero-shot learning in the multi-label scenario (MLZSL), wherein the model is trained to recognize multiple unseen classes within a sample (e.g., an image) based on seen classes and auxiliary knowledge, e.g., semantic information. Existing methods usually resort to analyzing the relationship of various seen classes residing in a sample from the dimension of spatial or semantic characteristics and transferring the learned model to unseen ones. However, they neglect the integrity of local and global features. Although the use of the attention structure will accurately locate local features, especially objects, it will significantly lose its integrity, and the relationship between classes will also be affected. Rough processing of global features will also directly affect comprehensiveness. This neglect will make the model lose its grasp of the main components of the image. Relying only on the local existence of seen classes during the inference stage introduces unavoidable bias. In this paper, we propose a novel and comprehensive visual-semantic framework for MLZSL, dubbed Epsilon, to fully make use of such properties and enable a more accurate and robust visual-semantic projection. In terms of spatial information, we achieve effective refinement by group aggregating image features into several semantic prompts. It can aggregate semantic information rather than class information, preserving the correlation between semantics. In terms of global semantics, we use global forward propagation to collect as much information as possible to ensure that semantics are not omitted. Experiments on large-scale MLZSL benchmark datasets NUS-Wide and Open-Images-v4 demonstrate that the proposed Epsilon outperforms other state-of-the-art methods with large margins.
Read more8/27/2024
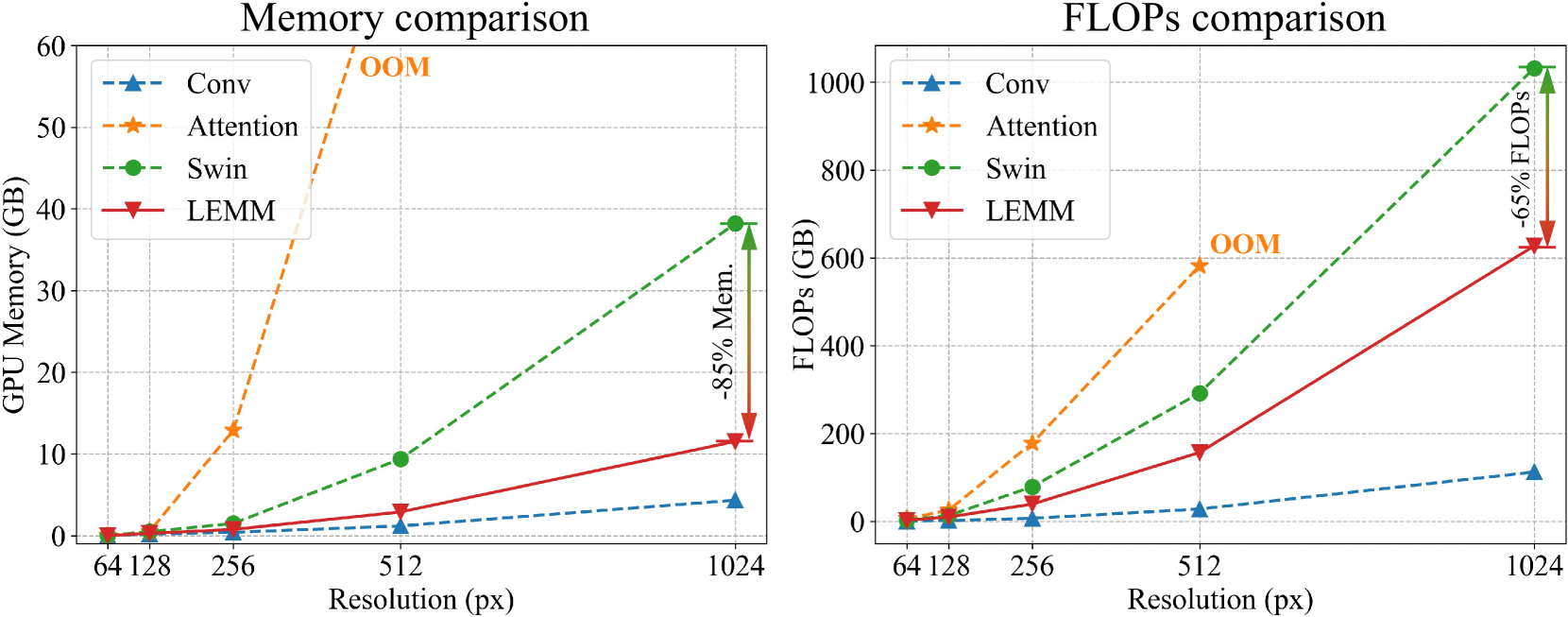
0
A Novel State Space Model with Local Enhancement and State Sharing for Image Fusion
Zihan Cao, Xiao Wu, Liang-Jian Deng, Yu Zhong
In image fusion tasks, images from different sources possess distinct characteristics. This has driven the development of numerous methods to explore better ways of fusing them while preserving their respective characteristics.Mamba, as a state space model, has emerged in the field of natural language processing. Recently, many studies have attempted to extend Mamba to vision tasks. However, due to the nature of images different from causal language sequences, the limited state capacity of Mamba weakens its ability to model image information. Additionally, the sequence modeling ability of Mamba is only capable of spatial information and cannot effectively capture the rich spectral information in images. Motivated by these challenges, we customize and improve the vision Mamba network designed for the image fusion task. Specifically, we propose the local-enhanced vision Mamba block, dubbed as LEVM. The LEVM block can improve local information perception of the network and simultaneously learn local and global spatial information. Furthermore, we propose the state sharing technique to enhance spatial details and integrate spatial and spectral information. Finally, the overall network is a multi-scale structure based on vision Mamba, called LE-Mamba. Extensive experiments show the proposed methods achieve state-of-the-art results on multispectral pansharpening and multispectral and hyperspectral image fusion datasets, and demonstrate the effectiveness of the proposed approach. Codes can be accessed at url{https://github.com/294coder/Efficient-MIF}.
Read more8/22/2024