ZigZag: Universal Sampling-free Uncertainty Estimation Through Two-Step Inference
2211.11435
2
0
🤯
Abstract
Whereas the ability of deep networks to produce useful predictions has been amply demonstrated, estimating the reliability of these predictions remains challenging. Sampling approaches such as MC-Dropout and Deep Ensembles have emerged as the most popular ones for this purpose. Unfortunately, they require many forward passes at inference time, which slows them down. Sampling-free approaches can be faster but suffer from other drawbacks, such as lower reliability of uncertainty estimates, difficulty of use, and limited applicability to different types of tasks and data. In this work, we introduce a sampling-free approach that is generic and easy to deploy, while producing reliable uncertainty estimates on par with state-of-the-art methods at a significantly lower computational cost. It is predicated on training the network to produce the same output with and without additional information about it. At inference time, when no prior information is given, we use the network's own prediction as the additional information. We then take the distance between the predictions with and without prior information as our uncertainty measure. We demonstrate our approach on several classification and regression tasks. We show that it delivers results on par with those of Ensembles but at a much lower computational cost.
Create account to get full access
Overview
- Deep neural networks can make useful predictions, but estimating the reliability of these predictions is challenging
- Existing approaches like MC-Dropout and Deep Ensembles are popular, but require multiple forward passes at inference time, slowing them down
- Sampling-free approaches can be faster, but suffer from lower reliability of uncertainty estimates, difficulty of use, and limited applicability
Plain English Explanation
Deep neural networks have proven to be very good at making predictions, but it can be challenging to determine how reliable those predictions are. Existing methods like MC-Dropout and Deep Ensembles are popular ways to estimate the uncertainty of a neural network's predictions, but they require running the network multiple times during inference, which can slow things down.
Other approaches that don't require multiple samples can be faster, but they tend to produce less reliable estimates of the uncertainty, can be difficult to use, and may not work well for different types of tasks or data. In this paper, the researchers introduce a new sampling-free approach that is generally applicable, easy to use, and can produce uncertainty estimates that are just as reliable as the state-of-the-art methods, but at a much lower computational cost.
The key idea is to train the network to produce the same output whether or not it is given additional information about the input. At inference time, when no extra information is provided, the network uses its own prediction as the "additional information." The difference between the network's output with and without this self-imposed additional information is used as the measure of uncertainty.
Technical Explanation
The researchers propose a sampling-free approach for estimating the uncertainty of a neural network's predictions. Their method is based on the idea of training the network to produce the same output with and without additional information about the input.
During training, the network is presented with the input and some additional information about it (e.g., a corrupted version of the input, or some other auxiliary data). The network is trained to produce the same output regardless of whether this additional information is provided or not.
At inference time, when no prior information is available, the network uses its own prediction as the "additional information." The difference between the network's output with and without this self-imposed additional information is then used as the measure of uncertainty.
The researchers demonstrate their approach on several classification and regression tasks, and show that it delivers results on par with those of Deep Ensembles but at a much lower computational cost.
Critical Analysis
The researchers present a novel and promising approach for estimating the uncertainty of neural network predictions. Compared to existing methods like MC-Dropout and Deep Ensembles, their sampling-free method is more computationally efficient, while still producing reliable uncertainty estimates.
However, the paper does not discuss the potential limitations of this approach. For example, it's unclear how well the method would perform on more complex tasks or datasets, or how sensitive it is to the choice of hyperparameters. Additionally, the researchers do not compare their approach to other sampling-free techniques, such as those based on Bayesian neural networks or information theory.
Further research is needed to better understand the strengths and weaknesses of this method, and to explore how it might be extended or combined with other techniques to improve the reliability and versatility of uncertainty estimation in deep learning.
Conclusion
The researchers have presented a novel and efficient approach for estimating the uncertainty of neural network predictions. By training the network to produce the same output with and without additional information, they are able to obtain reliable uncertainty estimates at a much lower computational cost than existing methods like MC-Dropout and Deep Ensembles.
This work has the potential to significantly improve the practical deployment of deep learning models, especially in applications where computational efficiency and uncertainty quantification are critical, such as edge AI and active learning. Further research is needed to fully explore the strengths and limitations of this approach, but it represents an important step forward in the field of reliable and efficient deep learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🎲
Efficient Bayesian Uncertainty Estimation for nnU-Net
Yidong Zhao, Changchun Yang, Artur Schweidtmann, Qian Tao
0
0
The self-configuring nnU-Net has achieved leading performance in a large range of medical image segmentation challenges. It is widely considered as the model of choice and a strong baseline for medical image segmentation. However, despite its extraordinary performance, nnU-Net does not supply a measure of uncertainty to indicate its possible failure. This can be problematic for large-scale image segmentation applications, where data are heterogeneous and nnU-Net may fail without notice. In this work, we introduce a novel method to estimate nnU-Net uncertainty for medical image segmentation. We propose a highly effective scheme for posterior sampling of weight space for Bayesian uncertainty estimation. Different from previous baseline methods such as Monte Carlo Dropout and mean-field Bayesian Neural Networks, our proposed method does not require a variational architecture and keeps the original nnU-Net architecture intact, thereby preserving its excellent performance and ease of use. Additionally, we boost the segmentation performance over the original nnU-Net via marginalizing multi-modal posterior models. We applied our method on the public ACDC and M&M datasets of cardiac MRI and demonstrated improved uncertainty estimation over a range of baseline methods. The proposed method further strengthens nnU-Net for medical image segmentation in terms of both segmentation accuracy and quality control.
5/2/2024
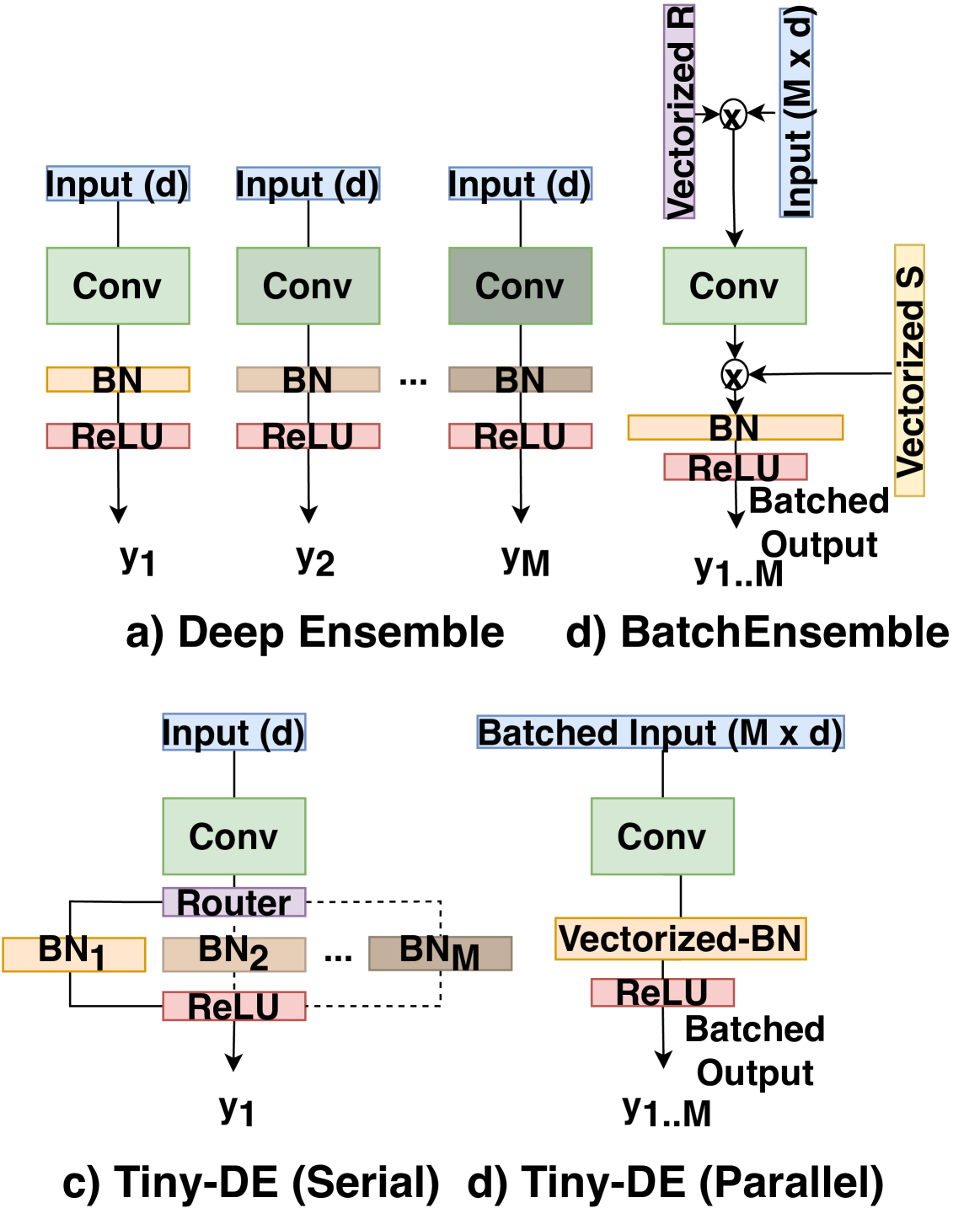
Tiny Deep Ensemble: Uncertainty Estimation in Edge AI Accelerators via Ensembling Normalization Layers with Shared Weights
Soyed Tuhin Ahmed, Michael Hefenbrock, Mehdi B. Tahoori
0
0
The applications of artificial intelligence (AI) are rapidly evolving, and they are also commonly used in safety-critical domains, such as autonomous driving and medical diagnosis, where functional safety is paramount. In AI-driven systems, uncertainty estimation allows the user to avoid overconfidence predictions and achieve functional safety. Therefore, the robustness and reliability of model predictions can be improved. However, conventional uncertainty estimation methods, such as the deep ensemble method, impose high computation and, accordingly, hardware (latency and energy) overhead because they require the storage and processing of multiple models. Alternatively, Monte Carlo dropout (MC-dropout) methods, although having low memory overhead, necessitate numerous ($sim 100$) forward passes, leading to high computational overhead and latency. Thus, these approaches are not suitable for battery-powered edge devices with limited computing and memory resources. In this paper, we propose the Tiny-Deep Ensemble approach, a low-cost approach for uncertainty estimation on edge devices. In our approach, only normalization layers are ensembled $M$ times, with all ensemble members sharing common weights and biases, leading to a significant decrease in storage requirements and latency. Moreover, our approach requires only one forward pass in a hardware architecture that allows batch processing for inference and uncertainty estimation. Furthermore, it has approximately the same memory overhead compared to a single model. Therefore, latency and memory overhead are reduced by a factor of up to $sim Mtimes$. Nevertheless, our method does not compromise accuracy, with an increase in inference accuracy of up to $sim 1%$ and a reduction in RMSE of $17.17%$ in various benchmark datasets, tasks, and state-of-the-art architectures.
5/10/2024

Graph Mining under Data scarcity
Appan Rakaraddi, Lam Siew-Kei, Mahardhika Pratama, Marcus de Carvalho
0
0
Multitude of deep learning models have been proposed for node classification in graphs. However, they tend to perform poorly under labeled-data scarcity. Although Few-shot learning for graphs has been introduced to overcome this problem, the existing models are not easily adaptable for generic graph learning frameworks like Graph Neural Networks (GNNs). Our work proposes an Uncertainty Estimator framework that can be applied on top of any generic GNN backbone network (which are typically designed for supervised/semi-supervised node classification) to improve the node classification performance. A neural network is used to model the Uncertainty Estimator as a probability distribution rather than probabilistic discrete scalar values. We train these models under the classic episodic learning paradigm in the $n$-way, $k$-shot fashion, in an end-to-end setting. Our work demonstrates that implementation of the uncertainty estimator on a GNN backbone network improves the classification accuracy under Few-shot setting without any meta-learning specific architecture. We conduct experiments on multiple datasets under different Few-shot settings and different GNN-based backbone networks. Our method outperforms the baselines, which demonstrates the efficacy of the Uncertainty Estimator for Few-shot node classification on graphs with a GNN.
6/12/2024
🤯
Scalable Subsampling Inference for Deep Neural Networks
Kejin Wu, Dimitris N. Politis
0
0
Deep neural networks (DNN) has received increasing attention in machine learning applications in the last several years. Recently, a non-asymptotic error bound has been developed to measure the performance of the fully connected DNN estimator with ReLU activation functions for estimating regression models. The paper at hand gives a small improvement on the current error bound based on the latest results on the approximation ability of DNN. More importantly, however, a non-random subsampling technique--scalable subsampling--is applied to construct a `subagged' DNN estimator. Under regularity conditions, it is shown that the subagged DNN estimator is computationally efficient without sacrificing accuracy for either estimation or prediction tasks. Beyond point estimation/prediction, we propose different approaches to build confidence and prediction intervals based on the subagged DNN estimator. In addition to being asymptotically valid, the proposed confidence/prediction intervals appear to work well in finite samples. All in all, the scalable subsampling DNN estimator offers the complete package in terms of statistical inference, i.e., (a) computational efficiency; (b) point estimation/prediction accuracy; and (c) allowing for the construction of practically useful confidence and prediction intervals.
5/15/2024