parler-tts
Maintainer: cjwbw

4.2K

| Property | Value |
|---|---|
| Run this model | Run on Replicate |
| API spec | View on Replicate |
| Github link | View on Github |
| Paper link | No paper link provided |
Create account to get full access
Model overview
parler-tts is a lightweight text-to-speech (TTS) model developed by cjwbw, a creator at Replicate. It is trained on 10.5K hours of audio data and can generate high-quality, natural-sounding speech with controllable features like gender, background noise, speaking rate, pitch, and reverberation. parler-tts is related to models like voicecraft, whisper, and sabuhi-model, which also focus on speech-related tasks. Additionally, the parler_tts_mini_v0.1 model provides a lightweight version of the parler-tts system.
Model inputs and outputs
The parler-tts model takes two main inputs: a text prompt and a text description. The prompt is the text to be converted into speech, while the description provides additional details to control the characteristics of the generated audio, such as the speaker's gender, pitch, speaking rate, and environmental factors.
Inputs
- Prompt: The text to be converted into speech.
- Description: A text description that provides details about the desired characteristics of the generated audio, such as the speaker's gender, pitch, speaking rate, and environmental factors.
Outputs
- Audio: The generated audio file in WAV format, which can be played back or further processed as needed.
Capabilities
The parler-tts model can generate high-quality, natural-sounding speech with a range of customizable features. Users can control the gender, pitch, speaking rate, and environmental factors of the generated audio by carefully crafting the text description. This allows for a high degree of flexibility and creativity in the generated output, making it useful for a variety of applications, such as audio production, virtual assistants, and language learning.
What can I use it for?
The parler-tts model can be used in a variety of applications that require text-to-speech functionality. Some potential use cases include:
- Audio production: The model can be used to generate natural-sounding voice-overs, narrations, or audio content for videos, podcasts, or other multimedia projects.
- Virtual assistants: The model's ability to generate speech with customizable characteristics can be used to create more personalized and engaging virtual assistants.
- Language learning: The model can be used to generate sample audio for language learning materials, providing learners with high-quality examples of pronunciation and intonation.
- Accessibility: The model can be used to generate audio versions of text content, improving accessibility for individuals with visual impairments or reading difficulties.
Things to try
One interesting aspect of the parler-tts model is its ability to generate speech with a high degree of control over the output characteristics. Users can experiment with different text descriptions to explore the range of speech styles and environmental factors that the model can produce. For example, try using different descriptors for the speaker's gender, pitch, and speaking rate, or add details about the recording environment, such as the level of background noise or reverberation. By fine-tuning the text description, users can create a wide variety of speech samples that can be used for various applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Models
voicecraft
8
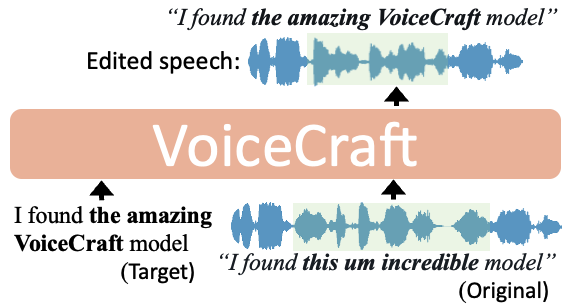
VoiceCraft is a token infilling neural codec language model developed by the maintainer cjwbw. It achieves state-of-the-art performance on both speech editing and zero-shot text-to-speech (TTS) on in-the-wild data including audiobooks, internet videos, and podcasts. Unlike similar voice cloning models like instant-id which require high-quality reference audio, VoiceCraft can clone an unseen voice with just a few seconds of reference. Model inputs and outputs VoiceCraft is a versatile model that can be used for both speech editing and zero-shot text-to-speech. For speech editing, the model takes in the original audio, the transcript, and target edits to the transcript. For zero-shot TTS, the model only requires a few seconds of reference audio and the target transcript. Inputs Original audio**: The audio file to be edited or used as a reference for TTS Original transcript**: The transcript of the original audio, can be automatically generated using a model like WhisperX Target transcript**: The desired transcript for the edited or synthesized audio Reference audio duration**: The duration of the original audio to use as a reference for zero-shot TTS Outputs Edited audio**: The audio with the specified edits applied Synthesized audio**: The audio generated from the target transcript using the reference audio Capabilities VoiceCraft is capable of high-quality speech editing and zero-shot text-to-speech. It can seamlessly blend new content into existing audio, enabling tasks like adding or removing words, changing the speaker's voice, or modifying emotional tone. For zero-shot TTS, VoiceCraft can generate natural-sounding speech in the voice of the reference audio, without any fine-tuning or additional training. What can I use it for? VoiceCraft can be used in a variety of applications, such as podcast production, audiobook creation, video dubbing, and voice assistant development. With its ability to edit and synthesize speech, creators can efficiently produce high-quality audio content without the need for extensive post-production work or specialized recording equipment. Additionally, VoiceCraft can be used to create personalized text-to-speech applications, where users can have their content read aloud in a voice of their choice. Things to try One interesting thing to try with VoiceCraft is to use it for speech-to-speech translation. By providing the model with an audio clip in one language and the transcript in the target language, it can generate the translated audio in the voice of the original speaker. This can be particularly useful for international collaborations or accessibility purposes. Another idea is to explore the model's capabilities for audio restoration and enhancement. By providing VoiceCraft with a low-quality audio recording and the desired improvements, it may be able to generate a higher-quality version of the audio, while preserving the original speaker's voice.
Updated Invalid Date
↗️
whisper
52
whisper is a large, general-purpose speech recognition model developed by OpenAI. It is trained on a diverse dataset of audio and can perform a variety of speech-related tasks, including multilingual speech recognition, speech translation, and spoken language identification. The whisper model is available in different sizes, with the larger models offering better accuracy at the cost of increased memory and compute requirements. The maintainer, cjwbw, has also created several similar models, such as stable-diffusion-2-1-unclip, anything-v3-better-vae, and dreamshaper, that explore different approaches to image generation and manipulation. Model inputs and outputs The whisper model is a sequence-to-sequence model that takes audio as input and produces a text transcript as output. It can handle a variety of audio formats, including FLAC, MP3, and WAV files. The model can also be used to perform speech translation, where the input audio is in one language and the output text is in another language. Inputs audio**: The audio file to be transcribed, in a supported format such as FLAC, MP3, or WAV. model**: The size of the whisper model to use, with options ranging from tiny to large. language**: The language spoken in the audio, or None to perform language detection. translate**: A boolean flag to indicate whether the output should be translated to English. Outputs transcription**: The text transcript of the input audio, in the specified format (e.g., plain text). Capabilities The whisper model is capable of performing high-quality speech recognition across a wide range of languages, including less common languages. It can also handle various accents and speaking styles, making it a versatile tool for transcribing diverse audio content. The model's ability to perform speech translation is particularly useful for applications where users need to consume content in a language they don't understand. What can I use it for? The whisper model can be used in a variety of applications, such as: Transcribing audio recordings for content creation, research, or accessibility purposes. Translating speech-based content, such as videos or podcasts, into multiple languages. Integrating speech recognition and translation capabilities into chatbots, virtual assistants, or other conversational interfaces. Automating the captioning or subtitling of video content. Things to try One interesting aspect of the whisper model is its ability to detect the language spoken in the audio, even if it's not provided as an input. This can be useful for applications where the language is unknown or variable, such as transcribing multilingual conversations. Additionally, the model's performance can be fine-tuned by adjusting parameters like temperature, patience, and suppressed tokens, which can help improve accuracy for specific use cases.
Updated Invalid Date
whisper
30.8K
Whisper is a general-purpose speech recognition model developed by OpenAI. It is capable of converting speech in audio to text, with the ability to translate the text to English if desired. Whisper is based on a large Transformer model trained on a diverse dataset of multilingual and multitask speech recognition data. This allows the model to handle a wide range of accents, background noises, and languages. Similar models like whisper-large-v3, incredibly-fast-whisper, and whisper-diarization offer various optimizations and additional features built on top of the core Whisper model. Model inputs and outputs Whisper takes an audio file as input and outputs a text transcription. The model can also translate the transcription to English if desired. The input audio can be in various formats, and the model supports a range of parameters to fine-tune the transcription, such as temperature, patience, and language. Inputs Audio**: The audio file to be transcribed Model**: The specific version of the Whisper model to use, currently only large-v3 is supported Language**: The language spoken in the audio, or None to perform language detection Translate**: A boolean flag to translate the transcription to English Transcription**: The format for the transcription output, such as "plain text" Initial Prompt**: An optional initial text prompt to provide to the model Suppress Tokens**: A list of token IDs to suppress during sampling Logprob Threshold**: The minimum average log probability threshold for a successful transcription No Speech Threshold**: The threshold for considering a segment as silence Condition on Previous Text**: Whether to provide the previous output as a prompt for the next window Compression Ratio Threshold**: The maximum compression ratio threshold for a successful transcription Temperature Increment on Fallback**: The temperature increase when the decoding fails to meet the specified thresholds Outputs Transcription**: The text transcription of the input audio Language**: The detected language of the audio (if language input is None) Tokens**: The token IDs corresponding to the transcription Timestamp**: The start and end timestamps for each word in the transcription Confidence**: The confidence score for each word in the transcription Capabilities Whisper is a powerful speech recognition model that can handle a wide range of accents, background noises, and languages. The model is capable of accurately transcribing audio and optionally translating the transcription to English. This makes Whisper useful for a variety of applications, such as real-time captioning, meeting transcription, and audio-to-text conversion. What can I use it for? Whisper can be used in various applications that require speech-to-text conversion, such as: Captioning and Subtitling**: Automatically generate captions or subtitles for videos, improving accessibility for viewers. Meeting Transcription**: Transcribe audio recordings of meetings, interviews, or conferences for easy review and sharing. Podcast Transcription**: Convert audio podcasts to text, making the content more searchable and accessible. Language Translation**: Transcribe audio in one language and translate the text to another, enabling cross-language communication. Voice Interfaces**: Integrate Whisper into voice-controlled applications, such as virtual assistants or smart home devices. Things to try One interesting aspect of Whisper is its ability to handle a wide range of languages and accents. You can experiment with the model's performance on audio samples in different languages or with various background noises to see how it handles different real-world scenarios. Additionally, you can explore the impact of the different input parameters, such as temperature, patience, and language detection, on the transcription quality and accuracy.
Updated Invalid Date

chat-tts
29
chat-tts is an implementation of the ChatTTS model as a Cog model, developed by maintainer thlz998. It is similar to other text-to-speech models like bel-tts, neon-tts, and xtts-v2, which also aim to convert text into human-like speech. Model inputs and outputs chat-tts takes in text that it will synthesize into speech. It also allows for adjusting various parameters like voice, temperature, and top-k sampling to control the generated audio output. Inputs text**: The text to be synthesized into speech. voice**: A number that determines the voice tone, with options like 2222, 7869, 6653, 4099, 5099. prompt**: Sets laughter, pauses, and other audio cues. temperature**: Adjusts the sampling temperature. top_p**: Sets the nucleus sampling top-p value. top_k**: Sets the top-k sampling value. skip_refine**: Determines whether to skip the text refinement step. custom_voice**: Allows specifying a seed value for custom voice tone generation. Outputs The generated speech audio based on the provided text and parameters. Capabilities chat-tts can generate human-like speech from text, allowing for customization of the voice, tone, and other audio characteristics. It can be useful for applications that require text-to-speech functionality, such as audio books, virtual assistants, or multimedia content. What can I use it for? chat-tts could be used in projects that require text-to-speech capabilities, such as: Creating audio books or audiobook samples Developing virtual assistants or chatbots with voice output Generating spoken content for educational materials or podcasts Enhancing multimedia presentations or videos with narration Things to try With chat-tts, you can experiment with different voice settings, prompts, and sampling parameters to create unique speech outputs. For example, you could try generating speech with different emotional tones or accents by adjusting the voice and prompt inputs. Additionally, you could explore using the custom voice feature to generate more personalized speech outputs.
Updated Invalid Date