whisperx-spanish
Maintainer: mercurio005

43
🏷️
| Property | Value |
|---|---|
| Run this model | Run on Replicate |
| API spec | View on Replicate |
| Github link | No Github link provided |
| Paper link | No paper link provided |
Create account to get full access
Model overview
The whisperx-spanish model is a Spanish-language speech recognition model developed by the Replicate AI creator mercurio005. It is based on the popular Whisper model, which has shown impressive performance in transcribing speech across a variety of languages. The whisperx-spanish model aims to provide accurate transcription specifically for Spanish audio.
Similar models include whisperspeech-small, which is an open-source text-to-speech system built by inverting Whisper, as well as other Whisper-based models like whisperx-video-transcribe, whisperx, whisper-diarization, and whisperx-a40-large.
Model inputs and outputs
The whisperx-spanish model takes a single input: an audio file. Users can also provide optional parameters like debug, token, just_text, batch_size, diarization, max_speakers, and min_speakers to customize the model's behavior.
Inputs
- audio: Audio file to be transcribed
- debug: Print out memory usage information (default: false)
- token: HuggingFace token for diarization
- just_text: Use if you only need output text without timestamps (when diarization is true)
- batch_size: Parallelization of input audio transcription (default: 32)
- diarization: Separate speakers from transcription (default: false)
- max_speakers: Maximum number of speakers
- min_speakers: Minimum number of speakers
Outputs
- Output: The transcribed text from the input audio
Capabilities
The whisperx-spanish model is capable of accurately transcribing Spanish-language audio. It leverages the powerful Whisper model as its foundation, which has shown strong performance across a wide range of languages. The addition of the "x" in the model name indicates that it also provides features like accelerated transcription, word-level timestamps, and speaker diarization.
What can I use it for?
The whisperx-spanish model can be useful for a variety of applications that require accurate Spanish speech transcription, such as:
- Automated captioning and subtitling of Spanish-language videos
- Transcription of Spanish-language audio recordings for content creation or research purposes
- Integration into conversational AI systems that need to understand and respond to Spanish-language input
By leveraging the capabilities of the Whisper model and adding Spanish-specific optimizations, the whisperx-spanish model can be a valuable tool for developers and researchers working with Spanish-language audio data.
Things to try
One interesting aspect of the whisperx-spanish model is its ability to perform speaker diarization, which allows it to separate the transcription into individual speaker segments. This can be particularly useful in scenarios where multiple speakers are present, such as interviews, meetings, or panel discussions. By leveraging the diarization features, users can gain deeper insights into the conversational dynamics and attribution of specific statements to individual speakers.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Models

whisperx
49
whisperx is a Cog implementation of the WhisperX library, which adds batch processing on top of the popular Whisper speech recognition model. This allows for very fast audio transcription compared to the original Whisper model. whisperx is developed and maintained by daanelson. Similar models include whisperx-victor-upmeet, which provides accelerated transcription, word-level timestamps, and diarization with the Whisper large-v3 model, and whisper-diarization-thomasmol, which offers fast audio transcription, speaker diarization, and word-level timestamps. Model inputs and outputs whisperx takes an audio file as input, along with optional parameters to control the batch size, whether to output only the transcribed text or include segment metadata, and whether to print out memory usage information for debugging purposes. Inputs audio**: The audio file to be transcribed batch_size**: The number of audio segments to process in parallel for faster transcription only_text**: A boolean flag to return only the transcribed text, without segment metadata align_output**: A boolean flag to generate word-level timestamps (currently only works for English) debug**: A boolean flag to print out memory usage information Outputs The transcribed text, optionally with segment-level metadata Capabilities whisperx builds on the strong speech recognition capabilities of the Whisper model, providing accelerated transcription through batch processing. This can be particularly useful for transcribing long audio files or processing multiple audio files in parallel. What can I use it for? whisperx can be used for a variety of applications that require fast and accurate speech-to-text transcription, such as podcast production, video captioning, or meeting minutes generation. The ability to process audio in batches and the option to output only the transcribed text can make the model well-suited for high-volume or real-time transcription scenarios. Things to try One interesting aspect of whisperx is the ability to generate word-level timestamps, which can be useful for applications like video editing or language learning. You can experiment with the align_output parameter to see how this feature performs on your audio files. Another thing to try is leveraging the batch processing capabilities of whisperx to transcribe multiple audio files in parallel, which can significantly reduce the overall processing time for large-scale transcription tasks.
Updated Invalid Date
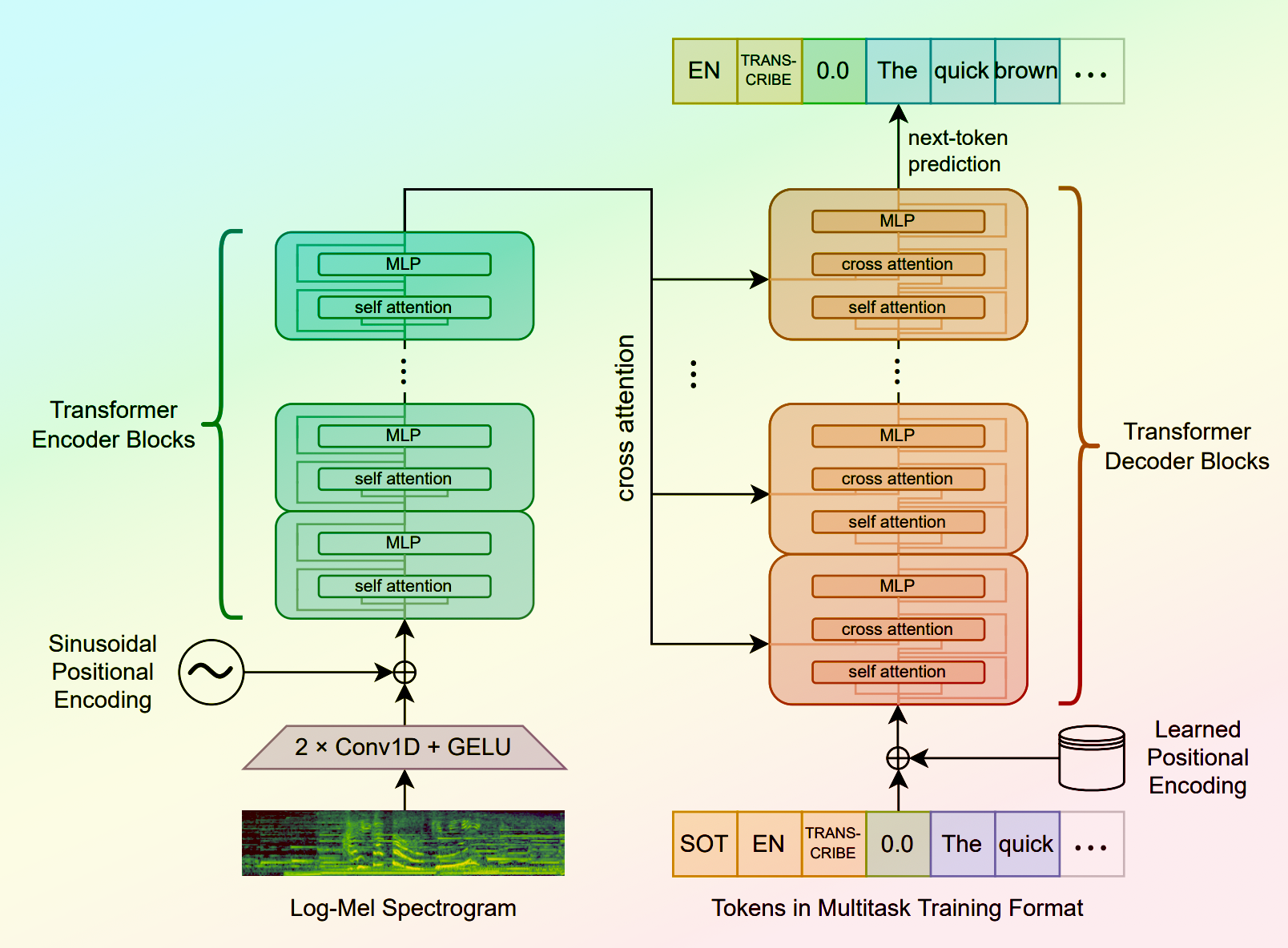
whisper
33.7K
Whisper is a general-purpose speech recognition model developed by OpenAI. It is capable of converting speech in audio to text, with the ability to translate the text to English if desired. Whisper is based on a large Transformer model trained on a diverse dataset of multilingual and multitask speech recognition data. This allows the model to handle a wide range of accents, background noises, and languages. Similar models like whisper-large-v3, incredibly-fast-whisper, and whisper-diarization offer various optimizations and additional features built on top of the core Whisper model. Model inputs and outputs Whisper takes an audio file as input and outputs a text transcription. The model can also translate the transcription to English if desired. The input audio can be in various formats, and the model supports a range of parameters to fine-tune the transcription, such as temperature, patience, and language. Inputs Audio**: The audio file to be transcribed Model**: The specific version of the Whisper model to use, currently only large-v3 is supported Language**: The language spoken in the audio, or None to perform language detection Translate**: A boolean flag to translate the transcription to English Transcription**: The format for the transcription output, such as "plain text" Initial Prompt**: An optional initial text prompt to provide to the model Suppress Tokens**: A list of token IDs to suppress during sampling Logprob Threshold**: The minimum average log probability threshold for a successful transcription No Speech Threshold**: The threshold for considering a segment as silence Condition on Previous Text**: Whether to provide the previous output as a prompt for the next window Compression Ratio Threshold**: The maximum compression ratio threshold for a successful transcription Temperature Increment on Fallback**: The temperature increase when the decoding fails to meet the specified thresholds Outputs Transcription**: The text transcription of the input audio Language**: The detected language of the audio (if language input is None) Tokens**: The token IDs corresponding to the transcription Timestamp**: The start and end timestamps for each word in the transcription Confidence**: The confidence score for each word in the transcription Capabilities Whisper is a powerful speech recognition model that can handle a wide range of accents, background noises, and languages. The model is capable of accurately transcribing audio and optionally translating the transcription to English. This makes Whisper useful for a variety of applications, such as real-time captioning, meeting transcription, and audio-to-text conversion. What can I use it for? Whisper can be used in various applications that require speech-to-text conversion, such as: Captioning and Subtitling**: Automatically generate captions or subtitles for videos, improving accessibility for viewers. Meeting Transcription**: Transcribe audio recordings of meetings, interviews, or conferences for easy review and sharing. Podcast Transcription**: Convert audio podcasts to text, making the content more searchable and accessible. Language Translation**: Transcribe audio in one language and translate the text to another, enabling cross-language communication. Voice Interfaces**: Integrate Whisper into voice-controlled applications, such as virtual assistants or smart home devices. Things to try One interesting aspect of Whisper is its ability to handle a wide range of languages and accents. You can experiment with the model's performance on audio samples in different languages or with various background noises to see how it handles different real-world scenarios. Additionally, you can explore the impact of the different input parameters, such as temperature, patience, and language detection, on the transcription quality and accuracy.
Updated Invalid Date

whisperx-video-transcribe
5
The whisperx-video-transcribe model is a speech recognition system that can transcribe audio from video URLs. It is based on the Whisper model, a large multilingual speech recognition system developed by Anthropic. The whisperx-video-transcribe model uses the Whisper large-v2 model and adds additional features such as accelerated transcription, word-level timestamps, and speaker diarization. This model is similar to other Whisper-based models like whisperx, incredibly-fast-whisper, and whisper-diarization, which offer various optimizations and additional capabilities on top of the Whisper base model. Model inputs and outputs The whisperx-video-transcribe model takes a video URL as input and outputs the transcribed text. The model also supports optional parameters for debugging and batch processing. Inputs url**: The URL of the video to be transcribed. The model supports a variety of video hosting platforms, which can be found on the Supported Sites page. debug**: A boolean flag to print out memory usage information. batch_size**: The number of audio segments to process in parallel, which can improve transcription speed. Outputs Output**: The transcribed text from the input video. Capabilities The whisperx-video-transcribe model can accurately transcribe audio from a wide range of video sources, with support for multiple languages and the ability to generate word-level timestamps and speaker diarization. The model's performance is enhanced by the Whisper large-v2 base model and the additional optimizations provided by the whisperx framework. What can I use it for? The whisperx-video-transcribe model can be useful for a variety of applications, such as: Automated video captioning and subtitling Generating transcripts for podcasts, interviews, or other audio/video content Improving accessibility by providing text versions of media for users who are deaf or hard of hearing Powering search and discovery features for video-based content By leveraging the capabilities of the whisperx-video-transcribe model, you can streamline your video content workflows, enhance user experiences, and unlock new opportunities for your business or project. Things to try One interesting aspect of the whisperx-video-transcribe model is its ability to handle multiple speakers and generate speaker diarization. This can be particularly useful for transcribing interviews, panel discussions, or other multi-speaker scenarios. You could experiment with different video sources and see how the model performs in terms of accurately identifying and separating the individual speakers. Another interesting area to explore is the model's performance on different types of video content, such as educational videos, news broadcasts, or user-generated content. You could test the model's accuracy and robustness across a variety of use cases and identify any areas for improvement or fine-tuning.
Updated Invalid Date

whisperx
354
whisperx is a speech transcription model developed by researchers at Upmeet. It builds upon OpenAI's Whisper model, adding features like accelerated transcription, word-level timestamps, and speaker diarization. Unlike the original Whisper, whisperx supports batching for faster processing of long-form audio. It also offers several model variants optimized for different hardware setups, including the victor-upmeet/whisperx-a40-large and victor-upmeet/whisperx-a100-80gb models. Model inputs and outputs whisperx takes an audio file as input and generates a transcript with word-level timestamps and optional speaker diarization. It can handle a variety of audio formats and supports language detection and automatic transcription of multiple languages. Inputs Audio File**: The audio file to be transcribed Language**: The ISO code of the language spoken in the audio (optional, can be automatically detected) VAD Onset/Offset**: Parameters for voice activity detection Diarization**: Whether to assign speaker ID labels Alignment**: Whether to align the transcript to get accurate word-level timestamps Speaker Limits**: Minimum and maximum number of speakers for diarization Outputs Detected Language**: The ISO code of the detected language Segments**: The transcribed text, with word-level timestamps and optional speaker IDs Capabilities whisperx provides fast and accurate speech transcription, with the ability to generate word-level timestamps and identify multiple speakers. It outperforms the original Whisper model in terms of transcription speed and timestamp accuracy, making it well-suited for use cases such as video captioning, podcast transcription, and meeting notes generation. What can I use it for? whisperx can be used in a variety of applications that require accurate speech-to-text conversion, such as: Video Captioning**: Generate captions for videos with precise timing and speaker identification. Podcast Transcription**: Automatically transcribe podcasts and audio recordings with timestamps and diarization. Meeting Notes**: Transcribe meetings and discussions, with the ability to attribute statements to individual speakers. Voice Interfaces**: Integrate whisperx into voice-based applications and services for improved accuracy and responsiveness. Things to try Consider experimenting with different model variants of whisperx to find the best fit for your hardware and use case. The victor-upmeet/whisperx model is a good starting point, but the victor-upmeet/whisperx-a40-large and victor-upmeet/whisperx-a100-80gb models may be more suitable if you encounter memory issues when dealing with long audio files or when performing alignment and diarization.
Updated Invalid Date