3D-COCO: extension of MS-COCO dataset for image detection and 3D reconstruction modules

0

Sign in to get full access
Overview
- This paper introduces a new dataset called 3D-COCO, which extends the popular MS-COCO dataset for scene understanding and 3D reconstruction tasks.
- The 3D-COCO dataset provides additional annotations for existing COCO images, including 3D object poses, 3D bounding boxes, and camera parameters.
- The goal of 3D-COCO is to enable the development of more advanced 3D computer vision models that can operate on real-world scenes.
Plain English Explanation
The MS-COCO dataset is a widely used collection of images that have been annotated to help train machine learning models for tasks like object detection and image segmentation. However, the original COCO dataset only provides 2D annotations, which limits its usefulness for developing 3D computer vision models.
To address this, the authors of this paper created the 3D-COCO dataset. 3D-COCO builds on the existing COCO images, but adds new annotations that capture the 3D structure of the scenes. This includes information like the 3D poses of objects, the 3D bounding boxes around those objects, and the camera parameters used to capture the images.
By having access to this 3D data, researchers can now train machine learning models to not only recognize objects in 2D images, but also understand their 3D relationships and spatial layout. This could lead to breakthroughs in areas like 3D scene understanding, 3D object detection, and 3D-aware image analysis.
The 3D-COCO dataset provides a valuable new resource for the computer vision community, enabling the development of more advanced 3D modeling and scene understanding capabilities.
Technical Explanation
The paper describes the process of creating the 3D-COCO dataset, which extends the existing MS-COCO dataset with additional 3D annotations. First, the authors collected 3D models for common household objects found in the COCO images. They then used these 3D models to estimate the 3D poses and bounding boxes of the objects in each image, as well as the camera parameters used to capture the scene.
The key technical contributions of the paper include:
- A pipeline for automatically aligning 3D object models to the 2D COCO images, allowing them to extract the 3D pose information.
- Novel algorithms for estimating the 3D bounding boxes and camera parameters from the 2D image data.
- Rigorous evaluation of the 3D annotations to ensure they are accurate and useful for training machine learning models.
The authors demonstrate the value of the 3D-COCO dataset by training various 3D vision models on the data, including 3D object detection, 3D scene understanding, and 3D-aware image alignment. These experiments show significant performance improvements over models trained on the original 2D COCO dataset alone.
Critical Analysis
The 3D-COCO dataset represents an important step forward for the field of 3D computer vision. By providing a large-scale dataset with rich 3D annotations, it enables researchers to develop more advanced models that can truly understand the 3D structure of real-world scenes.
However, the paper does acknowledge some limitations of the dataset. For example, the 3D object models used to estimate the annotations may not perfectly match the objects in the images, leading to some noise or inaccuracies in the 3D data. Additionally, the dataset only covers a subset of the original COCO images and object categories, so it may not be representative of the full diversity of real-world scenes.
It would also be valuable to see the 3D-COCO dataset expanded over time, with additional images, object categories, and potentially even dynamic scene information (e.g., videos with 3D annotations). Continued curation and expansion of the dataset could make it an even more powerful resource for the computer vision community.
Conclusion
The 3D-COCO dataset introduced in this paper represents an important advancement in the field of 3D computer vision. By extending the popular MS-COCO dataset with rich 3D annotations, it provides a valuable new resource for training and evaluating machine learning models that can understand the 3D structure of real-world scenes.
The technical contributions of the paper, including the methods for automatically aligning 3D object models and estimating 3D bounding boxes and camera parameters, are significant advances that enable the creation of this valuable dataset. While the dataset has some limitations, it is a crucial step towards developing more advanced 3D vision capabilities that could have far-reaching impacts in areas like robotics, augmented reality, and autonomous systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
3D-COCO: extension of MS-COCO dataset for image detection and 3D reconstruction modules
Maxence Bideaux, Alice Phe, Mohamed Chaouch, Bertrand Luvison, Quoc-Cuong Pham
We introduce 3D-COCO, an extension of the original MS-COCO dataset providing 3D models and 2D-3D alignment annotations. 3D-COCO was designed to achieve computer vision tasks such as 3D reconstruction or image detection configurable with textual, 2D image, and 3D CAD model queries. We complete the existing MS-COCO dataset with 28K 3D models collected on ShapeNet and Objaverse. By using an IoU-based method, we match each MS-COCO annotation with the best 3D models to provide a 2D-3D alignment. The open-source nature of 3D-COCO is a premiere that should pave the way for new research on 3D-related topics. The dataset and its source codes is available at https://kalisteo.cea.fr/index.php/coco3d-object-detection-and-reconstruction/
Read more7/17/2024
🔎
0
Every Dataset Counts: Scaling up Monocular 3D Object Detection with Joint Datasets Training
Fulong Ma, Xiaoyang Yan, Guoyang Zhao, Xiaojie Xu, Yuxuan Liu, Ming Liu
Monocular 3D object detection plays a crucial role in autonomous driving. However, existing monocular 3D detection algorithms depend on 3D labels derived from LiDAR measurements, which are costly to acquire for new datasets and challenging to deploy in novel environments. Specifically, this study investigates the pipeline for training a monocular 3D object detection model on a diverse collection of 3D and 2D datasets. The proposed framework comprises three components: (1) a robust monocular 3D model capable of functioning across various camera settings, (2) a selective-training strategy to accommodate datasets with differing class annotations, and (3) a pseudo 3D training approach using 2D labels to enhance detection performance in scenes containing only 2D labels. With this framework, we could train models on a joint set of various open 3D/2D datasets to obtain models with significantly stronger generalization capability and enhanced performance on new dataset with only 2D labels. We conduct extensive experiments on KITTI/nuScenes/ONCE/Cityscapes/BDD100K datasets to demonstrate the scaling ability of the proposed method.
Read more8/9/2024
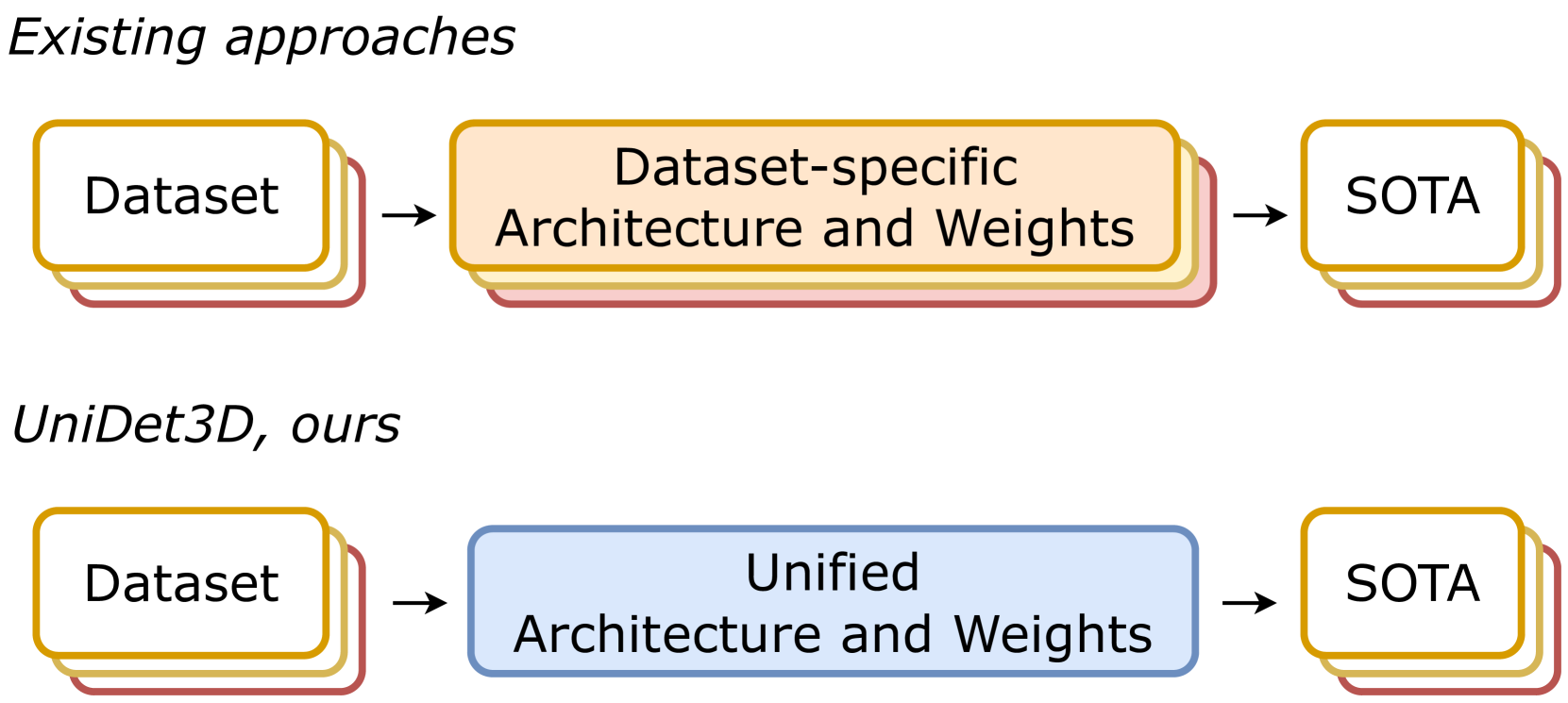
0
UniDet3D: Multi-dataset Indoor 3D Object Detection
Maksim Kolodiazhnyi, Anna Vorontsova, Matvey Skripkin, Danila Rukhovich, Anton Konushin
Growing customer demand for smart solutions in robotics and augmented reality has attracted considerable attention to 3D object detection from point clouds. Yet, existing indoor datasets taken individually are too small and insufficiently diverse to train a powerful and general 3D object detection model. In the meantime, more general approaches utilizing foundation models are still inferior in quality to those based on supervised training for a specific task. In this work, we propose ours{}, a simple yet effective 3D object detection model, which is trained on a mixture of indoor datasets and is capable of working in various indoor environments. By unifying different label spaces, ours{} enables learning a strong representation across multiple datasets through a supervised joint training scheme. The proposed network architecture is built upon a vanilla transformer encoder, making it easy to run, customize and extend the prediction pipeline for practical use. Extensive experiments demonstrate that ours{} obtains significant gains over existing 3D object detection methods in 6 indoor benchmarks: ScanNet (+1.1 mAP50), ARKitScenes (+19.4 mAP25), S3DIS (+9.1 mAP50), MultiScan (+9.3 mAP50), 3RScan (+3.2 mAP50), and ScanNet++ (+2.7 mAP50). Code is available at https://github.com/filapro/unidet3d .
Read more9/9/2024

0
ImageNet3D: Towards General-Purpose Object-Level 3D Understanding
Wufei Ma, Guanning Zeng, Guofeng Zhang, Qihao Liu, Letian Zhang, Adam Kortylewski, Yaoyao Liu, Alan Yuille
A vision model with general-purpose object-level 3D understanding should be capable of inferring both 2D (e.g., class name and bounding box) and 3D information (e.g., 3D location and 3D viewpoint) for arbitrary rigid objects in natural images. This is a challenging task, as it involves inferring 3D information from 2D signals and most importantly, generalizing to rigid objects from unseen categories. However, existing datasets with object-level 3D annotations are often limited by the number of categories or the quality of annotations. Models developed on these datasets become specialists for certain categories or domains, and fail to generalize. In this work, we present ImageNet3D, a large dataset for general-purpose object-level 3D understanding. ImageNet3D augments 200 categories from the ImageNet dataset with 2D bounding box, 3D pose, 3D location annotations, and image captions interleaved with 3D information. With the new annotations available in ImageNet3D, we could (i) analyze the object-level 3D awareness of visual foundation models, and (ii) study and develop general-purpose models that infer both 2D and 3D information for arbitrary rigid objects in natural images, and (iii) integrate unified 3D models with large language models for 3D-related reasoning.. We consider two new tasks, probing of object-level 3D awareness and open vocabulary pose estimation, besides standard classification and pose estimation. Experimental results on ImageNet3D demonstrate the potential of our dataset in building vision models with stronger general-purpose object-level 3D understanding.
Read more6/17/2024