3D Weakly Supervised Semantic Segmentation with 2D Vision-Language Guidance

0

Sign in to get full access
Overview
- This paper presents a novel approach for 3D weakly supervised semantic segmentation using 2D vision-language guidance.
- The key idea is to leverage 2D image-text pairs to guide the learning of 3D semantic segmentation models, without requiring fully annotated 3D data.
- The method outperforms previous weakly supervised 3D segmentation techniques on popular benchmarks, demonstrating the power of combining 2D vision-language understanding with 3D shape reasoning.
Plain English Explanation
The paper describes a way to train 3D object segmentation models without needing lots of detailed 3D data. Instead, it uses 2D images and their text descriptions to guide the model in learning to segment 3D objects. This 2D vision-language guidance allows the model to learn the semantic meanings of 3D shapes even when full 3D annotations are not available.
The key insight is that while getting fully annotated 3D data is difficult, 2D image-text pairs are much easier to obtain. By connecting the 2D information to the 3D shapes, the model can learn to segment 3D objects without relying solely on 3D data. This weakly supervised approach is more efficient than requiring detailed 3D annotations for every training example.
The authors show that their method outperforms previous weakly supervised 3D segmentation techniques, indicating that the combination of 2D vision-language understanding and 3D shape reasoning is a powerful way to tackle this challenging problem. This could lead to more accessible 3D perception models that don't require as much specialized 3D data to train.
Technical Explanation
The proposed method leverages 2D vision-language models to guide the training of a 3D semantic segmentation network in a weakly supervised manner. The key components are:
- A 2D vision-language model that maps images and their text descriptions to a shared embedding space.
- A 3D segmentation network that takes 3D point cloud data as input and predicts semantic segmentation masks.
- A cross-modal alignment module that connects the 2D vision-language embedding to the 3D segmentation features.
During training, the 2D vision-language embeddings are used to provide weak labels for the 3D segmentation network, without requiring exhaustive 3D annotations. The cross-modal alignment module ensures the 3D segmentation learns to match the semantic information from the 2D vision-language model.
Experiments on benchmark 3D segmentation datasets show this weakly supervised approach outperforms prior methods that rely solely on limited 3D annotations. The authors attribute this success to the rich semantic understanding captured by the 2D vision-language model, which can be effectively transferred to guide 3D shape reasoning.
Critical Analysis
The paper presents a compelling approach to address the challenge of 3D semantic segmentation in the absence of extensive 3D training data. By leveraging 2D vision-language models, the method can learn meaningful 3D segmentation without requiring full 3D annotations.
However, the authors note that the performance is still below that of fully supervised 3D segmentation models. Additionally, the cross-modal alignment between 2D and 3D features may be imperfect, potentially limiting the transferability of semantic information.
Further research could explore ways to improve the 2D-3D alignment, perhaps through more advanced cross-modal learning techniques. Additionally, incorporating other sources of weak 3D supervision, such as segmentation-by-parts or object detection signals, could potentially boost performance.
Overall, this work represents an important step towards more accessible 3D perception models that can be trained with less specialized 3D data. As the authors note, the approach has promising applications in areas like 3D scene understanding and augmented reality.
Conclusion
This paper presents a novel 3D weakly supervised semantic segmentation method that leverages 2D vision-language guidance. By connecting 2D image-text understanding to 3D shape reasoning, the approach can learn effective 3D segmentation models without requiring exhaustive 3D annotations.
The key innovation is the use of 2D vision-language models to provide weak labels for the 3D segmentation network, enabling it to learn semantic meaning from more readily available 2D data. The authors demonstrate the effectiveness of this approach on benchmark 3D segmentation tasks, outperforming prior weakly supervised techniques.
This work advances the field of 3D perception by showing how to create powerful 3D models without relying on hard-to-obtain fully annotated 3D data. The methods and insights from this paper could lead to more accessible 3D understanding systems with applications in areas like robotics, augmented reality, and scene analysis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
3D Weakly Supervised Semantic Segmentation with 2D Vision-Language Guidance
Xiaoxu Xu, Yitian Yuan, Jinlong Li, Qiudan Zhang, Zequn Jie, Lin Ma, Hao Tang, Nicu Sebe, Xu Wang
In this paper, we propose 3DSS-VLG, a weakly supervised approach for 3D Semantic Segmentation with 2D Vision-Language Guidance, an alternative approach that a 3D model predicts dense-embedding for each point which is co-embedded with both the aligned image and text spaces from the 2D vision-language model. Specifically, our method exploits the superior generalization ability of the 2D vision-language models and proposes the Embeddings Soft-Guidance Stage to utilize it to implicitly align 3D embeddings and text embeddings. Moreover, we introduce the Embeddings Specialization Stage to purify the feature representation with the help of a given scene-level label, specifying a better feature supervised by the corresponding text embedding. Thus, the 3D model is able to gain informative supervisions both from the image embedding and text embedding, leading to competitive segmentation performances. To the best of our knowledge, this is the first work to investigate 3D weakly supervised semantic segmentation by using the textual semantic information of text category labels. Moreover, with extensive quantitative and qualitative experiments, we present that our 3DSS-VLG is able not only to achieve the state-of-the-art performance on both S3DIS and ScanNet datasets, but also to maintain strong generalization capability.
Read more9/2/2024

0
Weakly-Supervised 3D Visual Grounding based on Visual Linguistic Alignment
Xiaoxu Xu, Yitian Yuan, Qiudan Zhang, Wenhui Wu, Zequn Jie, Lin Ma, Xu Wang
Learning to ground natural language queries to target objects or regions in 3D point clouds is quite essential for 3D scene understanding. Nevertheless, existing 3D visual grounding approaches require a substantial number of bounding box annotations for text queries, which is time-consuming and labor-intensive to obtain. In this paper, we propose 3D-VLA, a weakly supervised approach for 3D visual grounding based on Visual Linguistic Alignment. Our 3D-VLA exploits the superior ability of current large-scale vision-language models (VLMs) on aligning the semantics between texts and 2D images, as well as the naturally existing correspondences between 2D images and 3D point clouds, and thus implicitly constructs correspondences between texts and 3D point clouds with no need for fine-grained box annotations in the training procedure. During the inference stage, the learned text-3D correspondence will help us ground the text queries to the 3D target objects even without 2D images. To the best of our knowledge, this is the first work to investigate 3D visual grounding in a weakly supervised manner by involving large scale vision-language models, and extensive experiments on ReferIt3D and ScanRefer datasets demonstrate that our 3D-VLA achieves comparable and even superior results over the fully supervised methods.
Read more9/2/2024

0
Weakly Supervised 3D Object Detection via Multi-Level Visual Guidance
Kuan-Chih Huang, Yi-Hsuan Tsai, Ming-Hsuan Yang
Weakly supervised 3D object detection aims to learn a 3D detector with lower annotation cost, e.g., 2D labels. Unlike prior work which still relies on few accurate 3D annotations, we propose a framework to study how to leverage constraints between 2D and 3D domains without requiring any 3D labels. Specifically, we employ visual data from three perspectives to establish connections between 2D and 3D domains. First, we design a feature-level constraint to align LiDAR and image features based on object-aware regions. Second, the output-level constraint is developed to enforce the overlap between 2D and projected 3D box estimations. Finally, the training-level constraint is utilized by producing accurate and consistent 3D pseudo-labels that align with the visual data. We conduct extensive experiments on the KITTI dataset to validate the effectiveness of the proposed three constraints. Without using any 3D labels, our method achieves favorable performance against state-of-the-art approaches and is competitive with the method that uses 500-frame 3D annotations. Code will be made publicly available at https://github.com/kuanchihhuang/VG-W3D.
Read more8/22/2024
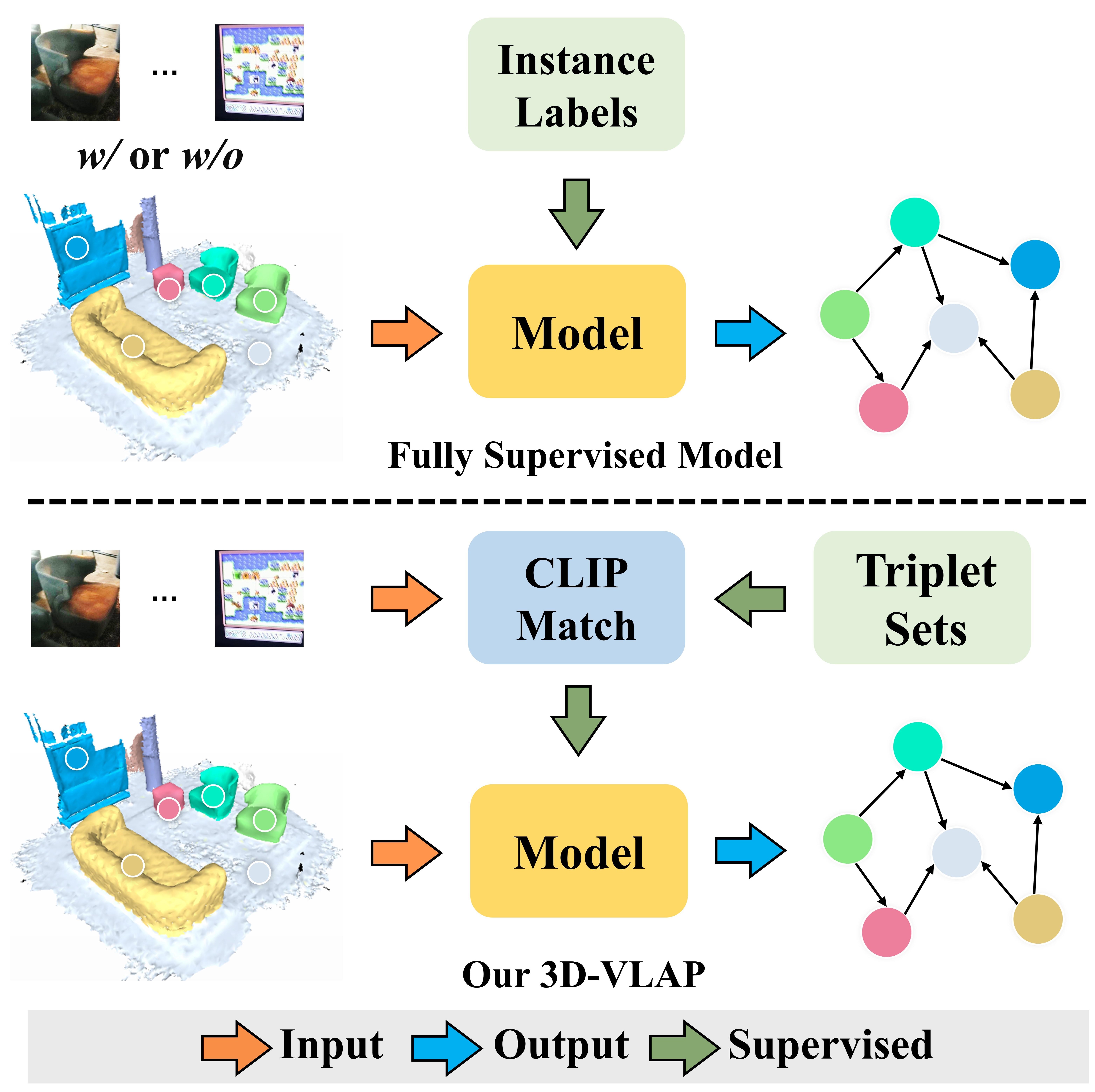
0
Weakly-Supervised 3D Scene Graph Generation via Visual-Linguistic Assisted Pseudo-labeling
Xu Wang, Yifan Li, Qiudan Zhang, Wenhui Wu, Mark Junjie Li, Jianmin Jinag
Learning to build 3D scene graphs is essential for real-world perception in a structured and rich fashion. However, previous 3D scene graph generation methods utilize a fully supervised learning manner and require a large amount of entity-level annotation data of objects and relations, which is extremely resource-consuming and tedious to obtain. To tackle this problem, we propose 3D-VLAP, a weakly-supervised 3D scene graph generation method via Visual-Linguistic Assisted Pseudo-labeling. Specifically, our 3D-VLAP exploits the superior ability of current large-scale visual-linguistic models to align the semantics between texts and 2D images, as well as the naturally existing correspondences between 2D images and 3D point clouds, and thus implicitly constructs correspondences between texts and 3D point clouds. First, we establish the positional correspondence from 3D point clouds to 2D images via camera intrinsic and extrinsic parameters, thereby achieving alignment of 3D point clouds and 2D images. Subsequently, a large-scale cross-modal visual-linguistic model is employed to indirectly align 3D instances with the textual category labels of objects by matching 2D images with object category labels. The pseudo labels for objects and relations are then produced for 3D-VLAP model training by calculating the similarity between visual embeddings and textual category embeddings of objects and relations encoded by the visual-linguistic model, respectively. Ultimately, we design an edge self-attention based graph neural network to generate scene graphs of 3D point cloud scenes. Extensive experiments demonstrate that our 3D-VLAP achieves comparable results with current advanced fully supervised methods, meanwhile significantly alleviating the pressure of data annotation.
Read more4/4/2024