3QFP: Efficient neural implicit surface reconstruction using Tri-Quadtrees and Fourier feature Positional encoding
2401.07164
0
0

Abstract
Neural implicit surface representations are currently receiving a lot of interest as a means to achieve high-fidelity surface reconstruction at a low memory cost, compared to traditional explicit representations.However, state-of-the-art methods still struggle with excessive memory usage and non-smooth surfaces. This is particularly problematic in large-scale applications with sparse inputs, as is common in robotics use cases. To address these issues, we first introduce a sparse structure, emph{tri-quadtrees}, which represents the environment using learnable features stored in three planar quadtree projections. Secondly, we concatenate the learnable features with a Fourier feature positional encoding. The combined features are then decoded into signed distance values through a small multi-layer perceptron. We demonstrate that this approach facilitates smoother reconstruction with a higher completion ratio with fewer holes. Compared to two recent baselines, one implicit and one explicit, our approach requires only 10%--50% as much memory, while achieving competitive quality.
Create account to get full access
Overview
- Efficient neural implicit surface reconstruction using Tri-Quadtrees and Fourier feature Positional encoding
- Proposes a novel method called 3QFP for reconstructing 3D surfaces from point cloud data
- Leverages Tri-Quadtrees and Fourier feature Positional encoding to achieve efficient and high-quality reconstruction
Plain English Explanation
This paper introduces a new technique called 3QFP for reconstructing 3D surfaces from point cloud data, which is data that represents the surface of an object as a collection of individual points in 3D space. The paper on InstantAvatar and the paper on Efficient 3D Implicit Head Avatar Mesh also deal with 3D surface reconstruction from point clouds.
The key innovations in 3QFP are the use of a data structure called Tri-Quadtrees and a technique called Fourier feature Positional encoding. Tri-Quadtrees allow the method to efficiently represent the 3D surface at different levels of detail, focusing computational resources on the most important regions. Fourier feature Positional encoding is a way of representing the 3D coordinates of the points in a form that helps the neural network learn the surface reconstruction more effectively.
By combining these two techniques, the 3QFP method is able to reconstruct 3D surfaces from point clouds accurately and efficiently, requiring less memory and computation than previous approaches. This could have applications in areas like 3D scene reconstruction, 3D object modeling, and 3D avatar generation.
Technical Explanation
The 3QFP method leverages two key innovations to achieve efficient and high-quality 3D surface reconstruction from point clouds:
-
Tri-Quadtrees: 3QFP uses a hierarchical data structure called Tri-Quadtrees to represent the 3D surface at multiple levels of detail. This allows the method to focus computational resources on the most important regions of the surface, improving efficiency.
-
Fourier Feature Positional Encoding: 3QFP encodes the 3D coordinates of the input points using Fourier feature Positional encoding, which helps the neural network learn the surface reconstruction more effectively.
The 3QFP network takes a point cloud as input and outputs a signed distance field (SDF), which is a volumetric representation of the 3D surface. The network is trained end-to-end using a combination of surface and interior loss functions to ensure accurate reconstruction.
The experiments demonstrate that 3QFP achieves state-of-the-art results on several 3D surface reconstruction benchmarks, while requiring significantly less memory and computation than previous methods.
Critical Analysis
The paper provides a thorough evaluation of the 3QFP method and its performance on various 3D surface reconstruction benchmarks. However, there are a few potential limitations and areas for further research that could be considered:
-
Generalization to Complex Geometries: While the results on the evaluated benchmarks are impressive, it would be valuable to assess the method's performance on more challenging and diverse 3D geometries, such as those with intricate details or topological features.
-
Sensitivity to Noise and Outliers: The paper does not extensively discuss the method's robustness to noisy or incomplete point cloud data, which is a common challenge in real-world applications. Further investigation into the method's sensitivity to these factors would be useful.
-
Computational Efficiency at Inference: While the paper demonstrates the efficiency of 3QFP during training, the computational and memory requirements at inference time could also be explored, as this is crucial for practical deployment in real-time applications.
-
Potential Applications and Societal Impact: The paper could further discuss the potential applications of the 3QFP method, such as in 3D scene reconstruction, 3D object modeling, and 3D avatar generation, as well as the societal implications of such technologies.
Overall, the 3QFP method represents an interesting and promising approach to efficient 3D surface reconstruction, with potential applications in various domains. The critical analysis highlights areas for further research and consideration to enhance the method's robustness and real-world applicability.
Conclusion
The 3QFP method, presented in this paper, offers an efficient and high-quality approach to 3D surface reconstruction from point cloud data. By leveraging Tri-Quadtrees and Fourier feature Positional encoding, the method achieves state-of-the-art performance on several benchmarks while requiring significantly less memory and computation than previous methods.
The innovative use of these techniques, along with the thorough evaluation, makes this research a valuable contribution to the field of 3D surface reconstruction. The potential applications of this work span various domains, from 3D scene understanding to 3D content creation, and could have a significant impact on the way we interact with and model the three-dimensional world around us.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
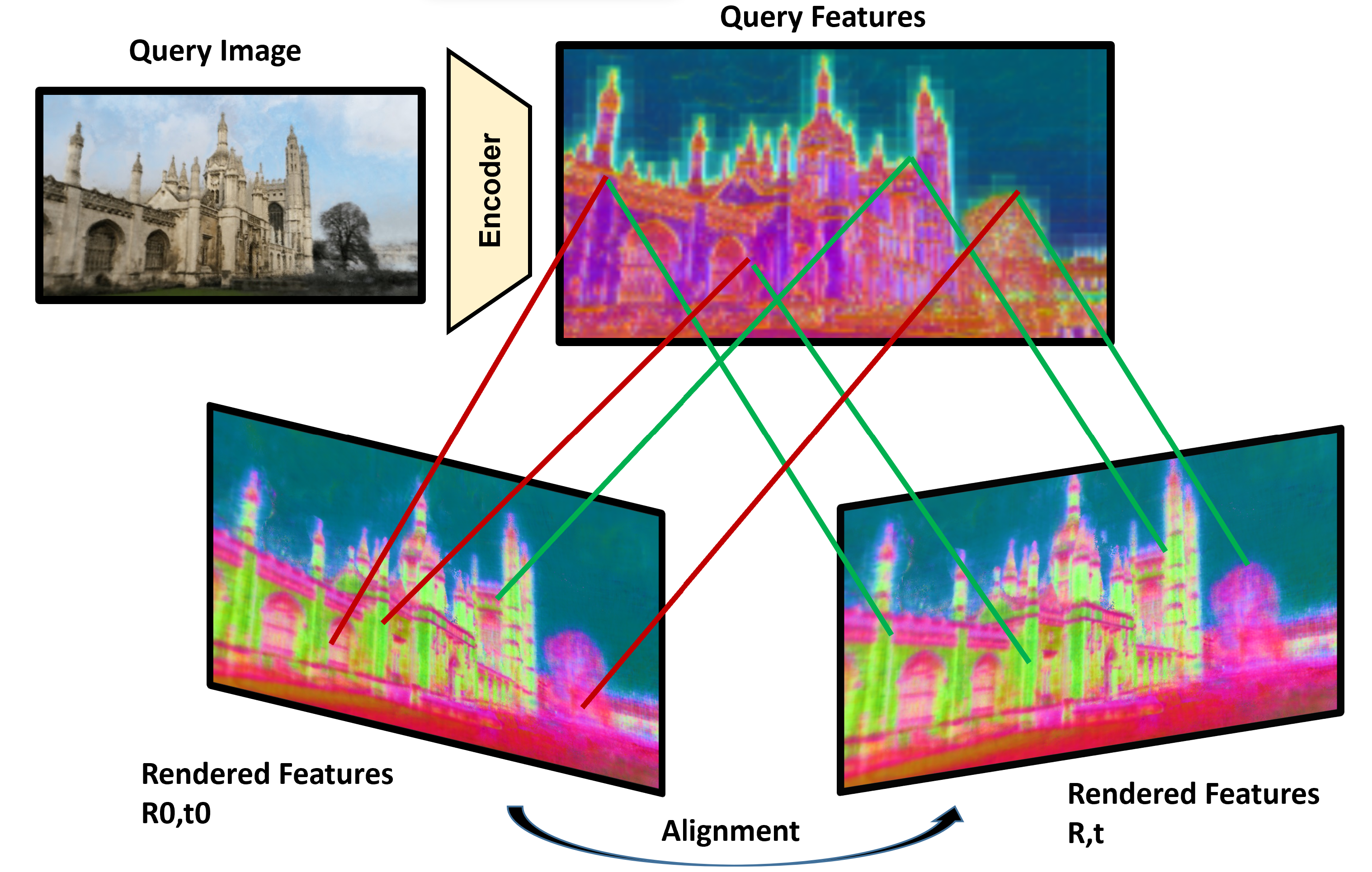
Self-supervised Learning of Neural Implicit Feature Fields for Camera Pose Refinement
Maxime Pietrantoni, Gabriela Csurka, Martin Humenberger, Torsten Sattler
0
0
Visual localization techniques rely upon some underlying scene representation to localize against. These representations can be explicit such as 3D SFM map or implicit, such as a neural network that learns to encode the scene. The former requires sparse feature extractors and matchers to build the scene representation. The latter might lack geometric grounding not capturing the 3D structure of the scene well enough. This paper proposes to jointly learn the scene representation along with a 3D dense feature field and a 2D feature extractor whose outputs are embedded in the same metric space. Through a contrastive framework we align this volumetric field with the image-based extractor and regularize the latter with a ranking loss from learned surface information. We learn the underlying geometry of the scene with an implicit field through volumetric rendering and design our feature field to leverage intermediate geometric information encoded in the implicit field. The resulting features are discriminative and robust to viewpoint change while maintaining rich encoded information. Visual localization is then achieved by aligning the image-based features and the rendered volumetric features. We show the effectiveness of our approach on real-world scenes, demonstrating that our approach outperforms prior and concurrent work on leveraging implicit scene representations for localization.
6/13/2024
S3-SLAM: Sparse Tri-plane Encoding for Neural Implicit SLAM
Zhiyao Zhang, Yunzhou Zhang, Yanmin Wu, Bin Zhao, Xingshuo Wang, Rui Tian
0
0
With the emergence of Neural Radiance Fields (NeRF), neural implicit representations have gained widespread applications across various domains, including simultaneous localization and mapping. However, current neural implicit SLAM faces a challenging trade-off problem between performance and the number of parameters. To address this problem, we propose sparse tri-plane encoding, which efficiently achieves scene reconstruction at resolutions up to 512 using only 2~4% of the commonly used tri-plane parameters (reduced from 100MB to 2~4MB). On this basis, we design S3-SLAM to achieve rapid and high-quality tracking and mapping through sparsifying plane parameters and integrating orthogonal features of tri-plane. Furthermore, we develop hierarchical bundle adjustment to achieve globally consistent geometric structures and reconstruct high-resolution appearance. Experimental results demonstrate that our approach achieves competitive tracking and scene reconstruction with minimal parameters on three datasets. Source code will soon be available.
4/30/2024
Normal-guided Detail-Preserving Neural Implicit Functions for High-Fidelity 3D Surface Reconstruction
Aarya Patel, Hamid Laga, Ojaswa Sharma
0
0
Neural implicit representations have emerged as a powerful paradigm for 3D reconstruction. However, despite their success, existing methods fail to capture fine geometric details and thin structures, especially in scenarios where only sparse RGB views of the objects of interest are available. We hypothesize that current methods for learning neural implicit representations from RGB or RGBD images produce 3D surfaces with missing parts and details because they only rely on 0-order differential properties, i.e. the 3D surface points and their projections, as supervisory signals. Such properties, however, do not capture the local 3D geometry around the points and also ignore the interactions between points. This paper demonstrates that training neural representations with first-order differential properties, i.e. surface normals, leads to highly accurate 3D surface reconstruction even in situations where only as few as two RGB (front and back) images are available. Given multiview RGB images of an object of interest, we first compute the approximate surface normals in the image space using the gradient of the depth maps produced using an off-the-shelf monocular depth estimator such as Depth Anything model. An implicit surface regressor is then trained using a loss function that enforces the first-order differential properties of the regressed surface to match those estimated from Depth Anything. Our extensive experiments on a wide range of real and synthetic datasets show that the proposed method achieves an unprecedented level of reconstruction accuracy even when using as few as two RGB views. The detailed ablation study also demonstrates that normal-based supervision plays a key role in this significant improvement in performance, enabling the 3D reconstruction of intricate geometric details and thin structures that were previously challenging to capture.
6/10/2024
🧠
3D LiDAR Mapping in Dynamic Environments Using a 4D Implicit Neural Representation
Xingguang Zhong, Yue Pan, Cyrill Stachniss, Jens Behley
0
0
Building accurate maps is a key building block to enable reliable localization, planning, and navigation of autonomous vehicles. We propose a novel approach for building accurate maps of dynamic environments utilizing a sequence of LiDAR scans. To this end, we propose encoding the 4D scene into a novel spatio-temporal implicit neural map representation by fitting a time-dependent truncated signed distance function to each point. Using our representation, we extract the static map by filtering the dynamic parts. Our neural representation is based on sparse feature grids, a globally shared decoder, and time-dependent basis functions, which we jointly optimize in an unsupervised fashion. To learn this representation from a sequence of LiDAR scans, we design a simple yet efficient loss function to supervise the map optimization in a piecewise way. We evaluate our approach on various scenes containing moving objects in terms of the reconstruction quality of static maps and the segmentation of dynamic point clouds. The experimental results demonstrate that our method is capable of removing the dynamic part of the input point clouds while reconstructing accurate and complete 3D maps, outperforming several state-of-the-art methods. Codes are available at: https://github.com/PRBonn/4dNDF
5/7/2024