4+3 Phases of Compute-Optimal Neural Scaling Laws

0
🧠
Sign in to get full access
Overview
- The paper introduces a three-parameter solvable neural scaling model that can be used to derive new predictions about the compute-limited, infinite-data scaling law regime.
- The model is trained using one-pass stochastic gradient descent on a mean-squared loss function.
- The paper analyzes the compute-optimal model-parameter-count and identifies several phases in the data-complexity/target-complexity phase-plane.
- The scaling-law exponents in these phases are derived with mathematical proof and numerical evidence.
Plain English Explanation
The researchers have developed a mathematical model that can help us understand how the performance of neural networks changes as we increase the amount of data and computational power used to train them. This solvable neural scaling model has three key parameters: the complexity of the data, the complexity of the target task, and the number of parameters in the neural network.
By training this model using a common machine learning technique called stochastic gradient descent, the researchers were able to derive a representation of the learning curves that becomes more accurate as the neural network gets larger. They then used this model to analyze the "compute-optimal" number of parameters - the sweet spot where adding more parameters provides the biggest performance boost for a given computational budget.
The researchers identified several distinct phases in how neural network performance scales, depending on the relative complexity of the data and the target task. In each of these phases, they were able to mathematically derive the specific scaling laws that describe how performance improves as you increase the computational power.
This work helps unravel the mystery of how neural network performance scales, and provides a solvable model that can be used to make predictions about the most effective way to scale up neural networks for different types of problems.
Technical Explanation
The researchers introduced a neural scaling model with three key parameters: data complexity, target complexity, and model-parameter-count. This model was trained using one-pass stochastic gradient descent on a mean-squared loss function.
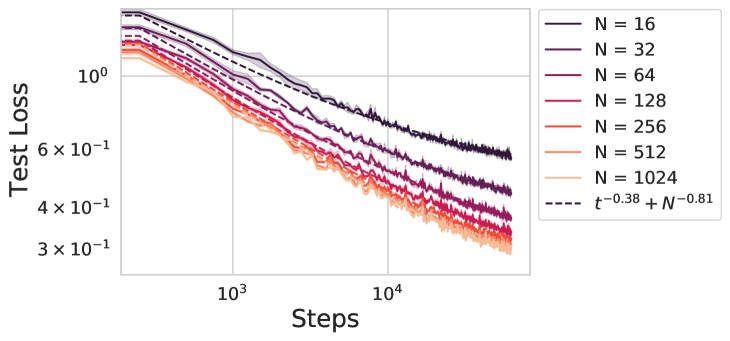
By analyzing the loss curves produced by this model, the researchers were able to derive a representation of the learning dynamics that holds across all iteration counts and improves in accuracy as the model parameter count grows. This allowed them to study the compute-optimal model-parameter-count, which is the sweet spot where adding more parameters provides the biggest performance boost for a given computational budget.
The researchers identified four main phases (plus three sub-phases) in the data-complexity/target-complexity phase-plane, where the optimal model size is determined by the relative importance of model capacity, optimizer noise, and the quality of the feature embeddings. They were able to mathematically derive and numerically validate the scaling-law exponents in each of these phases, providing a comprehensive understanding of how neural network performance scales under different conditions.
Critical Analysis
The neural scaling model introduced in this paper provides a powerful framework for understanding and predicting the performance of neural networks as they scale up in size and computational power. By isolating the key factors that influence scaling behavior, the researchers were able to develop a detailed, solvable model that can make quantitative predictions.
However, it's important to note that this model makes several simplifying assumptions, such as using a mean-squared loss function and one-pass stochastic gradient descent. In practice, real-world neural networks may use more complex loss functions and optimization algorithms that could impact the scaling behavior in ways not captured by this model.
Additionally, the model only considers the scaling of performance with respect to compute and data, and does not account for other important factors like model architecture, initialization, or hyperparameter tuning. Further research would be needed to understand how these elements interact with the scaling laws described in this paper.
Overall, this work represents a significant step forward in our understanding of neural scaling laws, and provides a valuable tool for guiding the future development of large-scale neural networks. However, as with any model, its predictions should be validated against empirical observations and applied with appropriate caution.
Conclusion
The solvable neural scaling model introduced in this paper offers a powerful framework for understanding how the performance of neural networks scales with increases in data and computational power. By identifying key phases in the scaling behavior and deriving the corresponding mathematical scaling laws, the researchers have unraveled a significant mystery in the field of deep learning.
This work has important implications for the design and deployment of large-scale neural networks, as it provides guidance on how to optimize the model size and computational budget to achieve the best performance. Moreover, the solvable model developed in this paper can serve as a valuable tool for further research and exploration in this rapidly evolving field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
0
4+3 Phases of Compute-Optimal Neural Scaling Laws
Elliot Paquette, Courtney Paquette, Lechao Xiao, Jeffrey Pennington
We consider the three parameter solvable neural scaling model introduced by Maloney, Roberts, and Sully. The model has three parameters: data complexity, target complexity, and model-parameter-count. We use this neural scaling model to derive new predictions about the compute-limited, infinite-data scaling law regime. To train the neural scaling model, we run one-pass stochastic gradient descent on a mean-squared loss. We derive a representation of the loss curves which holds over all iteration counts and improves in accuracy as the model parameter count grows. We then analyze the compute-optimal model-parameter-count, and identify 4 phases (+3 subphases) in the data-complexity/target-complexity phase-plane. The phase boundaries are determined by the relative importance of model capacity, optimizer noise, and embedding of the features. We furthermore derive, with mathematical proof and extensive numerical evidence, the scaling-law exponents in all of these phases, in particular computing the optimal model-parameter-count as a function of floating point operation budget.
Read more5/27/2024
0
A Dynamical Model of Neural Scaling Laws
Blake Bordelon, Alexander Atanasov, Cengiz Pehlevan
On a variety of tasks, the performance of neural networks predictably improves with training time, dataset size and model size across many orders of magnitude. This phenomenon is known as a neural scaling law. Of fundamental importance is the compute-optimal scaling law, which reports the performance as a function of units of compute when choosing model sizes optimally. We analyze a random feature model trained with gradient descent as a solvable model of network training and generalization. This reproduces many observations about neural scaling laws. First, our model makes a prediction about why the scaling of performance with training time and with model size have different power law exponents. Consequently, the theory predicts an asymmetric compute-optimal scaling rule where the number of training steps are increased faster than model parameters, consistent with recent empirical observations. Second, it has been observed that early in training, networks converge to their infinite-width dynamics at a rate $1/textit{width}$ but at late time exhibit a rate $textit{width}^{-c}$, where $c$ depends on the structure of the architecture and task. We show that our model exhibits this behavior. Lastly, our theory shows how the gap between training and test loss can gradually build up over time due to repeated reuse of data.
Read more6/26/2024
📈
0
Navigating Scaling Laws: Compute Optimality in Adaptive Model Training
Sotiris Anagnostidis, Gregor Bachmann, Imanol Schlag, Thomas Hofmann
In recent years, the state-of-the-art in deep learning has been dominated by very large models that have been pre-trained on vast amounts of data. The paradigm is very simple: investing more computational resources (optimally) leads to better performance, and even predictably so; neural scaling laws have been derived that accurately forecast the performance of a network for a desired level of compute. This leads to the notion of a `compute-optimal' model, i.e. a model that allocates a given level of compute during training optimally to maximize performance. In this work, we extend the concept of optimality by allowing for an `adaptive' model, i.e. a model that can change its shape during training. By doing so, we can design adaptive models that optimally traverse between the underlying scaling laws and outpace their `static' counterparts, leading to a significant reduction in the required compute to reach a given target performance. We show that our approach generalizes across modalities and different shape parameters.
Read more5/24/2024
🧠
0
Explaining Neural Scaling Laws
Yasaman Bahri, Ethan Dyer, Jared Kaplan, Jaehoon Lee, Utkarsh Sharma
The population loss of trained deep neural networks often follows precise power-law scaling relations with either the size of the training dataset or the number of parameters in the network. We propose a theory that explains the origins of and connects these scaling laws. We identify variance-limited and resolution-limited scaling behavior for both dataset and model size, for a total of four scaling regimes. The variance-limited scaling follows simply from the existence of a well-behaved infinite data or infinite width limit, while the resolution-limited regime can be explained by positing that models are effectively resolving a smooth data manifold. In the large width limit, this can be equivalently obtained from the spectrum of certain kernels, and we present evidence that large width and large dataset resolution-limited scaling exponents are related by a duality. We exhibit all four scaling regimes in the controlled setting of large random feature and pretrained models and test the predictions empirically on a range of standard architectures and datasets. We also observe several empirical relationships between datasets and scaling exponents under modifications of task and architecture aspect ratio. Our work provides a taxonomy for classifying different scaling regimes, underscores that there can be different mechanisms driving improvements in loss, and lends insight into the microscopic origins of and relationships between scaling exponents.
Read more4/30/2024