(Accelerated) Noise-adaptive Stochastic Heavy-Ball Momentum
2401.06738
0
0
📶
Abstract
Stochastic heavy ball momentum (SHB) is commonly used to train machine learning models, and often provides empirical improvements over stochastic gradient descent. By primarily focusing on strongly-convex quadratics, we aim to better understand the theoretical advantage of SHB and subsequently improve the method. For strongly-convex quadratics, Kidambi et al. (2018) show that SHB (with a mini-batch of size $1$) cannot attain accelerated convergence, and hence has no theoretical benefit over SGD. They conjecture that the practical gain of SHB is a by-product of using larger mini-batches. We first substantiate this claim by showing that SHB can attain an accelerated rate when the mini-batch size is larger than a threshold $b^
Create account to get full access
Overview
- This paper examines the use of Stochastic Heavy Ball Momentum (SHB) for training machine learning models, which often provides empirical improvements over Stochastic Gradient Descent (SGD).
- The research focuses on strongly-convex quadratic functions to better understand the theoretical advantages of SHB and ways to improve the method.
- The paper presents several key findings and new algorithmic approaches to enhance the convergence of SHB.
Plain English Explanation
The paper looks at a technique called Stochastic Heavy Ball Momentum (SHB) that is commonly used to train machine learning models. SHB often performs better than a simpler method called Stochastic Gradient Descent (SGD).
The researchers wanted to understand why SHB sometimes works better in practice, so they focused their analysis on a specific type of mathematical function called a strongly-convex quadratic. This allowed them to really dive into the theory and uncover the potential benefits of SHB.
- They showed that SHB can actually achieve faster convergence than SGD, but only if the "batch size" (the number of training examples used at once) is larger than a certain threshold.
- They also developed a new algorithm that adapts to the amount of noise or randomness in the gradients, allowing it to converge more quickly to the optimal solution.
Overall, the paper provides important insights into how to get the most out of this popular momentum-based optimization technique for training machine learning models, especially for certain types of mathematical functions.
Technical Explanation
The paper first examines the case of strongly-convex quadratic functions, where prior work had shown that SHB (with a mini-batch size of 1) cannot achieve accelerated convergence over SGD. The researchers substantiate this claim, but then show that SHB can in fact attain an accelerated rate when the mini-batch size is larger than a threshold b* that depends on the condition number κ.
Specifically, they prove that with the same step-size and momentum parameters as in the deterministic setting, SHB with a sufficiently large mini-batch size results in an O(exp(-T/√κ) + σ) convergence, where T is the number of iterations and σ² is the variance in the stochastic gradients. They also prove a lower-bound that demonstrates the κ dependence in b* is necessary.
To ensure convergence to the minimizer in the strongly-convex case, the authors design a noise-adaptive multi-stage algorithm that achieves an O(exp(-T/√κ) + σ/T) rate. They then consider the general smooth, strongly-convex setting and propose the first noise-adaptive SHB variant that converges to the minimizer at an O(exp(-T/κ) + σ²/T) rate.
The paper also includes empirical demonstrations of the effectiveness of the proposed algorithms.
Critical Analysis
The paper provides a rigorous theoretical analysis of SHB on strongly-convex quadratic functions, clearly delineating the conditions under which SHB can achieve accelerated convergence over SGD. The authors' proof of the necessary κ dependence in the mini-batch size b* is an important technical contribution.
However, the analysis is limited to the strongly-convex quadratic setting, and it remains an open question whether the insights extend to more general function classes. The proposed noise-adaptive algorithms also rely on knowledge of the gradient variance σ², which may not be easily available in practice.
Further research is needed to understand the marginal value of momentum in SGD-based methods, especially in the small learning rate regime. The paper does not provide a comprehensive comparison to other momentum-based techniques, such as Normalized Gradient Descent with Momentum or Random Scaling Momentum, which may offer different tradeoffs.
Conclusion
This paper makes important theoretical contributions to understanding the advantages and limitations of Stochastic Heavy Ball Momentum (SHB) for training machine learning models. The researchers have identified key conditions under which SHB can achieve accelerated convergence, and have proposed new algorithms to improve its performance.
While the analysis is limited to strongly-convex quadratic functions, the insights gained could inform the design of more effective optimization methods for a broader class of machine learning problems. Further empirical and theoretical work is needed to fully understand the practical benefits of SHB and other momentum-based techniques.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Stochastic Polyak Step-sizes and Momentum: Convergence Guarantees and Practical Performance
Dimitris Oikonomou, Nicolas Loizou
0
0
Stochastic gradient descent with momentum, also known as Stochastic Heavy Ball method (SHB), is one of the most popular algorithms for solving large-scale stochastic optimization problems in various machine learning tasks. In practical scenarios, tuning the step-size and momentum parameters of the method is a prohibitively expensive and time-consuming process. In this work, inspired by the recent advantages of stochastic Polyak step-size in the performance of stochastic gradient descent (SGD), we propose and explore new Polyak-type variants suitable for the update rule of the SHB method. In particular, using the Iterate Moving Average (IMA) viewpoint of SHB, we propose and analyze three novel step-size selections: MomSPS$_{max}$, MomDecSPS, and MomAdaSPS. For MomSPS$_{max}$, we provide convergence guarantees for SHB to a neighborhood of the solution for convex and smooth problems (without assuming interpolation). If interpolation is also satisfied, then using MomSPS$_{max}$, SHB converges to the true solution at a fast rate matching the deterministic HB. The other two variants, MomDecSPS and MomAdaSPS, are the first adaptive step-sizes for SHB that guarantee convergence to the exact minimizer without prior knowledge of the problem parameters and without assuming interpolation. The convergence analysis of SHB is tight and obtains the convergence guarantees of SGD with stochastic Polyak step-sizes as a special case. We supplement our analysis with experiments that validate the theory and demonstrate the effectiveness and robustness of the new algorithms.
6/7/2024
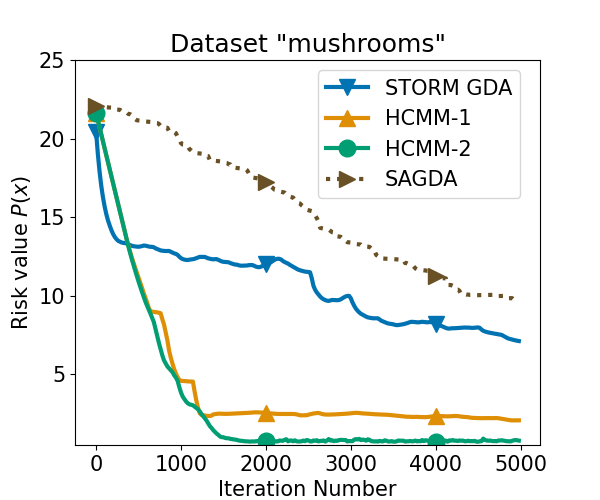
Accelerated Stochastic Min-Max Optimization Based on Bias-corrected Momentum
Haoyuan Cai, Sulaiman A. Alghunaim, Ali H. Sayed
0
0
Lower-bound analyses for nonconvex strongly-concave minimax optimization problems have shown that stochastic first-order algorithms require at least $mathcal{O}(varepsilon^{-4})$ oracle complexity to find an $varepsilon$-stationary point. Some works indicate that this complexity can be improved to $mathcal{O}(varepsilon^{-3})$ when the loss gradient is Lipschitz continuous. The question of achieving enhanced convergence rates under distinct conditions, remains unresolved. In this work, we address this question for optimization problems that are nonconvex in the minimization variable and strongly concave or Polyak-Lojasiewicz (PL) in the maximization variable. We introduce novel bias-corrected momentum algorithms utilizing efficient Hessian-vector products. We establish convergence conditions and demonstrate a lower iteration complexity of $mathcal{O}(varepsilon^{-3})$ for the proposed algorithms. The effectiveness of the method is validated through applications to robust logistic regression using real-world datasets.
6/21/2024
🏋️
Stochastic Normalized Gradient Descent with Momentum for Large-Batch Training
Shen-Yi Zhao, Chang-Wei Shi, Yin-Peng Xie, Wu-Jun Li
0
0
Stochastic gradient descent~(SGD) and its variants have been the dominating optimization methods in machine learning. Compared to SGD with small-batch training, SGD with large-batch training can better utilize the computational power of current multi-core systems such as graphics processing units~(GPUs) and can reduce the number of communication rounds in distributed training settings. Thus, SGD with large-batch training has attracted considerable attention. However, existing empirical results showed that large-batch training typically leads to a drop in generalization accuracy. Hence, how to guarantee the generalization ability in large-batch training becomes a challenging task. In this paper, we propose a simple yet effective method, called stochastic normalized gradient descent with momentum~(SNGM), for large-batch training. We prove that with the same number of gradient computations, SNGM can adopt a larger batch size than momentum SGD~(MSGD), which is one of the most widely used variants of SGD, to converge to an $epsilon$-stationary point. Empirical results on deep learning verify that when adopting the same large batch size, SNGM can achieve better test accuracy than MSGD and other state-of-the-art large-batch training methods.
4/16/2024
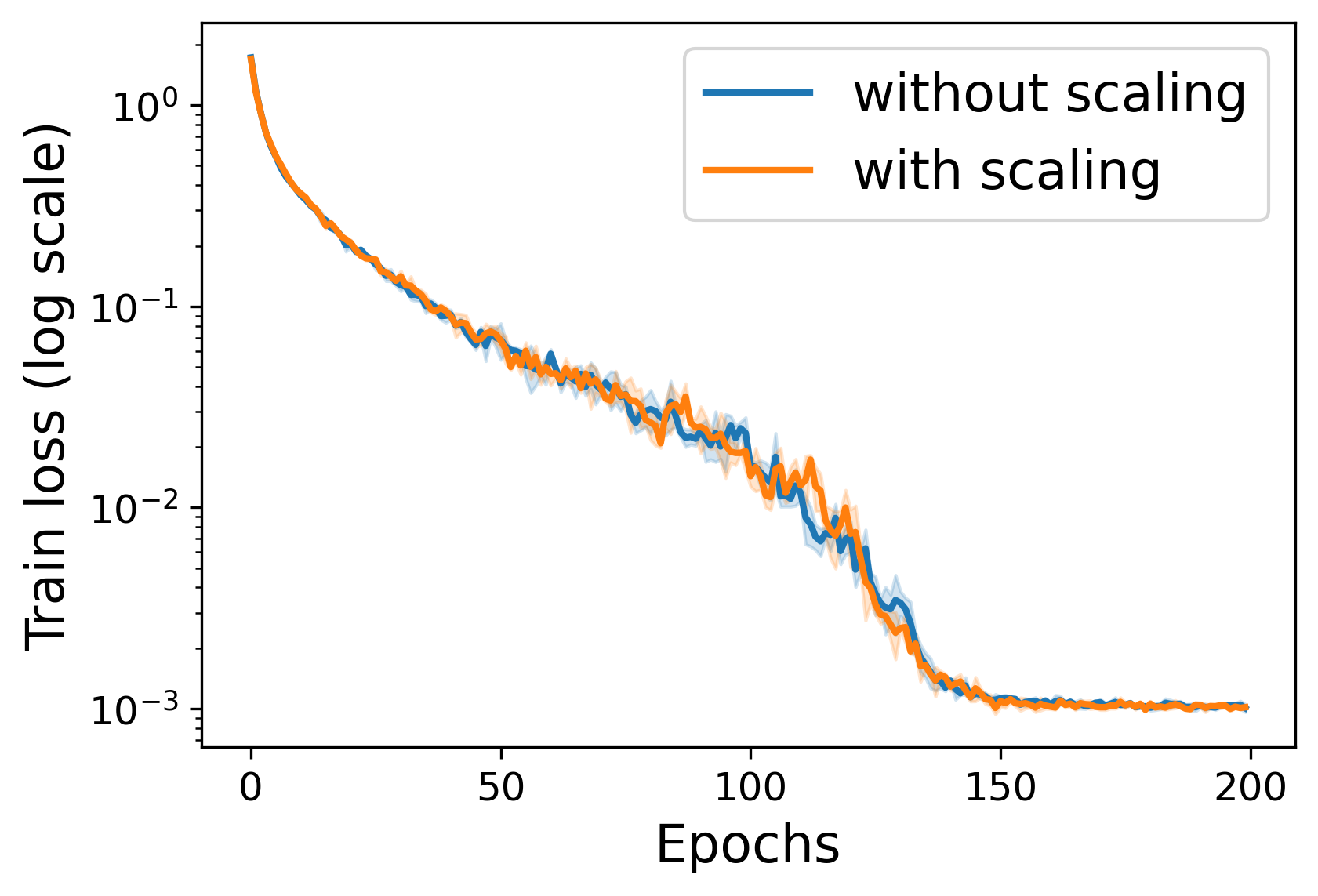
Random Scaling and Momentum for Non-smooth Non-convex Optimization
Qinzi Zhang, Ashok Cutkosky
0
0
Training neural networks requires optimizing a loss function that may be highly irregular, and in particular neither convex nor smooth. Popular training algorithms are based on stochastic gradient descent with momentum (SGDM), for which classical analysis applies only if the loss is either convex or smooth. We show that a very small modification to SGDM closes this gap: simply scale the update at each time point by an exponentially distributed random scalar. The resulting algorithm achieves optimal convergence guarantees. Intriguingly, this result is not derived by a specific analysis of SGDM: instead, it falls naturally out of a more general framework for converting online convex optimization algorithms to non-convex optimization algorithms.
5/17/2024