AccidentBlip2: Accident Detection With Multi-View MotionBlip2

0

Sign in to get full access
Overview
• This paper presents AccidentBlip2, a system for detecting accidents using multiple camera views and motion data. • The key innovation is the use of a "MotionBlip2" module that combines information from different camera perspectives to identify accident events. • The system is designed to be robust and accurate in real-world driving scenarios.
Plain English Explanation
The researchers have developed a system called AccidentBlip2 that can automatically detect car accidents using video footage from multiple cameras. The core of the system is a module called MotionBlip2 that analyzes the motion and movement of vehicles and people in the camera views to identify when an accident has occurred.
By combining information from different camera angles, the MotionBlip2 module is able to get a more complete picture of what is happening on the road. This makes the accident detection more reliable and accurate compared to using a single camera view.
The goal of AccidentBlip2 is to provide a robust and practical system that can be used in real-world driving scenarios to quickly identify accidents as they happen. This could be useful for things like quickly dispatching emergency services or adjusting traffic patterns in response to incidents.
Technical Explanation
The AccidentBlip2 system uses a multi-frame lightweight efficient vision-language model to process video from multiple camera views simultaneously. The key component is the MotionBlip2 module, which combines motion data from the different perspectives to identify accident events.
The MotionBlip2 module leverages a large language model policy adaptation approach to efficiently process the multi-view video streams and detect anomalies indicative of accidents. This allows the system to operate in a computationally efficient manner suitable for real-time deployment.
The researchers evaluated AccidentBlip2 on a large dataset of real-world driving scenarios and found that it was able to accurately detect accident events across a variety of conditions. The use of multiple camera views was shown to significantly improve performance compared to single-view approaches.
Critical Analysis
The paper presents a compelling technical solution for the important problem of automated accident detection. The key strength of the AccidentBlip2 system is its ability to leverage multiple camera views to improve reliability and accuracy, an approach that builds on recent advances in multi-modal vision-language models and world modeling for driving.
That said, the paper does not address certain practical concerns that would need to be considered for real-world deployment. For example, it does not discuss how the system would handle occlusions, poor weather conditions, or cameras that malfunction. Additionally, the ethical implications of automated accident detection, such as privacy concerns and potential misuse, are not explored.
Further research is needed to address these limitations and fully validate the AccidentBlip2 system in diverse real-world driving scenarios. Ongoing work in areas like multi-modal perception for autonomous vehicles may provide useful insights and techniques to build upon.
Conclusion
The AccidentBlip2 system presents a promising approach for improving the reliability and accuracy of automated accident detection using multi-view motion analysis. By leveraging advances in deep learning and multi-modal perception, the researchers have developed a computationally efficient solution that could have significant practical benefits for traffic management and emergency response.
While there are still some challenges to address, the core ideas behind AccidentBlip2 represent an important step forward in the field of intelligent transportation systems. As autonomous and connected vehicle technologies continue to evolve, reliable accident detection will become increasingly crucial for ensuring road safety and optimizing traffic flow.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
AccidentBlip2: Accident Detection With Multi-View MotionBlip2
Yihua Shao, Hongyi Cai, Xinwei Long, Weiyi Lang, Zhe Wang, Haoran Wu, Yan Wang, Jiayi Yin, Yang Yang, Yisheng Lv, Zhen Lei
Intelligent vehicles have demonstrated excellent capabilities in many transportation scenarios. The inference capabilities of neural networks using cameras limit the accuracy of accident detection in complex transportation systems. This paper presents AccidentBlip2, a pure vision-based multi-modal large model Blip2 for accident detection. Our method first processes the multi-view images through ViT-14g and sends the multi-view features into the cross-attention layer of Q-Former. Different from Blip2's Q-Former, our Motion Q-Former extends the self-attention layer with the temporal-attention layer. In the inference process, the queries generated from previous frames are input into Motion Q-Former to aggregate temporal information. Queries are updated with an auto-regressive strategy and are sent to a MLP to detect whether there is an accident in the surrounding environment. Our AccidentBlip2 can be extended to a multi-vehicle cooperative system by deploying Motion Q-Former on each vehicle and simultaneously fusing the generated queries into the MLP for auto-regressive inference. Our approach outperforms existing video large language models in detection accuracy in both single-vehicle and multi-vehicle systems.
Read more5/8/2024
💬
0
Using Multimodal Large Language Models for Automated Detection of Traffic Safety Critical Events
Mohammad Abu Tami, Huthaifa I. Ashqar, Mohammed Elhenawy
Traditional approaches to safety event analysis in autonomous systems have relied on complex machine learning models and extensive datasets for high accuracy and reliability. However, the advent of Multimodal Large Language Models (MLLMs) offers a novel approach by integrating textual, visual, and audio modalities, thereby providing automated analyses of driving videos. Our framework leverages the reasoning power of MLLMs, directing their output through context-specific prompts to ensure accurate, reliable, and actionable insights for hazard detection. By incorporating models like Gemini-Pro-Vision 1.5 and Llava, our methodology aims to automate the safety critical events and mitigate common issues such as hallucinations in MLLM outputs. Preliminary results demonstrate the framework's potential in zero-shot learning and accurate scenario analysis, though further validation on larger datasets is necessary. Furthermore, more investigations are required to explore the performance enhancements of the proposed framework through few-shot learning and fine-tuned models. This research underscores the significance of MLLMs in advancing the analysis of the naturalistic driving videos by improving safety-critical event detecting and understanding the interaction with complex environments.
Read more6/21/2024

0
When, Where, and What? An Novel Benchmark for Accident Anticipation and Localization with Large Language Models
Haicheng Liao, Yongkang Li, Chengyue Wang, Yanchen Guan, KaHou Tam, Chunlin Tian, Li Li, Chengzhong Xu, Zhenning Li
As autonomous driving systems increasingly become part of daily transportation, the ability to accurately anticipate and mitigate potential traffic accidents is paramount. Traditional accident anticipation models primarily utilizing dashcam videos are adept at predicting when an accident may occur but fall short in localizing the incident and identifying involved entities. Addressing this gap, this study introduces a novel framework that integrates Large Language Models (LLMs) to enhance predictive capabilities across multiple dimensions--what, when, and where accidents might occur. We develop an innovative chain-based attention mechanism that dynamically adjusts to prioritize high-risk elements within complex driving scenes. This mechanism is complemented by a three-stage model that processes outputs from smaller models into detailed multimodal inputs for LLMs, thus enabling a more nuanced understanding of traffic dynamics. Empirical validation on the DAD, CCD, and A3D datasets demonstrates superior performance in Average Precision (AP) and Mean Time-To-Accident (mTTA), establishing new benchmarks for accident prediction technology. Our approach not only advances the technological framework for autonomous driving safety but also enhances human-AI interaction, making predictive insights generated by autonomous systems more intuitive and actionable.
Read more7/29/2024
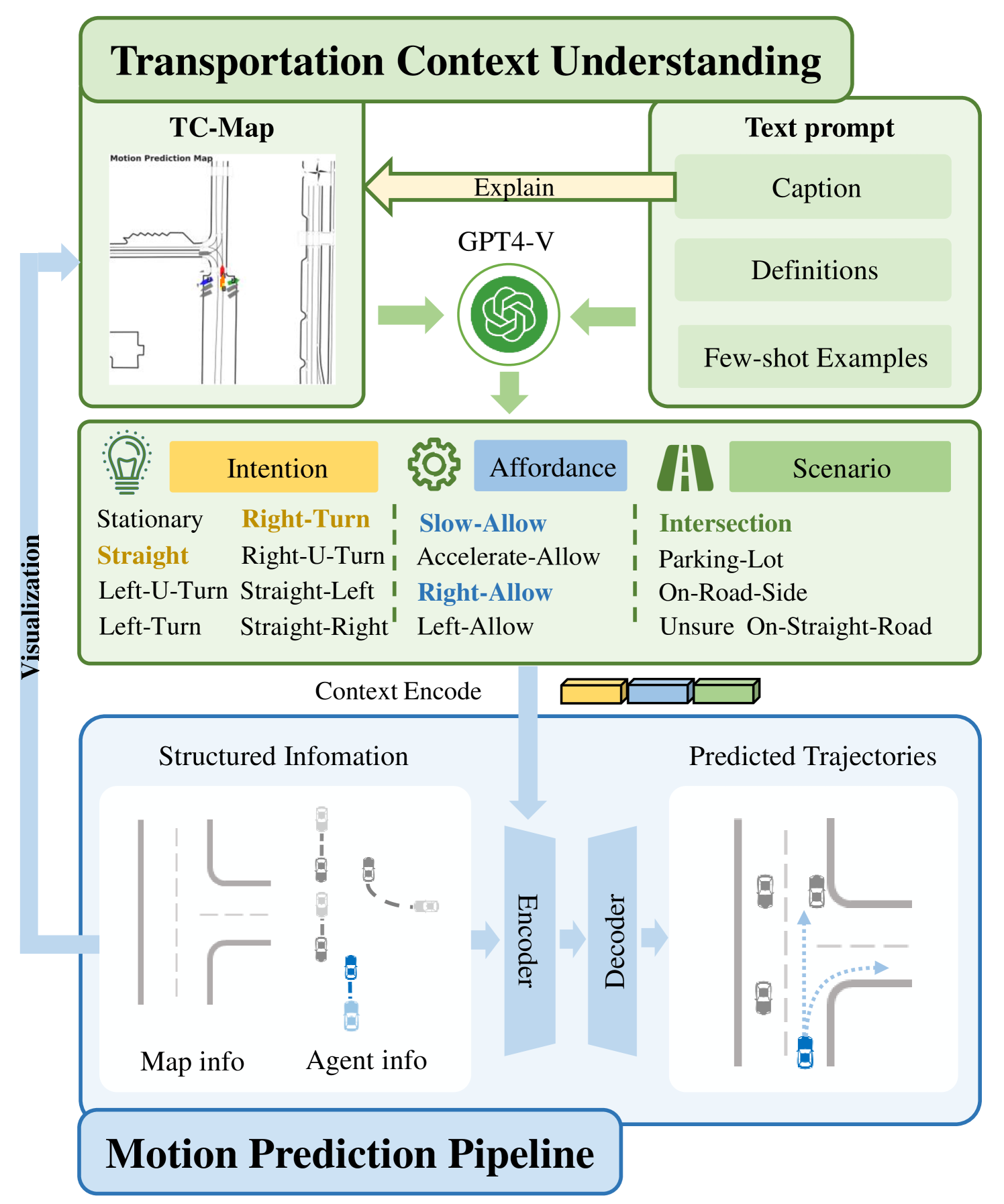
0
Large Language Models Powered Context-aware Motion Prediction
Xiaoji Zheng, Lixiu Wu, Zhijie Yan, Yuanrong Tang, Hao Zhao, Chen Zhong, Bokui Chen, Jiangtao Gong
Motion prediction is among the most fundamental tasks in autonomous driving. Traditional methods of motion forecasting primarily encode vector information of maps and historical trajectory data of traffic participants, lacking a comprehensive understanding of overall traffic semantics, which in turn affects the performance of prediction tasks. In this paper, we utilized Large Language Models (LLMs) to enhance the global traffic context understanding for motion prediction tasks. We first conducted systematic prompt engineering, visualizing complex traffic environments and historical trajectory information of traffic participants into image prompts -- Transportation Context Map (TC-Map), accompanied by corresponding text prompts. Through this approach, we obtained rich traffic context information from the LLM. By integrating this information into the motion prediction model, we demonstrate that such context can enhance the accuracy of motion predictions. Furthermore, considering the cost associated with LLMs, we propose a cost-effective deployment strategy: enhancing the accuracy of motion prediction tasks at scale with 0.7% LLM-augmented datasets. Our research offers valuable insights into enhancing the understanding of traffic scenes of LLMs and the motion prediction performance of autonomous driving. The source code is available at url{https://github.com/AIR-DISCOVER/LLM-Augmented-MTR} and url{https://aistudio.baidu.com/projectdetail/7809548}.
Read more7/31/2024