Using Multimodal Large Language Models for Automated Detection of Traffic Safety Critical Events

0
💬
Sign in to get full access
Overview
- Traditional approaches to safety event analysis in autonomous systems rely on complex machine learning models and extensive datasets
- Multimodal Large Language Models (MLLMs) offer a novel approach by integrating textual, visual, and audio modalities for automated analysis of driving videos
- The proposed framework leverages the reasoning power of MLLMs, using context-specific prompts to provide accurate, reliable, and actionable insights for hazard detection
Plain English Explanation
The paper explores a new way to analyze safety events in autonomous systems, such as self-driving cars. Traditional methods have used complex machine learning models and large datasets to try to achieve high accuracy and reliability. However, the researchers have found that Multimodal Large Language Models (MLLMs) can offer a better approach.
MLLMs can integrate information from different sources, like text, images, and audio, to automatically analyze videos of driving scenarios. The researchers have developed a framework that harnesses the reasoning power of these models, using carefully crafted prompts to ensure the analysis is accurate, reliable, and useful for detecting hazards and safety issues.
By incorporating models like Gemini-Pro-Vision 1.5 and Llava, the researchers aim to automate the process of identifying safety-critical events and address common problems like "hallucinations" (when the model outputs inaccurate information).
The preliminary results look promising, showing that the framework can learn to analyze driving scenarios without any prior training (zero-shot learning) and provide accurate insights. However, more validation on larger datasets is still needed. The researchers also plan to explore ways to further improve the framework's performance, such as through "few-shot learning" (learning from a small number of examples) and fine-tuning the models.
Overall, this research highlights the potential of MLLMs to revolutionize the way we analyze and understand safety-critical events in autonomous systems, which is crucial for improving the safety and reliability of these technologies.
Technical Explanation
The paper presents a novel framework that leverages the power of Multimodal Large Language Models (MLLMs) to automate the analysis of safety-critical events in autonomous driving scenarios. Traditional approaches have relied on complex machine learning models and extensive datasets to achieve high accuracy and reliability, but the researchers argue that MLLMs offer a more promising solution.
The proposed framework integrates textual, visual, and audio modalities to provide automated analyses of driving videos. By harnessing the reasoning capabilities of MLLMs and directing their output through context-specific prompts, the researchers aim to generate accurate, reliable, and actionable insights for hazard detection.
The framework incorporates models like Gemini-Pro-Vision 1.5 and Llava, which the researchers use to automate the identification of safety-critical events and mitigate common issues such as hallucinations in MLLM outputs.
Preliminary results demonstrate the framework's potential in zero-shot learning and accurate scenario analysis, though further validation on larger datasets is necessary. The researchers also plan to explore performance enhancements through few-shot learning and fine-tuned models, as outlined in the AccidentBlip2 and Safety Multimodal Large Language Models papers.
Critical Analysis
While the proposed framework shows promising results, the paper acknowledges the need for further validation on larger datasets to fully assess its capabilities. Additionally, the researchers highlight the importance of exploring performance enhancements through few-shot learning and fine-tuned models, which could help address any limitations in the current approach.
It would also be valuable to understand how the framework handles edge cases or unusual driving scenarios, as well as its ability to generalize to different environments and conditions. Rigorous testing and benchmarking against other state-of-the-art techniques would provide a clearer picture of the framework's strengths and weaknesses.
Furthermore, the potential for hallucinations or other artifacts in the MLLM outputs should be carefully monitored and addressed, as these could lead to inaccurate or unreliable safety analyses. The researchers' efforts to mitigate such issues are commendable, but ongoing vigilance and continuous improvement will be crucial.
Conclusion
This research underscores the significant potential of Multimodal Large Language Models (MLLMs) in advancing the analysis of naturalistic driving videos and improving the detection of safety-critical events. By leveraging the reasoning power of these models and guiding their outputs through context-specific prompts, the proposed framework aims to provide accurate, reliable, and actionable insights for enhancing the safety and reliability of autonomous systems.
The preliminary results are promising, demonstrating the framework's ability to perform zero-shot learning and analyze driving scenarios with a high degree of accuracy. However, further validation on larger datasets, performance enhancements through few-shot learning and fine-tuning, and rigorous testing against other state-of-the-art techniques are necessary to fully realize the framework's potential.
As autonomous systems continue to play an increasingly important role in our daily lives, the significance of this research cannot be overstated. By improving the understanding and mitigation of safety-critical events, the framework can contribute to the development of safer and more reliable autonomous technologies, ultimately benefiting society as a whole.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
Using Multimodal Large Language Models for Automated Detection of Traffic Safety Critical Events
Mohammad Abu Tami, Huthaifa I. Ashqar, Mohammed Elhenawy
Traditional approaches to safety event analysis in autonomous systems have relied on complex machine learning models and extensive datasets for high accuracy and reliability. However, the advent of Multimodal Large Language Models (MLLMs) offers a novel approach by integrating textual, visual, and audio modalities, thereby providing automated analyses of driving videos. Our framework leverages the reasoning power of MLLMs, directing their output through context-specific prompts to ensure accurate, reliable, and actionable insights for hazard detection. By incorporating models like Gemini-Pro-Vision 1.5 and Llava, our methodology aims to automate the safety critical events and mitigate common issues such as hallucinations in MLLM outputs. Preliminary results demonstrate the framework's potential in zero-shot learning and accurate scenario analysis, though further validation on larger datasets is necessary. Furthermore, more investigations are required to explore the performance enhancements of the proposed framework through few-shot learning and fine-tuned models. This research underscores the significance of MLLMs in advancing the analysis of the naturalistic driving videos by improving safety-critical event detecting and understanding the interaction with complex environments.
Read more6/21/2024
0
Probing Multimodal LLMs as World Models for Driving
Shiva Sreeram, Tsun-Hsuan Wang, Alaa Maalouf, Guy Rosman, Sertac Karaman, Daniela Rus
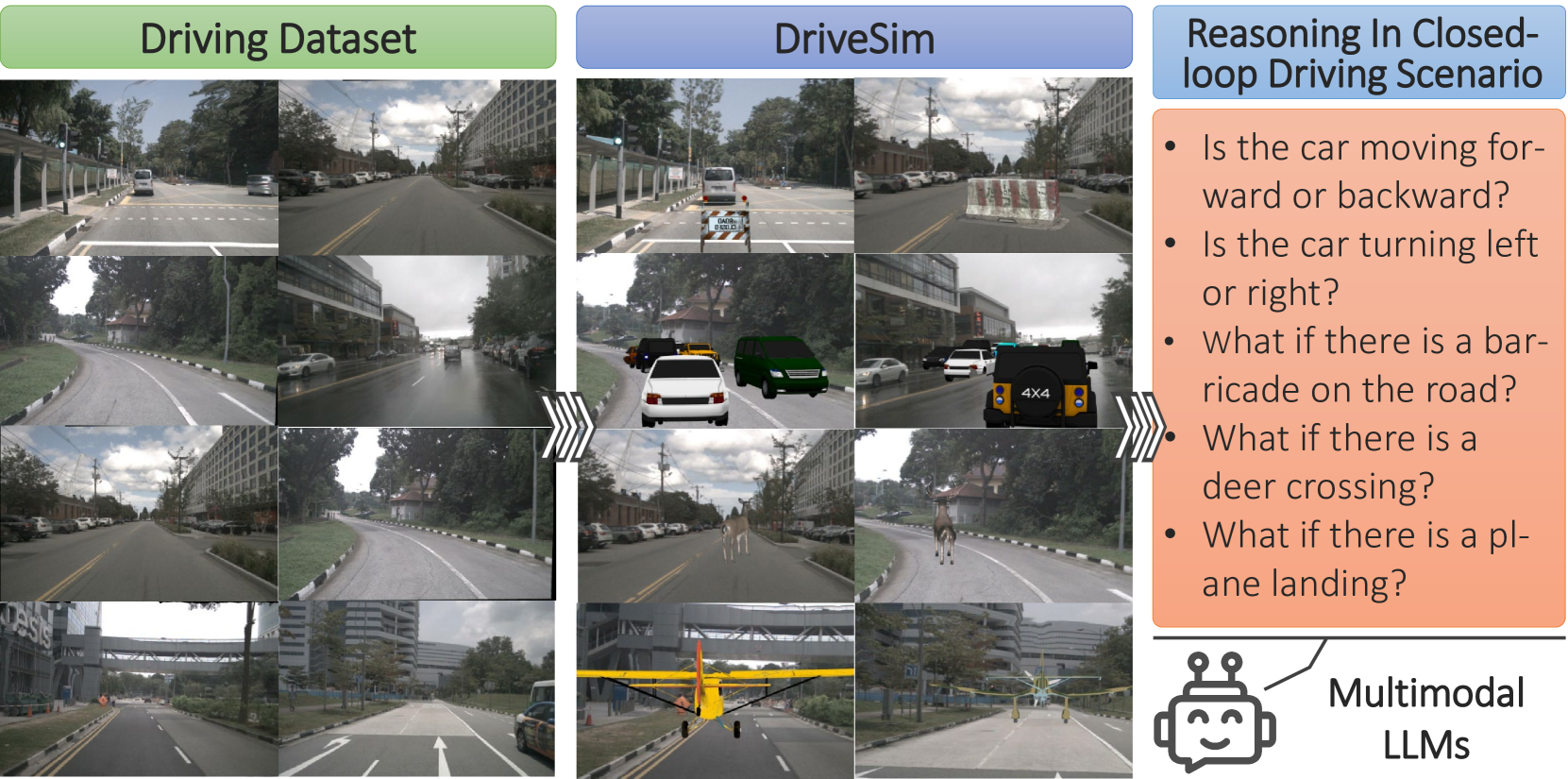
We provide a sober look at the application of Multimodal Large Language Models (MLLMs) within the domain of autonomous driving and challenge/verify some common assumptions, focusing on their ability to reason and interpret dynamic driving scenarios through sequences of images/frames in a closed-loop control environment. Despite the significant advancements in MLLMs like GPT-4V, their performance in complex, dynamic driving environments remains largely untested and presents a wide area of exploration. We conduct a comprehensive experimental study to evaluate the capability of various MLLMs as world models for driving from the perspective of a fixed in-car camera. Our findings reveal that, while these models proficiently interpret individual images, they struggle significantly with synthesizing coherent narratives or logical sequences across frames depicting dynamic behavior. The experiments demonstrate considerable inaccuracies in predicting (i) basic vehicle dynamics (forward/backward, acceleration/deceleration, turning right or left), (ii) interactions with other road actors (e.g., identifying speeding cars or heavy traffic), (iii) trajectory planning, and (iv) open-set dynamic scene reasoning, suggesting biases in the models' training data. To enable this experimental study we introduce a specialized simulator, DriveSim, designed to generate diverse driving scenarios, providing a platform for evaluating MLLMs in the realms of driving. Additionally, we contribute the full open-source code and a new dataset, Eval-LLM-Drive, for evaluating MLLMs in driving. Our results highlight a critical gap in the current capabilities of state-of-the-art MLLMs, underscoring the need for enhanced foundation models to improve their applicability in real-world dynamic environments.
Read more5/10/2024
0
A Superalignment Framework in Autonomous Driving with Large Language Models
Xiangrui Kong, Thomas Braunl, Marco Fahmi, Yue Wang
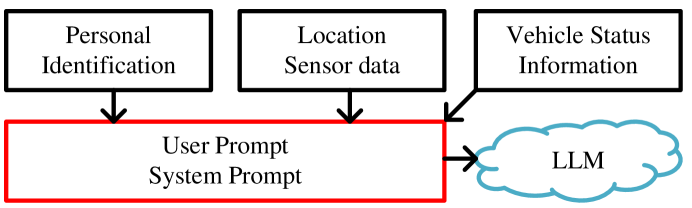
Over the last year, significant advancements have been made in the realms of large language models (LLMs) and multi-modal large language models (MLLMs), particularly in their application to autonomous driving. These models have showcased remarkable abilities in processing and interacting with complex information. In autonomous driving, LLMs and MLLMs are extensively used, requiring access to sensitive vehicle data such as precise locations, images, and road conditions. These data are transmitted to an LLM-based inference cloud for advanced analysis. However, concerns arise regarding data security, as the protection against data and privacy breaches primarily depends on the LLM's inherent security measures, without additional scrutiny or evaluation of the LLM's inference outputs. Despite its importance, the security aspect of LLMs in autonomous driving remains underexplored. Addressing this gap, our research introduces a novel security framework for autonomous vehicles, utilizing a multi-agent LLM approach. This framework is designed to safeguard sensitive information associated with autonomous vehicles from potential leaks, while also ensuring that LLM outputs adhere to driving regulations and align with human values. It includes mechanisms to filter out irrelevant queries and verify the safety and reliability of LLM outputs. Utilizing this framework, we evaluated the security, privacy, and cost aspects of eleven large language model-driven autonomous driving cues. Additionally, we performed QA tests on these driving prompts, which successfully demonstrated the framework's efficacy.
Read more6/11/2024

0
Revolutionizing Urban Safety Perception Assessments: Integrating Multimodal Large Language Models with Street View Images
Jiaxin Zhanga, Yunqin Lia, Tomohiro Fukudab, Bowen Wang
Measuring urban safety perception is an important and complex task that traditionally relies heavily on human resources. This process often involves extensive field surveys, manual data collection, and subjective assessments, which can be time-consuming, costly, and sometimes inconsistent. Street View Images (SVIs), along with deep learning methods, provide a way to realize large-scale urban safety detection. However, achieving this goal often requires extensive human annotation to train safety ranking models, and the architectural differences between cities hinder the transferability of these models. Thus, a fully automated method for conducting safety evaluations is essential. Recent advances in multimodal large language models (MLLMs) have demonstrated powerful reasoning and analytical capabilities. Cutting-edge models, e.g., GPT-4 have shown surprising performance in many tasks. We employed these models for urban safety ranking on a human-annotated anchor set and validated that the results from MLLMs align closely with human perceptions. Additionally, we proposed a method based on the pre-trained Contrastive Language-Image Pre-training (CLIP) feature and K-Nearest Neighbors (K-NN) retrieval to quickly assess the safety index of the entire city. Experimental results show that our method outperforms existing training needed deep learning approaches, achieving efficient and accurate urban safety evaluations. The proposed automation for urban safety perception assessment is a valuable tool for city planners, policymakers, and researchers aiming to improve urban environments.
Read more7/30/2024