Accurate Knowledge Distillation with n-best Reranking
2305.12057
0
0
🔎
Abstract
We propose utilizing n-best reranking to enhance Sequence-Level Knowledge Distillation (Kim and Rush, 2016) where we extract pseudo-labels for student model's training data from top n-best hypotheses and leverage a diverse set of models with different inductive biases, objective functions or architectures, including some publicly-available large language models, to pick the highest-quality hypotheses as labels. The effectiveness of our proposal is validated through experiments on the WMT'21 German-English and Chinese-English translation tasks. Our results demonstrate that utilizing pseudo-labels generated by our n-best reranker leads to a significantly more accurate student model. In fact, our best student model achieves comparable accuracy to a large translation model from (Tran et al., 2021) with 4.7 billion parameters, while having two orders of magnitude fewer parameters.
Create account to get full access
Overview
- The researchers propose using n-best reranking to enhance Sequence-Level Knowledge Distillation (SLKD), a technique to train a smaller "student" model by learning from a larger "teacher" model.
- In their approach, they extract pseudo-labels for the student model's training data from the top n-best hypotheses generated by a diverse set of models, including large language models.
- The goal is to leverage the strengths of multiple models to pick the highest-quality hypotheses as labels, leading to a more accurate student model.
- The effectiveness of this approach is validated through experiments on machine translation tasks.
Plain English Explanation
The researchers have developed a way to train a smaller, more efficient machine learning model by learning from a larger, more complex model. This is a technique called knowledge distillation.
In their approach, they first generate multiple possible translations or "hypotheses" for a given input text using a variety of models, including some very large and powerful language models. They then select the best hypotheses from this set and use them as "pseudo-labels" to train the smaller student model.
The key idea is that by leveraging the strengths of different models, the researchers can identify the highest-quality hypotheses to use as training data for the student model. This helps the student model learn more effectively, allowing it to achieve accuracy comparable to a much larger, more complex model, while being much smaller and more efficient.
The researchers tested their method on machine translation tasks, where the student model was able to perform nearly as well as a much larger model, but with significantly fewer parameters (the building blocks of the model). This suggests that their technique could be a powerful way to create smaller, more efficient AI models without sacrificing too much performance.
Technical Explanation
The researchers propose a novel approach to enhance Sequence-Level Knowledge Distillation (SLKD) (Kim and Rush, 2016). In SLKD, a smaller "student" model is trained to mimic the behavior of a larger "teacher" model.
The key innovation in this work is the use of n-best reranking to generate high-quality pseudo-labels for the student model's training data. Specifically, the researchers extract the top n-best hypotheses from a diverse set of models, including publicly-available large language models and other models with different objective functions or architectures. They then leverage these n-best hypotheses to select the most suitable pseudo-labels for the student model's training.
The effectiveness of this approach is validated through experiments on the WMT'21 German-English and Chinese-English machine translation tasks. The results demonstrate that utilizing the pseudo-labels generated by the n-best reranker leads to a significantly more accurate student model. In fact, the best student model achieved comparable accuracy to a large translation model (Tran et al., 2021) with 4.7 billion parameters, while having two orders of magnitude fewer parameters.
Critical Analysis
The researchers provide a thorough evaluation of their proposed method and acknowledge its limitations. They note that the performance of the student model is still slightly lower than the teacher model, despite the significant reduction in model size.
Additionally, the authors mention that the effectiveness of their approach may depend on the diversity and quality of the models used for n-best reranking. If the models have similar biases or limitations, the pseudo-labels generated may not be sufficiently diverse or accurate.
Further research could explore ways to more systematically select the set of models used for n-best reranking, or investigate alternative techniques for generating high-quality pseudo-labels. Exploring the application of this method to other NLP tasks beyond machine translation would also be valuable.
Overall, the researchers present a promising approach to improve knowledge distillation by leveraging a diverse set of models to generate high-quality pseudo-labels. This work contributes to the ongoing efforts to develop more parameter-efficient and diverse AI models that can achieve strong performance without requiring immense computational resources.
Conclusion
The researchers have developed an innovative technique to enhance Sequence-Level Knowledge Distillation by using n-best reranking to generate high-quality pseudo-labels for training a smaller student model. Their experiments demonstrate that this approach can lead to a student model that achieves comparable accuracy to a much larger teacher model, while being significantly more parameter-efficient.
This work highlights the potential of leveraging the strengths of diverse models to improve the performance of smaller, more efficient AI systems. As the demand for deployable, energy-efficient AI models continues to grow, techniques like the one presented in this paper could play a crucial role in addressing this challenge and advancing the field of zero-shot cross-lingual AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Knowledge Distillation of LLM for Automatic Scoring of Science Education Assessments
Ehsan Latif, Luyang Fang, Ping Ma, Xiaoming Zhai
0
0
This study proposes a method for knowledge distillation (KD) of fine-tuned Large Language Models (LLMs) into smaller, more efficient, and accurate neural networks. We specifically target the challenge of deploying these models on resource-constrained devices. Our methodology involves training the smaller student model (Neural Network) using the prediction probabilities (as soft labels) of the LLM, which serves as a teacher model. This is achieved through a specialized loss function tailored to learn from the LLM's output probabilities, ensuring that the student model closely mimics the teacher's performance. To validate the performance of the KD approach, we utilized a large dataset, 7T, containing 6,684 student-written responses to science questions and three mathematical reasoning datasets with student-written responses graded by human experts. We compared accuracy with state-of-the-art (SOTA) distilled models, TinyBERT, and artificial neural network (ANN) models. Results have shown that the KD approach has 3% and 2% higher scoring accuracy than ANN and TinyBERT, respectively, and comparable accuracy to the teacher model. Furthermore, the student model size is 0.03M, 4,000 times smaller in parameters and x10 faster in inferencing than the teacher model and TinyBERT, respectively. The significance of this research lies in its potential to make advanced AI technologies accessible in typical educational settings, particularly for automatic scoring.
6/13/2024
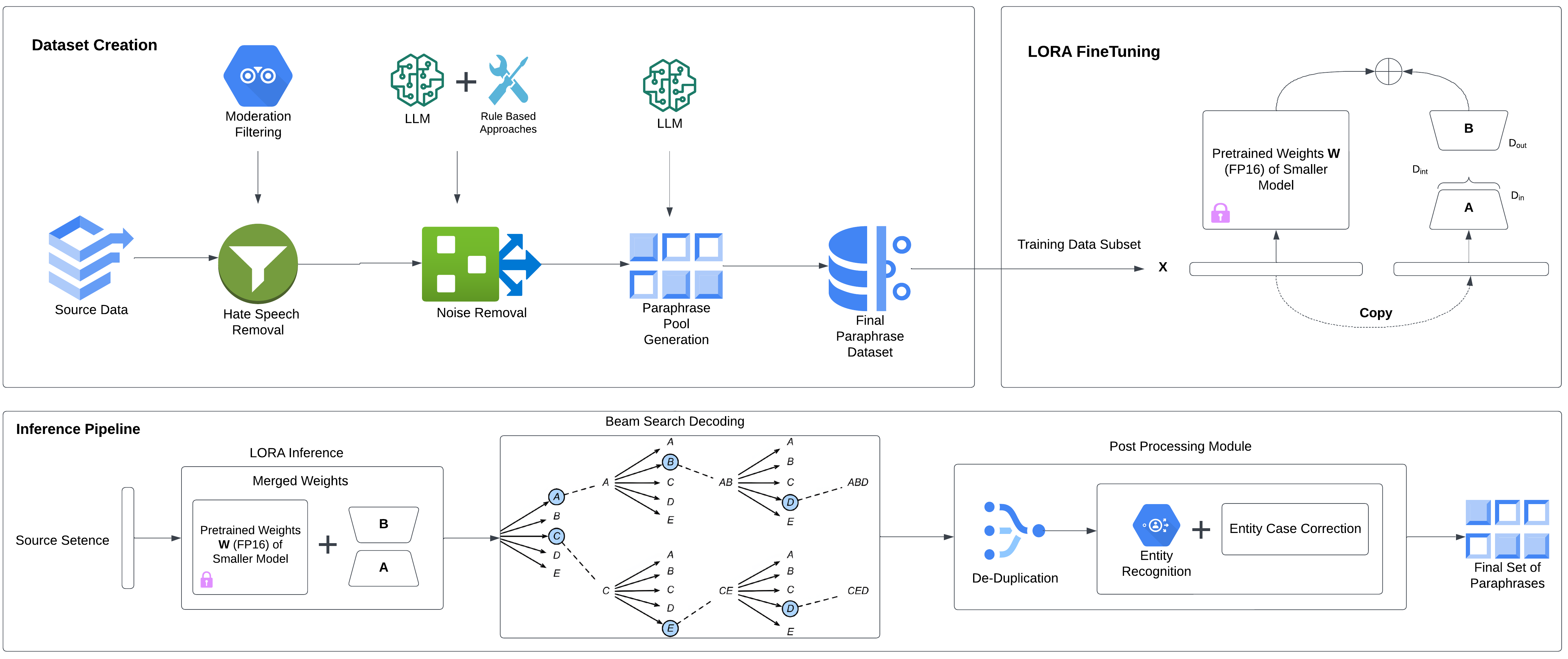
Parameter Efficient Diverse Paraphrase Generation Using Sequence-Level Knowledge Distillation
Lasal Jayawardena, Prasan Yapa
0
0
Over the past year, the field of Natural Language Generation (NLG) has experienced an exponential surge, largely due to the introduction of Large Language Models (LLMs). These models have exhibited the most effective performance in a range of domains within the Natural Language Processing and Generation domains. However, their application in domain-specific tasks, such as paraphrasing, presents significant challenges. The extensive number of parameters makes them difficult to operate on commercial hardware, and they require substantial time for inference, leading to high costs in a production setting. In this study, we tackle these obstacles by employing LLMs to develop three distinct models for the paraphrasing field, applying a method referred to as sequence-level knowledge distillation. These distilled models are capable of maintaining the quality of paraphrases generated by the LLM. They demonstrate faster inference times and the ability to generate diverse paraphrases of comparable quality. A notable characteristic of these models is their ability to exhibit syntactic diversity while also preserving lexical diversity, features previously uncommon due to existing data quality issues in datasets and not typically observed in neural-based approaches. Human evaluation of our models shows that there is only a 4% drop in performance compared to the LLM teacher model used in the distillation process, despite being 1000 times smaller. This research provides a significant contribution to the NLG field, offering a more efficient and cost-effective solution for paraphrasing tasks.
4/22/2024
🧠
Improving Neural Topic Models with Wasserstein Knowledge Distillation
Suman Adhya, Debarshi Kumar Sanyal
0
0
Topic modeling is a dominant method for exploring document collections on the web and in digital libraries. Recent approaches to topic modeling use pretrained contextualized language models and variational autoencoders. However, large neural topic models have a considerable memory footprint. In this paper, we propose a knowledge distillation framework to compress a contextualized topic model without loss in topic quality. In particular, the proposed distillation objective is to minimize the cross-entropy of the soft labels produced by the teacher and the student models, as well as to minimize the squared 2-Wasserstein distance between the latent distributions learned by the two models. Experiments on two publicly available datasets show that the student trained with knowledge distillation achieves topic coherence much higher than that of the original student model, and even surpasses the teacher while containing far fewer parameters than the teacher's. The distilled model also outperforms several other competitive topic models on topic coherence.
6/21/2024
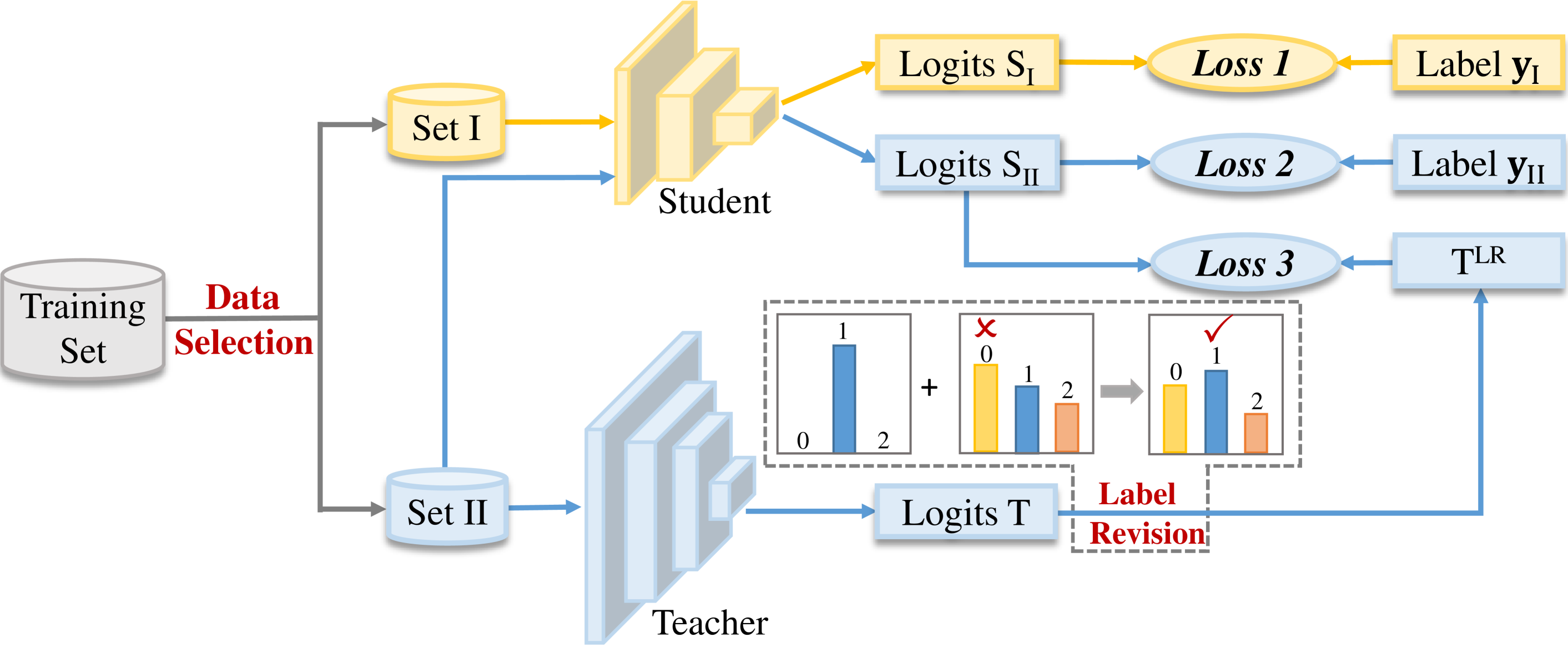
Improve Knowledge Distillation via Label Revision and Data Selection
Weichao Lan, Yiu-ming Cheung, Qing Xu, Buhua Liu, Zhikai Hu, Mengke Li, Zhenghua Chen
0
0
Knowledge distillation (KD) has become a widely used technique in the field of model compression, which aims to transfer knowledge from a large teacher model to a lightweight student model for efficient network development. In addition to the supervision of ground truth, the vanilla KD method regards the predictions of the teacher as soft labels to supervise the training of the student model. Based on vanilla KD, various approaches have been developed to further improve the performance of the student model. However, few of these previous methods have considered the reliability of the supervision from teacher models. Supervision from erroneous predictions may mislead the training of the student model. This paper therefore proposes to tackle this problem from two aspects: Label Revision to rectify the incorrect supervision and Data Selection to select appropriate samples for distillation to reduce the impact of erroneous supervision. In the former, we propose to rectify the teacher's inaccurate predictions using the ground truth. In the latter, we introduce a data selection technique to choose suitable training samples to be supervised by the teacher, thereby reducing the impact of incorrect predictions to some extent. Experiment results demonstrate the effectiveness of our proposed method, and show that our method can be combined with other distillation approaches, improving their performance.
4/8/2024