Acquiring Pronunciation Knowledge from Transcribed Speech Audio via Multi-task Learning

0

Sign in to get full access
Overview
- This paper explores a multi-task learning approach to acquire pronunciation knowledge from transcribed speech audio.
- The work was supported by the UKRI Centre for Doctoral Training in Natural Language Processing.
- Key research areas covered include pronunciation learning, knowledge transfer, multi-task learning, linguistic frontend, and text-to-speech synthesis.
Plain English Explanation
The paper presents a novel way to help machines learn how to pronounce words correctly. Pronunciation learning is an important task in speech technology, allowing systems to speak more naturally.
The researchers used a multi-task learning approach, which means the model was trained on multiple related tasks at the same time. This helps the model transfer knowledge between the tasks, allowing it to learn pronunciation more effectively.
The model was trained on transcribed speech audio, where the text and audio are provided. This linguistic frontend allows the model to learn the connection between written words and how they are pronounced. The goal is to apply this knowledge to improve text-to-speech synthesis.
Technical Explanation
The paper proposes a multi-task learning framework to acquire pronunciation knowledge from transcribed speech audio. The model is trained on two main tasks:
- Phoneme classification: Predicting the sequence of phonemes (basic speech sounds) corresponding to input speech audio.
- Phoneme-to-grapheme alignment: Aligning the predicted phonemes to the characters in the corresponding transcribed text.
By learning these two related tasks simultaneously, the model is able to better capture the relationship between speech audio and pronunciation, enabling more accurate text-to-speech synthesis. The architecture includes a shared encoder network that extracts acoustic features, along with task-specific decoder networks for the two main objectives.
The researchers evaluate their approach on several benchmarks for pronunciation learning and find that it outperforms previous methods, demonstrating the benefits of the multi-task learning strategy.
Critical Analysis
The paper provides a compelling approach to improving pronunciation learning by leveraging multi-task learning. However, the researchers acknowledge several limitations:
- The model is trained and evaluated on high-resource languages (English, Mandarin Chinese) and it's unclear how well the approach would generalize to low-resource languages.
- The experiments focus on read speech, whereas real-world speech often involves more spontaneous, conversational language.
- The paper does not explore the potential negative societal impacts of improved text-to-speech, such as the spread of misinformation or the creation of deepfakes.
Further research could investigate ways to make the model more robust and adaptable to diverse speech contexts, as well as consider the ethical implications of the technology.
Conclusion
This paper presents an innovative multi-task learning framework to enhance pronunciation learning from transcribed speech audio. By jointly learning phoneme classification and phoneme-to-grapheme alignment, the model is able to better capture the connection between written words and their spoken form.
The findings suggest that this approach can lead to more accurate and natural-sounding text-to-speech synthesis, with potential applications in areas like speech recognition, language learning, and assistive technology. However, the researchers highlight the need to address limitations around generalization and ethical considerations as the technology continues to advance.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!Acquiring Pronunciation Knowledge from Transcribed Speech Audio via Multi-task Learning
Siqi Sun, Korin Richmond
Recent work has shown the feasibility and benefit of bootstrapping an integrated sequence-to-sequence (Seq2Seq) linguistic frontend from a traditional pipeline-based frontend for text-to-speech (TTS). To overcome the fixed lexical coverage of bootstrapping training data, previous work has proposed to leverage easily accessible transcribed speech audio as an additional training source for acquiring novel pronunciation knowledge for uncovered words, which relies on an auxiliary ASR model as part of a cumbersome implementation flow. In this work, we propose an alternative method to leverage transcribed speech audio as an additional training source, based on multi-task learning (MTL). Experiments show that, compared to a baseline Seq2Seq frontend, the proposed MTL-based method reduces PER from 2.5% to 1.6% for those word types covered exclusively in transcribed speech audio, achieving a similar performance to the previous method but with a much simpler implementation flow.
Read more9/17/2024
0
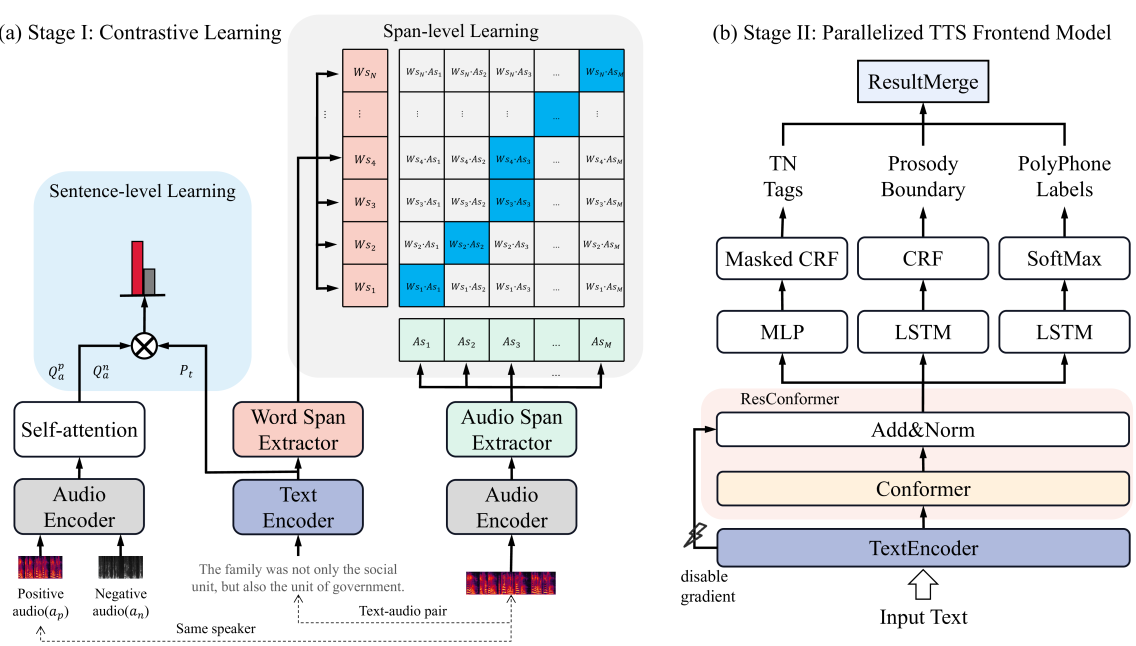
Prior-agnostic Multi-scale Contrastive Text-Audio Pre-training for Parallelized TTS Frontend Modeling
Quanxiu Wang, Hui Huang, Mingjie Wang, Yong Dai, Jinzuomu Zhong, Benlai Tang
Over the past decade, a series of unflagging efforts have been dedicated to developing highly expressive and controllable text-to-speech (TTS) systems. In general, the holistic TTS comprises two interconnected components: the frontend module and the backend module. The frontend excels in capturing linguistic representations from the raw text input, while the backend module converts linguistic cues to speech. The research community has shown growing interest in the study of the frontend component, recognizing its pivotal role in text-to-speech systems, including Text Normalization (TN), Prosody Boundary Prediction (PBP), and Polyphone Disambiguation (PD). Nonetheless, the limitations posed by insufficient annotated textual data and the reliance on homogeneous text signals significantly undermine the effectiveness of its supervised learning. To evade this obstacle, a novel two-stage TTS frontend prediction pipeline, named TAP-FM, is proposed in this paper. Specifically, during the first learning phase, we present a Multi-scale Contrastive Text-audio Pre-training protocol (MC-TAP), which hammers at acquiring richer insights via multi-granularity contrastive pre-training in an unsupervised manner. Instead of mining homogeneous features in prior pre-training approaches, our framework demonstrates the ability to delve deep into both global and local text-audio semantic and acoustic representations. Furthermore, a parallelized TTS frontend model is delicately devised to execute TN, PD, and PBP prediction tasks, respectively in the second stage. Finally, extensive experiments illustrate the superiority of our proposed method, achieving state-of-the-art performance.
Read more4/16/2024

0
A multilingual training strategy for low resource Text to Speech
Asma Amalas, Mounir Ghogho, Mohamed Chetouani, Rachid Oulad Haj Thami
Recent speech technologies have led to produce high quality synthesised speech due to recent advances in neural Text to Speech (TTS). However, such TTS models depend on extensive amounts of data that can be costly to produce and is hardly scalable to all existing languages, especially that seldom attention is given to low resource languages. With techniques such as knowledge transfer, the burden of creating datasets can be alleviated. In this paper, we therefore investigate two aspects; firstly, whether data from social media can be used for a small TTS dataset construction, and secondly whether cross lingual transfer learning (TL) for a low resource language can work with this type of data. In this aspect, we specifically assess to what extent multilingual modeling can be leveraged as an alternative to training on monolingual corporas. To do so, we explore how data from foreign languages may be selected and pooled to train a TTS model for a target low resource language. Our findings show that multilingual pre-training is better than monolingual pre-training at increasing the intelligibility and naturalness of the generated speech.
Read more9/4/2024
0
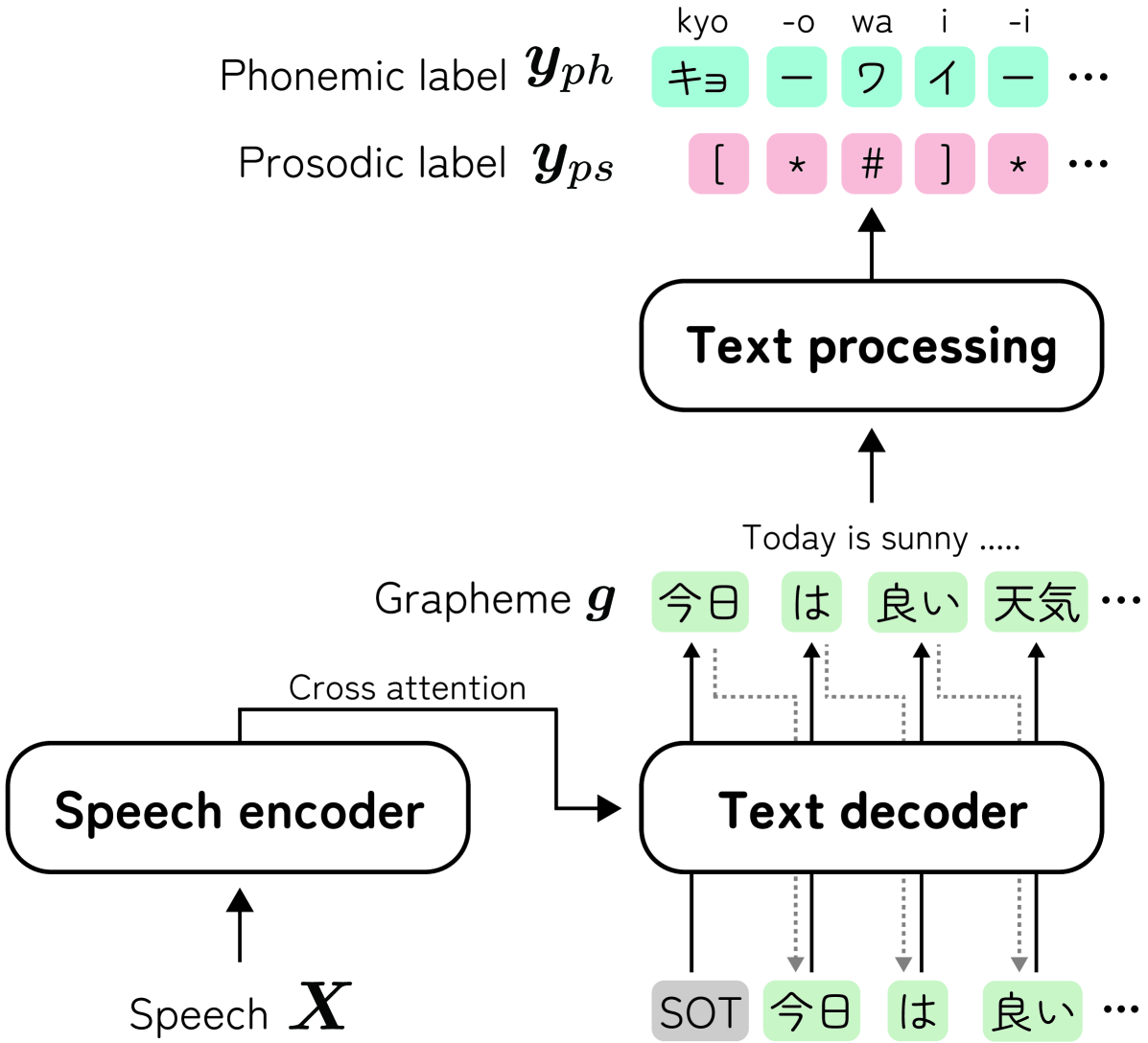
Audio-conditioned phonemic and prosodic annotation for building text-to-speech models from unlabeled speech data
Yuma Shirahata, Byeongseon Park, Ryuichi Yamamoto, Kentaro Tachibana
This paper proposes an audio-conditioned phonemic and prosodic annotation model for building text-to-speech (TTS) datasets from unlabeled speech samples. For creating a TTS dataset that consists of label-speech paired data, the proposed annotation model leverages an automatic speech recognition (ASR) model to obtain phonemic and prosodic labels from unlabeled speech samples. By fine-tuning a large-scale pre-trained ASR model, we can construct the annotation model using a limited amount of label-speech paired data within an existing TTS dataset. To alleviate the shortage of label-speech paired data for training the annotation model, we generate pseudo label-speech paired data using text-only corpora and an auxiliary TTS model. This TTS model is also trained with the existing TTS dataset. Experimental results show that the TTS model trained with the dataset created by the proposed annotation method can synthesize speech as naturally as the one trained with a fully-labeled dataset.
Read more6/13/2024