Actor-Critic Physics-informed Neural Lyapunov Control

0

Sign in to get full access
Overview
- This paper proposes an "Actor-Critic Physics-informed Neural Lyapunov Control" method for controlling dynamic systems.
- The key idea is to use neural networks to learn a Lyapunov function and control policy that stabilize the system.
- The method leverages physical insights about the system to improve sample efficiency and stability of the learned controller.
Plain English Explanation
The paper presents a new way to control the behavior of dynamic systems, like robots or other machines with moving parts. The key challenge is that these systems can be complex, with many interacting components, and it's difficult to design control algorithms that work well.
The proposed method uses neural networks to learn how to control the system. Specifically, it learns two things:
-
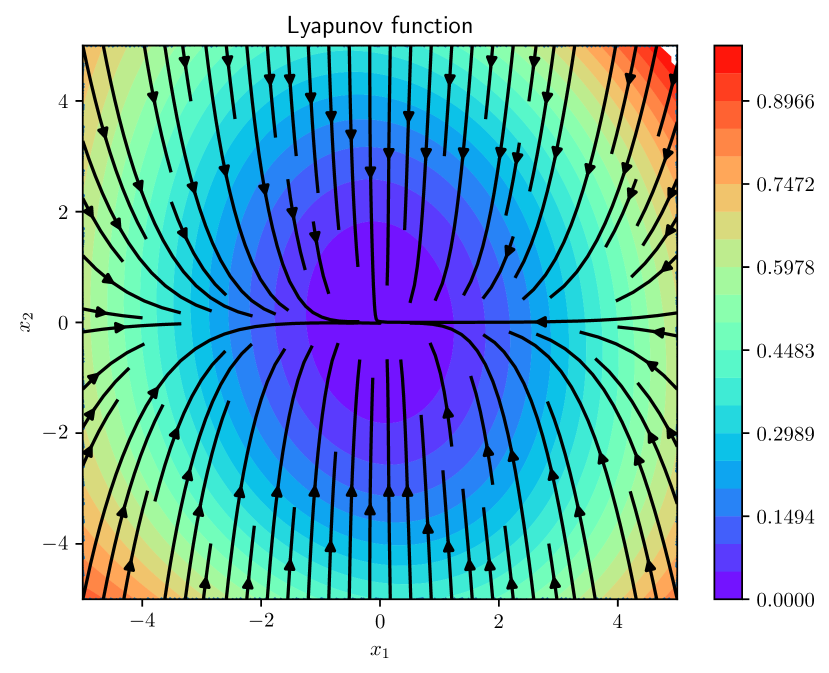
A "Lyapunov function" - this is a mathematical way to describe the stability of the system. If the Lyapunov function is decreasing over time, the system is stable.
-
A control policy - this is how the system should respond to its current state to keep it stable and move towards the desired behavior.
Crucially, the method incorporates physical insights about the system to help the neural networks learn these two components more efficiently and reliably. This makes the overall control approach more robust and effective.
Technical Explanation
The paper presents an "Actor-Critic Physics-informed Neural Lyapunov Control" (AC-PINLC) method for controlling nonlinear dynamic systems. The core idea is to learn a Lyapunov function and a stabilizing control policy using neural networks, while incorporating physical insights about the system dynamics.
The method has three main components:
- A neural network "actor" that represents the control policy, mapping the current state to the desired control action.
- A neural network "critic" that represents the Lyapunov function, estimating the stability of the current state.
- Physical constraints and regularizers that encode known properties of the system dynamics into the neural network training process.
The actor and critic networks are trained simultaneously using reinforcement learning, with the goal of minimizing the Lyapunov function while satisfying the physical constraints. This allows the method to learn stable, high-performance controllers in a data-efficient manner by leveraging the domain knowledge.
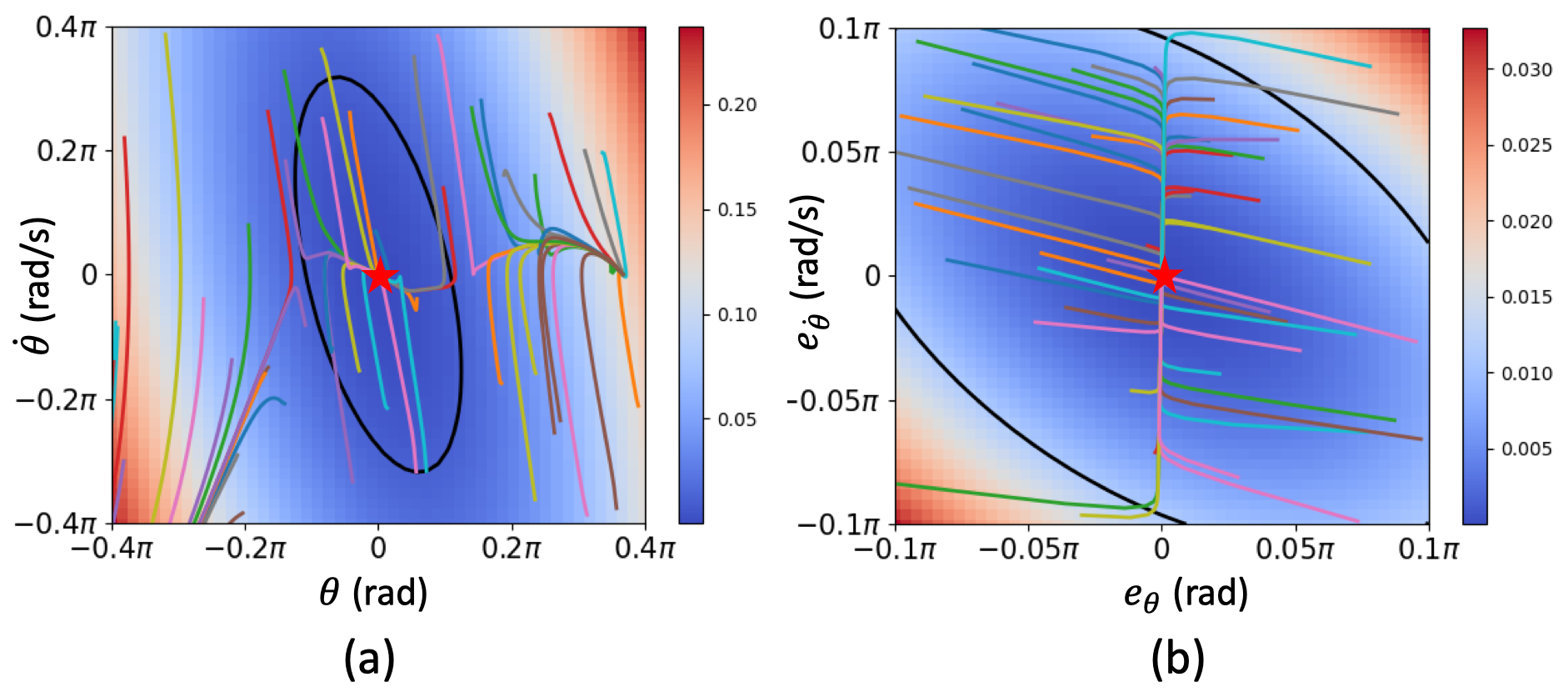
The authors demonstrate the effectiveness of AC-PINLC on several simulated control tasks, including stabilizing pendulums and quadrotors. They show that the method outperforms baseline reinforcement learning and model-based control approaches, particularly in terms of sample efficiency and stability.
Critical Analysis
The paper presents a promising approach for learning stable, high-performance controllers for complex dynamical systems. The key strengths are the incorporation of physical insights, the use of Lyapunov stability theory, and the synergistic training of the actor and critic networks.
However, the paper also has some limitations. The authors only evaluate the method on simulated systems, so further research is needed to assess its performance on real-world hardware. Additionally, the physical constraints and regularizers used in the training process may be challenging to specify for more complex systems, limiting the generality of the approach.
Another potential issue is the reliance on a Lyapunov function, which can be difficult to construct for many systems. Alternative stability certificates, such as control Lyapunov functions, may be a fruitful area for further research.
Overall, the AC-PINLC method represents an interesting and potentially impactful contribution to the field of reinforcement learning for control, particularly in its ability to leverage physical insights to improve sample efficiency and stability. Further research and real-world validation would be valuable to assess the broader applicability of the approach.
Conclusion
This paper introduces an "Actor-Critic Physics-informed Neural Lyapunov Control" method for learning stable, high-performance controllers for dynamic systems. By incorporating physical insights into the neural network training process, the method can learn effective control policies in a data-efficient manner while ensuring Lyapunov stability.
The key contributions of the paper include the synergistic training of actor and critic networks, the use of physical constraints and regularizers, and the demonstration of the method's effectiveness on simulated control tasks. While the approach has some limitations, it represents an interesting and potentially impactful advancement in the field of reinforcement learning for control, with promising implications for a wide range of real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Actor-Critic Physics-informed Neural Lyapunov Control
Jiarui Wang, Mahyar Fazlyab
Designing control policies for stabilization tasks with provable guarantees is a long-standing problem in nonlinear control. A crucial performance metric is the size of the resulting region of attraction, which essentially serves as a robustness margin of the closed-loop system against uncertainties. In this paper, we propose a new method to train a stabilizing neural network controller along with its corresponding Lyapunov certificate, aiming to maximize the resulting region of attraction while respecting the actuation constraints. Crucial to our approach is the use of Zubov's Partial Differential Equation (PDE), which precisely characterizes the true region of attraction of a given control policy. Our framework follows an actor-critic pattern where we alternate between improving the control policy (actor) and learning a Zubov function (critic). Finally, we compute the largest certifiable region of attraction by invoking an SMT solver after the training procedure. Our numerical experiments on several design problems show consistent and significant improvements in the size of the resulting region of attraction.
Read more8/2/2024
0
Learning and Verifying Maximal Taylor-Neural Lyapunov functions
Matthieu Barreau, Nicola Bastianello
We introduce a novel neural network architecture, termed Taylor-neural Lyapunov functions, designed to approximate Lyapunov functions with formal certification. This architecture innovatively encodes local approximations and extends them globally by leveraging neural networks to approximate the residuals. Our method recasts the problem of estimating the largest region of attraction - specifically for maximal Lyapunov functions - into a learning problem, ensuring convergence around the origin through robust control theory. Physics-informed machine learning techniques further refine the estimation of the largest region of attraction. Remarkably, this method is versatile, operating effectively even without simulated data points. We validate the efficacy of our approach by providing numerical certificates of convergence across multiple examples. Our proposed methodology not only competes closely with state-of-the-art approaches, such as sum-of-squares and LyZNet, but also achieves comparable results even in the absence of simulated data. This work represents a significant advancement in control theory, with broad potential applications in the design of stable control systems and beyond.
Read more9/2/2024
0
Lyapunov-stable Neural Control for State and Output Feedback: A Novel Formulation for Efficient Synthesis and Verification
Lujie Yang, Hongkai Dai, Zhouxing Shi, Cho-Jui Hsieh, Russ Tedrake, Huan Zhang
Learning-based neural network (NN) control policies have shown impressive empirical performance in a wide range of tasks in robotics and control. However, formal (Lyapunov) stability guarantees over the region-of-attraction (ROA) for NN controllers with nonlinear dynamical systems are challenging to obtain, and most existing approaches rely on expensive solvers such as sums-of-squares (SOS), mixed-integer programming (MIP), or satisfiability modulo theories (SMT). In this paper, we demonstrate a new framework for learning NN controllers together with Lyapunov certificates using fast empirical falsification and strategic regularizations. We propose a novel formulation that defines a larger verifiable region-of-attraction (ROA) than shown in the literature, and refines the conventional restrictive constraints on Lyapunov derivatives to focus only on certifiable ROAs. The Lyapunov condition is rigorously verified post-hoc using branch-and-bound with scalable linear bound propagation-based NN verification techniques. The approach is efficient and flexible, and the full training and verification procedure is accelerated on GPUs without relying on expensive solvers for SOS, MIP, nor SMT. The flexibility and efficiency of our framework allow us to demonstrate Lyapunov-stable output feedback control with synthesized NN-based controllers and NN-based observers with formal stability guarantees, for the first time in literature. Source code at https://github.com/Verified-Intelligence/Lyapunov_Stable_NN_Controllers
Read more6/6/2024

0
Distributionally Robust Policy and Lyapunov-Certificate Learning
Kehan Long, Jorge Cortes, Nikolay Atanasov
This article presents novel methods for synthesizing distributionally robust stabilizing neural controllers and certificates for control systems under model uncertainty. A key challenge in designing controllers with stability guarantees for uncertain systems is the accurate determination of and adaptation to shifts in model parametric uncertainty during online deployment. We tackle this with a novel distributionally robust formulation of the Lyapunov derivative chance constraint ensuring a monotonic decrease of the Lyapunov certificate. To avoid the computational complexity involved in dealing with the space of probability measures, we identify a sufficient condition in the form of deterministic convex constraints that ensures the Lyapunov derivative constraint is satisfied. We integrate this condition into a loss function for training a neural network-based controller and show that, for the resulting closed-loop system, the global asymptotic stability of its equilibrium can be certified with high confidence, even with Out-of-Distribution (OoD) model uncertainties. To demonstrate the efficacy and efficiency of the proposed methodology, we compare it with an uncertainty-agnostic baseline approach and several reinforcement learning approaches in two control problems in simulation.
Read more8/6/2024